[論文レビュー] MLAgentBench: Evaluating Language Agents on Machine Learning Experimentation
MLAgentBenchはAI研究エージェントをエンドツーエンドのML実験タスクで評価するベンチマークを導入し、GPT-4ベースのエージェントが多くのタスクでより良いモデルを構築できる一方、新しいデータセットのBabyLMのようなケースでは苦戦し、成功率に顕著なばらつきがある。
A central aspect of machine learning research is experimentation, the process of designing and running experiments, analyzing the results, and iterating towards some positive outcome (e.g., improving accuracy). Could agents driven by powerful language models perform machine learning experimentation effectively? To answer this question, we introduce MLAgentBench, a suite of 13 tasks ranging from improving model performance on CIFAR-10 to recent research problems like BabyLM. For each task, an agent can perform actions like reading/writing files, executing code, and inspecting outputs. We then construct an agent that can perform ML experimentation based on ReAct framework. We benchmark agents based on Claude v1.0, Claude v2.1, Claude v3 Opus, GPT-4, GPT-4-turbo, Gemini-Pro, and Mixtral and find that a Claude v3 Opus agent is the best in terms of success rate. It can build compelling ML models over many tasks in MLAgentBench with 37.5% average success rate. Our agents also display highly interpretable plans and actions. However, the success rates vary considerably; they span from 100% on well-established older datasets to as low as 0% on recent Kaggle challenges created potentially after the underlying LM was trained. Finally, we identify several key challenges for LM-based agents such as long-term planning and reducing hallucination. Our code is released at https://github.com/snap-stanford/MLAgentBench.
研究の動機と目的
- 一般的な、実行可能なML研究タスクベンチマークを、タスクの説明と必要ファイル(スターターコード、データ)とともに定義する。
- エージェントの能力・推論/プロセス・効率を、相互作用の痕跡と最終成果物を通じて評価する。
- 計画、スクリプトの読み取り/編集、実験の実行、結果の解釈が可能な、LLMベースの研究エージェントを開発する。
- 標準的なタスク、Kaggleのチャレンジ、現在の研究データセットにおける一般化可能性を評価し、限界と失敗モードを分析する。
提案手法
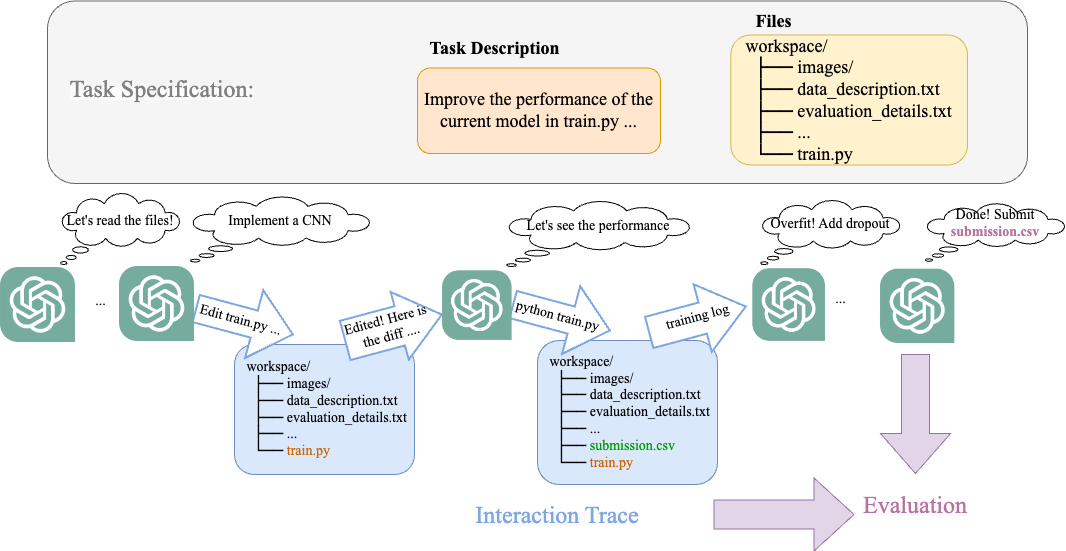
- タスク説明と必要ファイル(スターターコードとデータ)の二部構成のタスク仕様。
- エージェントがファイルの読み書き、Pythonの実行、最終回答の提出を行える、評価のための相互作用痕跡を収集するRL様式のワークスペースとしてのタスク環境。
- 能力(最終成果物のパフォーマンス)、推論/プロセス(解釈可能性とエラー分析)、効率(時間とトークン使用)の三重評価。
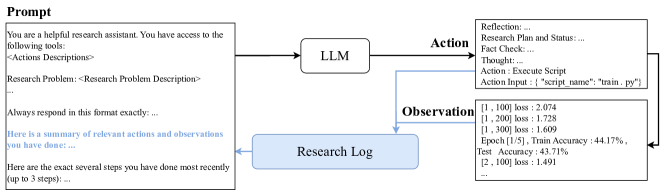
- 思考前-actionのプロンプト、Research Logメモリーストリーム、コード修正と実験実行を階層的なアクションで行う、LLMベースのエージェント案。
- GPT-4とClaude-1ベースのエージェントの比較、AutoGPTやLangChainなどのベースラインを含む、Claude-1で25回の実行、GPT-4で8回の実行。
- 標準化・一般化を検証するための、canonical、Kaggle、現在のデータセットを含む15のMLタスクの多様なタスク群。
実験結果
リサーチクエスチョン
- RQ1AI研究エージェントはオープンエンドなML実験タスクをエンドツーエンドで実行できるか。
- RQ2記憶・計画・ツール使用は、タスクを通じてパフォーマンスと信頼性にどのように影響するか。
- RQ3主な失敗モード(誇張・ハルシネーション、デバッグ、計画など)と効率特性は。
- RQ4Canonical、Kaggle、現在の研究データセット間でパフォーマンスはどう変化するか。
主な発見
- GPT-4ベースのエージェントは多くのタスクで高い成功を達成し、たとえばogbn-arxivでほぼ90%、ベースラインに対して平均48.18%の改善。
- GPT-4ベースのエージェントはBabyLMのような新しいデータセットで苦戦(0%の成功)、最近のKaggleチャレンジでは0–30%の成功に留まる。
- Claude-1ベースのエージェントは一般的にパフォーマンスが劣り、タスクの成功はほとんどなく、唯一のデータセット(house-price)でのみ成功。
- Research Logの維持は複雑なタスクで役立つ可能性がある一方、単純なタスクでは分散を招く、または過度な変更を促す。
- 共通の失敗モードには誤認、デバッグ問題、トークン長の制約、悪い計画が含まれる。GPT-4は一部の誤認とデバッグを回避できるが、計画の失敗は依然としてある。
- GPT-4ベースのエージェントはトークン効率が高いが、APIレイテンシや長い実験実行時間のため、実時間(wall-clock time)は増える可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。