[論文レビュー] Model-Ensemble Trust-Region Policy Optimization
ME-TRPO はモデルのアンサンブルと信頼域ポリシー最適化を用いて、モデルベースの深層強化学習における最先端のサンプル効率を達成し、約100倍少ないデータでモデルフリーと同等の性能を実現します。
Model-free reinforcement learning (RL) methods are succeeding in a growing number of tasks, aided by recent advances in deep learning. However, they tend to suffer from high sample complexity, which hinders their use in real-world domains. Alternatively, model-based reinforcement learning promises to reduce sample complexity, but tends to require careful tuning and to date have succeeded mainly in restrictive domains where simple models are sufficient for learning. In this paper, we analyze the behavior of vanilla model-based reinforcement learning methods when deep neural networks are used to learn both the model and the policy, and show that the learned policy tends to exploit regions where insufficient data is available for the model to be learned, causing instability in training. To overcome this issue, we propose to use an ensemble of models to maintain the model uncertainty and regularize the learning process. We further show that the use of likelihood ratio derivatives yields much more stable learning than backpropagation through time. Altogether, our approach Model-Ensemble Trust-Region Policy Optimization (ME-TRPO) significantly reduces the sample complexity compared to model-free deep RL methods on challenging continuous control benchmark tasks.
研究の動機と目的
- 学習済みダイナミクスモデルを活用して、強化学習におけるサンプル複雑さを低減する動機付け。
- モデルとポリシーの両方にニューラルネットワークを用いた場合の、バニラなモデルベース深層RLにおける不安定性を調査する。
- モデルの不確実性を維持し、ポリシー更新を安定化させる堅牢な訓練フレームワークを開発する。
- アンサンブルモデルと TRPO が、難易度の高いタスク全般で安定性と性能を改善することを示す。
提案手法
- 不確実性を捉えるためのニューラルダイナミクス予測器のモデルアンサンブルを導入する。
- 収集した実データで全モデルを訓練し、アンサンブルから架空のロールアウトをサンプリングする。
- ポリシー最適化のために、時間を遡るバックプロパゲーションを尤度比勾配推定量に置換する。
- 想定された軌跡上でポリシー更新を制約するために Trust Region Policy Optimization (TRPO) を使用する。
- すべてのアンサンブルモデルでの性能を監視してポリシー更新の妥当性を検証し、改善が閾値を下回った時点で停止する。
- エンサンブルを洗練させ、ポリシーを再訓練するために、現実環境データを反復的に収集する。
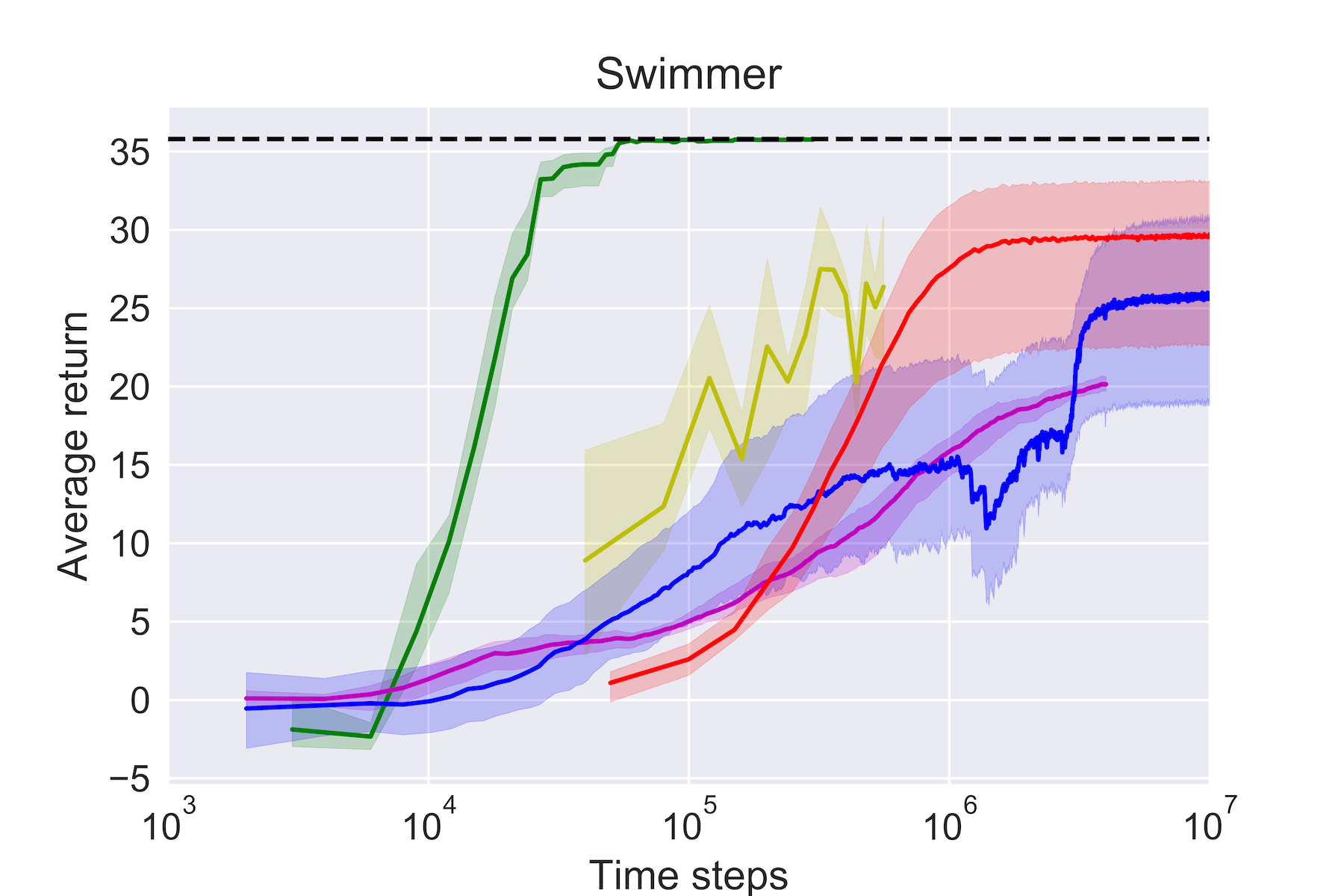
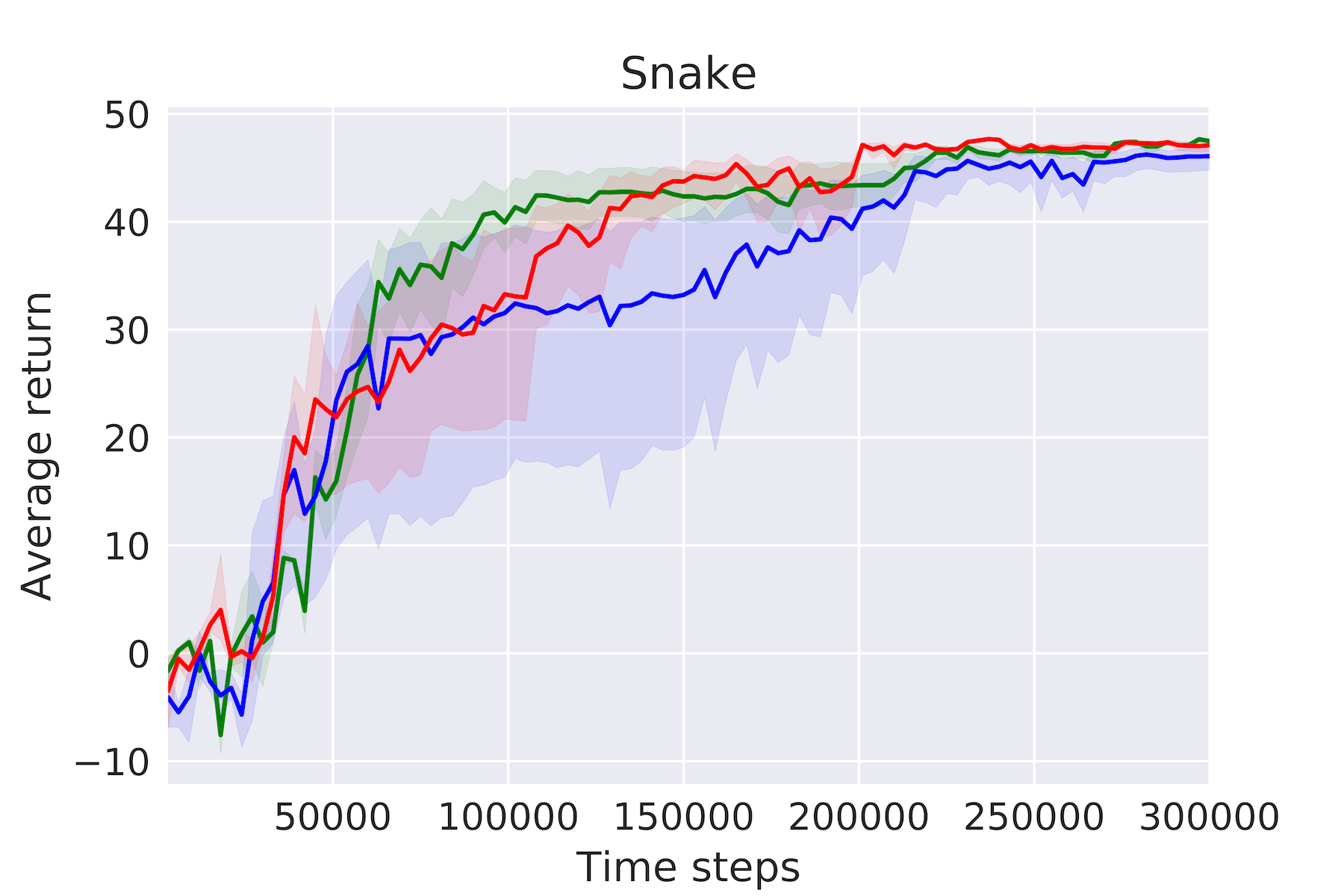
実験結果
リサーチクエスチョン
- RQ1ニューロダイナミクスを用いたモデルベースRLは、最先端のモデルフリー法と比較してサンプル効率と最終性能でどう差があるか?
- RQ2ダイナミクスモデルのアンサンブルはポリシー学習を正規化し、モデルバイアスを緩和できるか?
- RQ3長期的なタスクに対して、BPTTを尤度比勾配推定に置換することで学習を安定化できるか?
- RQ4モデルベースでアンサンブル正規化フレームワークにおける TRPO は、他のポリシー勾配法と比べてどのように機能するか?
主な発見
- 本手法は、約100倍少ない実データでモデルフリーと同等の性能を達成する。
- バニラなモデルベース深層RL は、不安定性とモデルバイアスを、特に長いホライゾンにおいて悪化させる。
- ダイナミクスモデルのアンサンブルを使用することで正規化が得られ、単一モデルへの過適合を低減する。
- BPTT を TRPO に置換することで、より安定した効果的なポリシー学習を実現する。
- アンサンブル中のモデル数を増やすと性能が向上し、特に Half-Cheetah や Ant のような難しいタスクで顕著。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。