[論文レビュー] Model evaluation for extreme risks
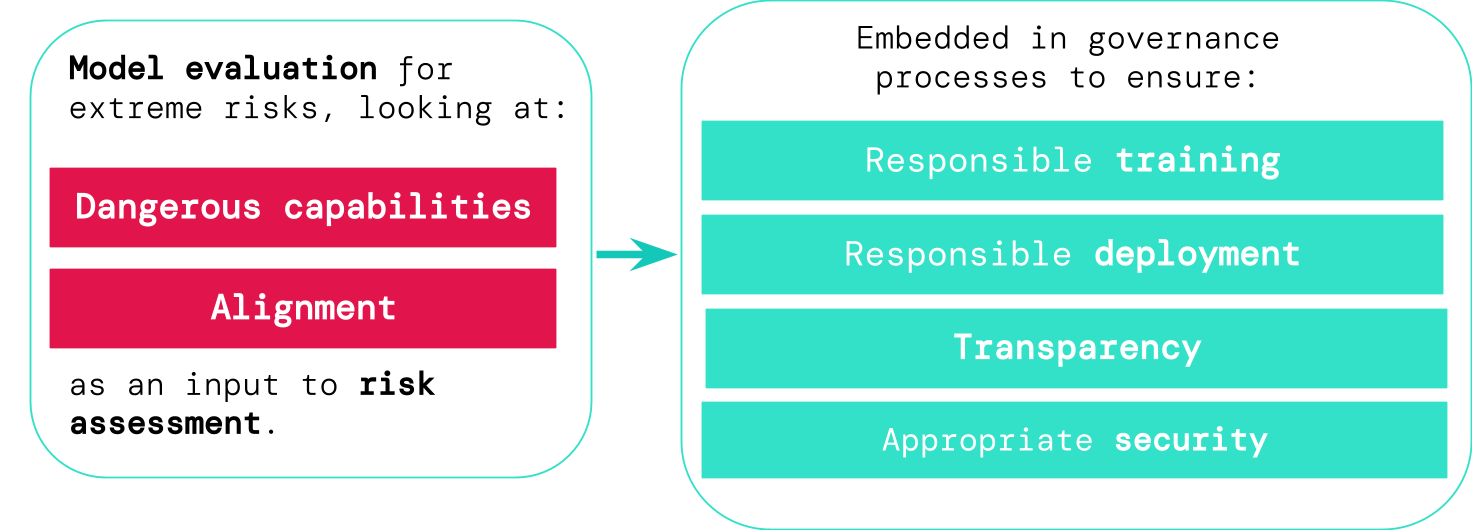
本論文は、汎用モデルから生じる極端なリスクを評価するための二本柱の評価フレームワーク(危険な能力と整合性)を提案し、これらの評価をガバナンス・研修・展開・透明性・セキュリティに組み込む方法を概説している。
Current approaches to building general-purpose AI systems tend to produce systems with both beneficial and harmful capabilities. Further progress in AI development could lead to capabilities that pose extreme risks, such as offensive cyber capabilities or strong manipulation skills. We explain why model evaluation is critical for addressing extreme risks. Developers must be able to identify dangerous capabilities (through "dangerous capability evaluations") and the propensity of models to apply their capabilities for harm (through "alignment evaluations"). These evaluations will become critical for keeping policymakers and other stakeholders informed, and for making responsible decisions about model training, deployment, and security.
研究の動機と目的
- 最前線の汎用AIモデルから生じる極端なリスクへ焦点を当てる動機づけと、危険な能力およびミスアライメントリスクの範囲を定義する。
- 訓練、展開、透明性、セキュリティのプロセスにモデル評価を組み込むガバナンス志向のフレームワークを提案する。
- 初期の取り組み、設計基準、限界を概説し、極端なリスク評価の今後の開発を指針とする。
- 開発者と政策立案者が評価をどのように活用して訓練、展開、リスク緩和を管理すべきかを推奨する。
提案手法
- 二つの核心評価目標を定義する:(a) モデルが有し得る危険な能力を検出する、(b) それらの能力を有害に適用する傾向を評価する(整合性)
- 内部評価、外部研究アクセス、独立監査が訓練リスク評価、展開リスク評価、インシデント報告を導くエンドツーエンドのガバナンス作業フローを説明する。
- 包括性、自動化、行動的・機械的分析、故障探究、潜在的能力の顕在化、ライフサイクルのカバー、解釈可能性を含む極端なリスク評価の設計基準を提示する。
- 評価結果に基づいて訓練/展開を一時停止または調整する責任ある訓練と展開の実践を提唱し、段階的な展開と展開後の監視を行う。
- 透明性の確保メカニズム(インシデント報告、事前展開リスク評価、科学的報告、教育的デモンストレーション)とセキュリティ実践(レッドチーミング、分離、迅速な対応、システム完全性)を強調する。
- 初期の取り組み(ARC Evals、OpenAI、Google DeepMind)を、実践における危険な能力と整合性評価の例として参照する。
実験結果
リサーチクエスチョン
- RQ1最前線の汎用モデルがどのような危険な能力を有し得るか、そしてそれらをいかに信頼性高く検出できるか?
- RQ2さまざまな設定において、モデルが能力を誤用する傾向(整合性)をいかに評価するか?
- RQ3極端なリスク評価を訓練、展開、ガバナンスにいかに統合して極端なリスクの露出を減らすべきか?
- RQ4極端なリスクのモデル評価の限界と危険性は何か、そしてそれらをいかに緩和できるか?
主な発見
- 極端なリスクを評価するために、危険な能力と整合性という2つのカテゴリーから成る評価フレームワークを提案する。
- 評価をリスク評価、訓練、展開、セキュリティ判断に組み込むガバナンス作業フローを概説する。
- 網羅的でない危険な能力の集合を特定し、それらの組み合わせがリスクを高めることを論じる。
- 幅広さ、自動化、故障探査、モデルライフサイクルの考慮など、評価ポートフォリオに求められる望ましい特性を述べる。
- 予期せぬ挙動やモデル更新があるため、展開後の継続的評価とモニタリングを強調する。
- 未知の脅威モデル、出現、情報漏洩リスクなど、評価の限界と潜在的な危険性を認める。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。