[論文レビュー] MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
MoE-LLaVAは三段階のMoE-Tuning戦略と疎なMoEベースのLVLMを導入し、活性化パラメータのごく一部のみを使用して計算量を一定に保つとともに、少数の活性化パラメータのみで競争力のある視覚言語パフォーマンスを実現します。
Recent advances demonstrate that scaling Large Vision-Language Models (LVLMs) effectively improves downstream task performances. However, existing scaling methods enable all model parameters to be active for each token in the calculation, which brings massive training and inferring costs. In this work, we propose a simple yet effective training strategy MoE-Tuning for LVLMs. This strategy innovatively addresses the common issue of performance degradation in multi-modal sparsity learning, consequently constructing a sparse model with an outrageous number of parameters but a constant computational cost. Furthermore, we present the MoE-LLaVA, a MoE-based sparse LVLM architecture, which uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. Extensive experiments show the significant performance of MoE-LLaVA in a variety of visual understanding and object hallucination benchmarks. Remarkably, with only approximately 3B sparsely activated parameters, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmark. Through MoE-LLaVA, we aim to establish a baseline for sparse LVLMs and provide valuable insights for future research in developing more efficient and effective multi-modal learning systems. Code is released at https://github.com/PKU-YuanGroup/MoE-LLaVA.
研究の動機と目的
- 専門家の疎な混成を通じてLVLMの容量を拡張しつつ計算量を削減する動機付け。
- パフォーマンス低下なしでLVLMにMoEを適用するためのMoE-Tuningを提案。
- 推論時に上位k個のエキスパートのみを活性化するMoEベースの疎なLVLMであるMoE-LLaVAを紹介。
提案手法
- Three-stage MoE-Tuning training: Stage I trains an MLP to adapt image tokens to the LLM; Stage II trains the LLM backend for multi-modal understanding; Stage III initializes MoE experts from FFN weights and trains only MoE layers.
- MoE-LLaVA architecture stacks MoE encoder layers with a vision encoder, a visual projection MLP, and a text embedding layer feeding an LLM.
- Hard/router design details: soft routers assign tokens to top-k experts; router weights W map x to expert probabilities via softmax.
- Auxiliary load-balancing loss is used to encourage balanced expert utilization across tokens.
- Auto-regressive loss trains the LLM output on image and text inputs; auxiliary load-balancing loss complements with balancing terms.
実験結果
リサーチクエスチョン
- RQ1疎な MoE LVLM は、活性化パラメータがはるかに少なくても密な LVLM に匹敵する、あるいはそれを上回ることができるのか。
- RQ2三段階の MoE-Tuning ワークフローは訓練を安定化させ、LVLM の効果的なスパース化を可能にするのか。
- RQ3MoE-LLaVA は、画像理解および物体幻視のベンチマークで、密なベースラインと比較してどのように性能を示すのか。
- RQ4マルチモーダル MoE-LLaVA におけるルーティングパターンとエキスパートの負荷はどのようになるのか。
主な発見
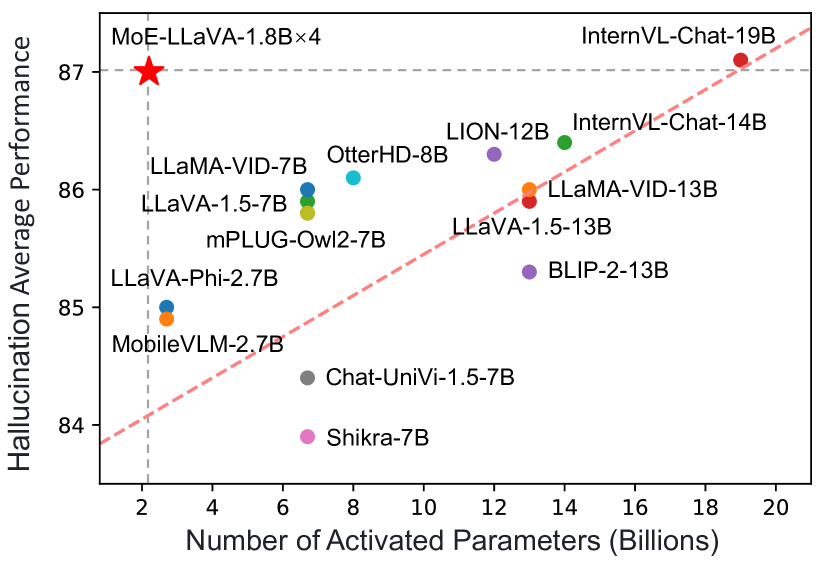
- MoE-LLaVA は約3B活性化パラメータで、視覚理解のベンチマークにおいて LLaVA-1.5-7B と同等の性能を達成。
- MoE-LLaVA は2.2B活性化パラメータで、POPE 物体幻視ベンチマークで LLaVA-1.5-13B を上回ることができる。
- 3.6B活性化パラメータで、MoE-LLaVA は複数のベンチマーク(ScienceQA、POPE、MMBench、LLaVA-W、MM-Vet)で LLaVA-1.5-7B を上回る。
- MoE-LLaVA のルーティングは初期層でエキスパート間にトークンを概ね均等に分配し、モダリティに依存しないルーティング傾向を示し、深層層でエキスパートが特定の作業負荷パターンを発展させる。
- 三段階の訓練戦略は必須であり、指示学習の初期化を適切に行わずにFFNをMoEへ naïve に置換すると性能が下がる。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。