[論文レビュー] MONAS: Multi-Objective Neural Architecture Search using Reinforcement Learning
MONASは強化学習を用いて、精度と電力消費などの他の目的をバランスさせるニューラルネットワークアーキテクチャを探索します。MONAS-Sはスケーラビリティのための重み共有を拡張します。
Recent studies on neural architecture search have shown that automatically designed neural networks perform as good as expert-crafted architectures. While most existing works aim at finding architectures that optimize the prediction accuracy, these architectures may have complexity and is therefore not suitable being deployed on certain computing environment (e.g., with limited power budgets). We propose MONAS, a framework for Multi-Objective Neural Architectural Search that employs reward functions considering both prediction accuracy and other important objectives (e.g., power consumption) when searching for neural network architectures. Experimental results showed that, compared to the state-ofthe-arts, models found by MONAS achieve comparable or better classification accuracy on computer vision applications, while satisfying the additional objectives such as peak power.
研究の動機と目的
- 予測精度と電力消費などのリソース関連目的のバランスを取るための自動ニューラルアーキテクチャ探索を動機づける。
- 強化学習ベースのフレームワークMONASを提案し、探索プロセスに複数の目的を組み込む。
- アプリケーション固有の制約への適応性を示し、MONASをAlexNet風モデルファミリとCondenseNet風モデルファミリに適用する。
- 重み共有を用いたスケーラブル拡張MONAS-Sを導入し、より大規模な探索空間を扱えるようにする。
提案手法
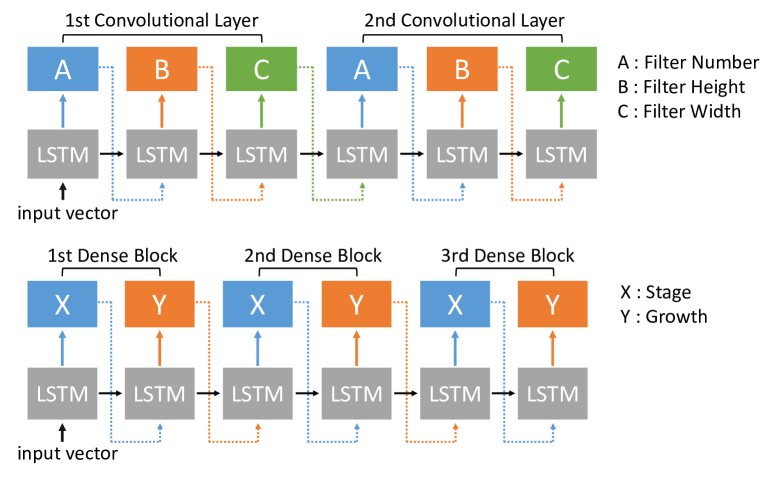
- ターゲットCNNのハイパーパラメータを生成するコントローラとして一層のLSTMベースのロボットネットワーク(RNN)を使用する。
- 生成されたハイパーパラメータでターゲットネットワークを訓練し、検証精度と電力消費をコントローラへの報酬として用いる。
- ポリシー勾配強化学習を適用してコントローラのパラメータを更新し、報酬を精度とエネルギー(または他の制約)を組み合わせて設計する。
- 混合精度とエネルギーのトレードオフや制約ベースの報酬を含む、異なる最適化目標を実現するための複数の報酬関数を定義する。
- MONASをMONAS-Sと拡張し、重み共有探索(DAG)を採用して共有重みを事前学習し、非常に大規模な空間での探索を加速する。
- 報酬はGPUプロファイリング(ピーク/平均電力)とMAC演算から energy および計算コストを推定して測定する。
実験結果
リサーチクエスチョン
- RQ1MONASは異なるマルチオブジェクティブ報酬関数と制約に適応できるか。
- RQ2MONASは電力や精度の制約を満たす領域へ探索をどれだけ効率的に誘導するか。
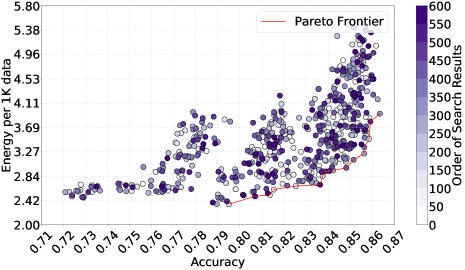
- RQ3パレートフロントは異なる報酬設定下でどう変化するか。
- RQ4MONASはマルチオブジェクティブな目標の下で最先端のベースラインを上回るアーキテクチャを発見できるか。
- RQ5MONAS-Sは非常に大規模な探索空間に対してエネルギー認識の目的を維持しつつ拡張可能か。
主な発見
- MONASは探索を制約を満たすアーキテクチャへ効率的に誘導し、ランダム探索より優れている。
- 混合報酬のα設定は探索を高精度または低エネルギーへ導き、コントローラ可能なトレードオフを示す。
- MONASはパレートフロンティア上のアーキテクチャを発見し、CondenseNetベースラインより精度とエネルギー効率で上回ることがある。
- MONAS-Sは非常に大規模な探索空間(例えば1.6e29の可能性)にスケールし、MAC演算を抑えつつ精度を維持する方向に偏る。
- ENASと比較して、MONAS-SはターゲットネットワークのMAC演算を抑え、層ごとの演算分布が有利になる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。