[論文レビュー] MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
MobileVLM V2 はデータのスケーリング、トレーニング戦略の改善、軽量プロジェクタの導入により、低遅延で多くの大規模VLMよりも高速かつ強力なモバイル指向の vision-language モデルを実現し、最先端の精度を達成します。
We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
研究の動機と目的
- 資源制約のあるデバイス(モバイル/エッジ)で VLM を実用的にする動機付け。
- 小規模な VLM と大規模な VLM のギャップを埋めるためのデータスケーリングとトレーニング戦略を調査する。
- 視覚特徴と言語特徴を効率的に整列させる軽量な投影機構を設計する。
- 公開されている高品質データとエンドツーエンド訓練が小規模 VLM の性能を向上させ得ることを示す。
- 標準ベンチマーク全体でパレート最適な精度とレイテンシのトレードオフを示す。
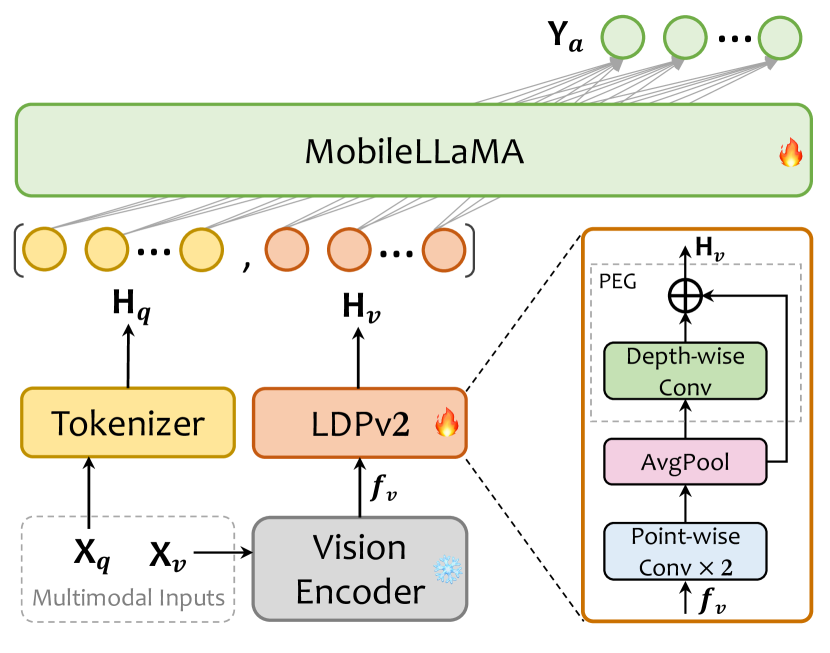
提案手法
- 336x336 の入力解像度で vision encoder として CLIP ViT-L/14 を使用する。
- オープンで効率的な推論のために MobileLLaMA(1.4B/2.7B)を言語モデルとして採用する。
- 位置エンハンスメントを伴うプーリングと単純な畳み込みで画像トークンを削減する軽量ダウンサンプルプロジェクター(LDPv2)を導入する。
- 2 段階で訓練する:事前訓練(完全なプロジェクター+LLM を用いた画像-テキスト整列)とマルチタスク訓練(視覚-言語タスク)。
- ShareGPT4V-PT(1.2M の画像-テキストペア)で事前訓練を行い、さまざまな VLM データセットからの 2.4M サンプルでマルチタスク訓練を実施する。
- 効率とデータ活用性を高めるために視覚エンコーダを凍結したまま、すべてのプロジェクターと LLM のパラメータをファインチューニングする。
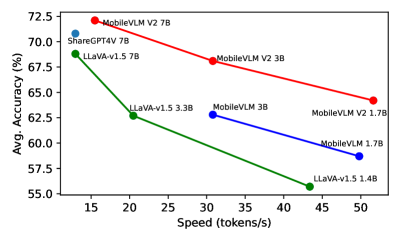
実験結果
リサーチクエスチョン
- RQ1高品質な多模態データセットによるデータスケーリングは、小型 VLM の性能を向上させ、より大きなモデルに匹敵するか?
- RQ2軽量でダウンサンプリングされた視覚投影は、モバイル向けのLLM上で vision と language を効果的につなぐことができるか?
- RQ3高品質データを小型 VLM に最も有効に活用するトレーニング法は何か(事前訓練 vs. マルチタスク)?
- RQ4標準ベンチマーク全体で、MobileVLM V2 の精度とレイテンシは最先端の VLM と比較してどうか?
主な発見
- MobileVLM V2 1.7B は標準ベンチマークで、はるかに大きな VLM と同等かそれ以上の性能を達成する。
- 3B MobileVLM V2 モデルは、平均して多くの 7B+ スケールの VLM よりも優れている。
- MobileVLM V2 はいくつかのベースラインより約75% 速い推論を実現し、平均精度も高い。
- 7B の MobileVLM V2 モデルは、デスクトップ/モバイル風のテスト設定で精度と速度の双方でいくつかの大規模 VLM を上回る。
- 軽量プロジェクターを備えた高度にデータ効率の良いエンドツーエンド訓練レジームは、強力な精度-レイテンシのパレート前線を生み出す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。