[論文レビュー] MoE-Infinity: Efficient MoE Inference on Personal Machines with Sparsity-Aware Expert Cache
MoE-Infinity は、Mixture-of-Experts サービィングのための活性化対応のエキスパートオフロードを導入し、シーケンスレベルのエキスパート活性化トレースを利用してターゲットのプリフェッチとキャッシュを可能にし、待機時間とデプロイコストを削減します。
This paper presents MoE-Infinity, an efficient MoE inference system designed for personal machines with limited GPU memory capacity. The key idea for MoE-Infinity is that on personal machines, which are often single-user environments, MoE-based LLMs typically operate with a batch size of one. In this setting, MoE models exhibit a high degree of activation sparsity, meaning a small number of experts are frequently reused in generating tokens during the decode phase. Leveraging this idea, we design a sparsity-aware expert cache, which can trace the sparse activation of experts during inference and carefully select the trace that represents the sparsity pattern. By analyzing these selected traces, MoE-Infinity guides the replacement and prefetching of the expert cache, providing 3.1-16.7x per-token latency improvements over numerous state-of-the-art systems, including vLLM, Ollama, DeepSpeed and BrainStorm across various MoE models (DeepSeek and Mixtral) when handling different LLM tasks. MoE-Infinity's source code is publicly available at https://github.com/EfficientMoE/MoE-Infinity
研究の動機と目的
- コスト制約のある環境で大規模 MoE モデルのサービィングにおけるメモリとレイテンシコストの削減を動機づける。
- MoE 推論におけるスパースな活性化と時系列局所性を活用する活性化対応型オフロードを提案する。
- エキスパート再利用パターンを特定し活用するためのシーケンスレベルのエキスパート活性化トレース設計。
- オフロード overheads を最小化するための活性化対応プリフェッチングとキャッシュを開発。
- 現実世界の MoE モデルとサービィング workloads に対してシステムを評価し、レイテンシとコストの利点を実証する。
提案手法
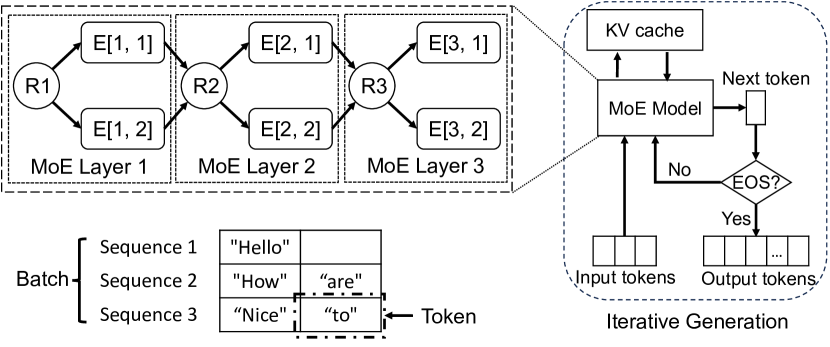
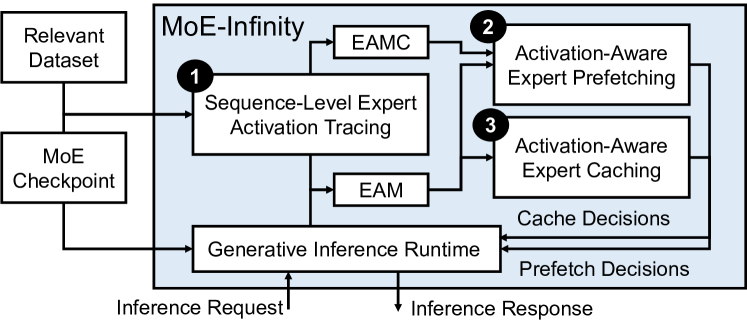
- Expert Activation Matrices (EAMs) を用いたシーケンスレベルのエキスパート活性化トレースを導入し、シーケンスごとの活性化パターンを捉える。
- クラスタリングベースのアプローチで多様な活性化パターンを表現する Expert Activation Matrix Collection (EAMC) を構築する。
- 次に活性化される可能性が高く、現在の実行層の近くにあるエキスパートを優先する活性化対応プリフェッチングを開発する。
- 頻繁に活性化されるエキスパートを優遇するキャッシュ置換ポリシーを備えた、多層 GPU/ホストメモリキャッシュを用いた活性化対応エキスパットキャッシングを実装。
- マルチ-GPUサーバーとエキスパート並列デプロイメントのために、マルチ階層プリフェッチとNUMA対応最適化を統合。
- 実在の MoE チェックポイント(Switch Transformers、NLLB-MoE)を Azure Trace に似たワークロードで評価し、レイテンシとコストの改善を測定する。
実験結果
リサーチクエスチョン
- RQ1シーケンスレベルの活性化トレースは MoE サービィングにおけるオフロード決定をどのように改善できるか。
- RQ2活性化対応プリフェッチングとキャッシュはベースラインと比較してレイテンシとデプロイコストを削減できるか。
- RQ3Online serving における分布シフトへ Expert Activation Matrix Collection はどれくらい適応できるか。
- RQ4マルチ-GPUおよびマルチサーバー展開において、どのハードウェアと実装最適化が性能を最大化するか。
主な発見
- MoE-Infinity は最先端のベースラインに対して 4–20X のレイテンシ削減と 8X を超えるデプロイコスト削減を達成。
- 活性化対応プリフェッチングとキャッシュは MoE オフロードにおける従来のプリフェッチ/キャッシュを大きく上回る。
- EAMs を用いたシーケンスレベルのトレースは、シーケンスごとのパターンが可能にする効果的なリソース配置を可能にする、スパースな活性化と時系列局所性を捉える。
- このアプローチはマルチ-GPUクラスタへ拡張可能で、利用不可のエキスパートに対して SSD オフロードを伴うエキスパート並列サービングをサポートする。
- マイクロベンチマークは DeepSpeed および BrainStorm のプリフェッチング、および SOTA MoE システムで用いられるキャッシュ戦略を上回る改善を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。