[論文レビュー] MLP-Mixer: An all-MLP Architecture for Vision
MLP-Mixer は、トークン混合とチャネル混合ブロックを備えた、完全にMLPから構成されるアーキテクチャが、畳み込みや自己注意なしで、大規模な事前学習と正則化を前提とする場合、競争力のある画像分類性能を達成できることを示している。
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
研究の動機と目的
- 視覚タスクにおける CNN や Transformer を超えるスケーリング法則とアーキテクチャを動機づける。
- トークン混合(空間的通信)をチャネル混合(特徴通信)から分離する、全MLPアーキテクチャを提案する。
- 大規模な事前学習と正則化の下で、ImageNetおよび転移タスクにおいて、計算コストに対して競争力のある精度を示す。
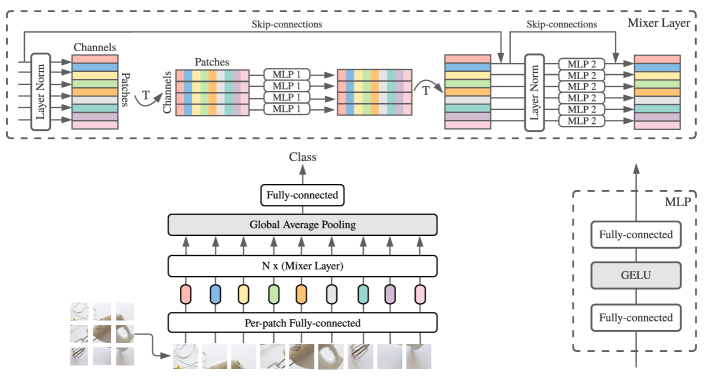
提案手法
- 入力をサイズ S x C のパッチ×チャネルの表 X として表現する。
- Mixer 層ごとに二つの交互のMLPブロックを使用する:列に対して動作するトークン混合MLP(行間で共有)、行に対して動作するチャネル混合MLP(列間で共有)。
- LayerNorm、GELU非線形性、スキップ接続、およびドロップアウトを、標準的なディープネットと同様に適用する。
- 位置エンベディングを避ける;トークン混合MLPの順序感度と、層を通じて固定幅の等方的なアーキテクチャに依存する。
- 大規模データセット(ImageNet-21k、JFT-300M など)で正則化(RandAugment、mixup、ドロップアウト、確率的深さ)を用いて事前学習し、下流タスクでファインチューニングする。
実験結果
リサーチクエスチョン
- RQ1畳み込みや自己注意なしで、MLP だけで構成されたアーキテクチャが視覚タスクで競争力のある精度を達成できるか?
- RQ2MLP-Mixer の性能はモデルサイズと事前学習データ量の増加に伴いどのようにスケールするか?
- RQ3Mixer と CNNs および ViTs の比較における、精度、事前学習コスト、推論時スループットのトレードオフは?
- RQ4モデルの帰納的バイアス(位置ごとのチャネル混合 vs 跨位置トークン混合)が、入力の置換に対するロバスト性とデータ効率にどのように影響するか?
主な発見
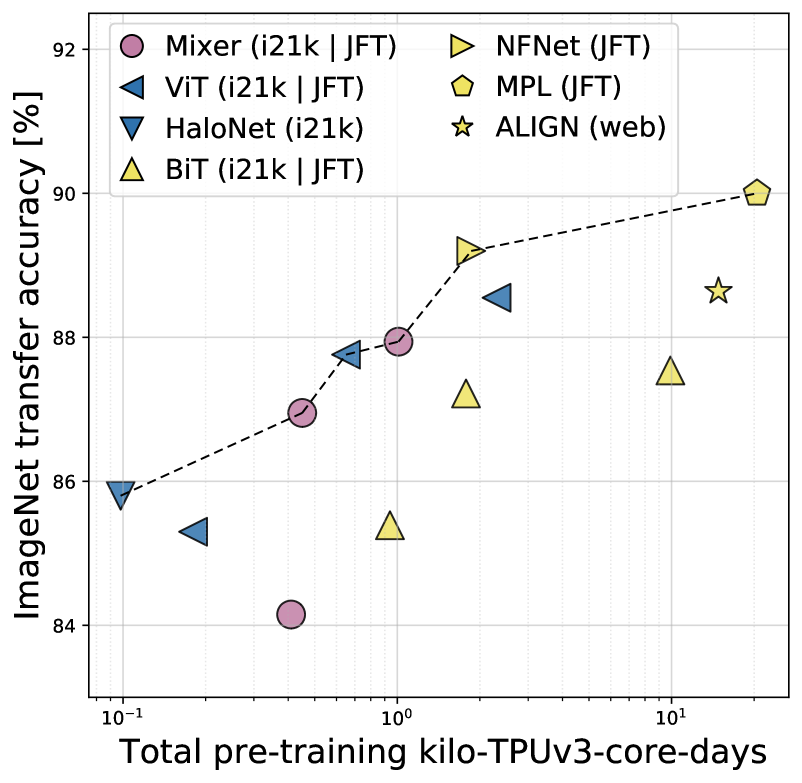
- MLP-Mixer は、大規模データセット(例: ~100M 枚の画像)で事前学習を行い正則化した場合、ImageNet のトップ-1 精度で競争力を持ち、事前学習と推論コストは最新モデルと同程度である。
- このアーキテクチャのトークン混合MLPとチャネル混合MLPは、それぞれ空間的位置とチャネル間で情報交換を可能にし、転移タスクの範囲でCNNsおよびTransformersと同程度の性能を発揮する。
- より大規模な上流データを用いると、Mixer の性能は顕著に向上し、いくつかのCNN/Transformerのベースラインに近づくか、わずかに上回る場合がある一方で、計算コスト/スループットの特性は有利なままである。
- Mixer はパッチの順序置換に対する不変性を示し、グローバルなピクセル置換下でも堅牢な性能を発揮する。これにより、従来の CNN とは異なる帰納的バイアスを強調している。
- 大規模スケールでは、Mixer-H/14 は ImageNet でほぼ ViT-H/14 の性能を達成しつつ、はるかに高速に動作し、精度対計算の前方性を示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。