[論文レビュー] MONet: Unsupervised Scene Decomposition and Representation
MONet は教師なしのモデルで、再帰的アテンションネットワークと共有 VAE を用いてシーンをオブジェクトのようなコンポーネントに分解し、分離表現を学習し、3Dおよび2Dデータセットを跨いでオクルージョンを処理します。
The ability to decompose scenes in terms of abstract building blocks is crucial for general intelligence. Where those basic building blocks share meaningful properties, interactions and other regularities across scenes, such decompositions can simplify reasoning and facilitate imagination of novel scenarios. In particular, representing perceptual observations in terms of entities should improve data efficiency and transfer performance on a wide range of tasks. Thus we need models capable of discovering useful decompositions of scenes by identifying units with such regularities and representing them in a common format. To address this problem, we have developed the Multi-Object Network (MONet). In this model, a VAE is trained end-to-end together with a recurrent attention network -- in a purely unsupervised manner -- to provide attention masks around, and reconstructions of, regions of images. We show that this model is capable of learning to decompose and represent challenging 3D scenes into semantically meaningful components, such as objects and background elements.
研究の動機と目的
- シーン表現を分解可能なオブジェクトとして学習し、推論能力とデータ効率を改善する動機づけ。
- 共通潜在空間を持つ複数のコンポーネントにシーンをセグメントする教師なしアーキテクチャを開発する。
- ラベル付きセグメンテーションを必要とせず、オクルージョンと可変オブジェクト数に対応できるようにする。
- より多い/少ないオブジェクトや新規構成のシーンへ一般化を示す。
- 学習されたコンポーネントが分離可能で解釈可能な潜在因子を生み出すことを示す。
提案手法
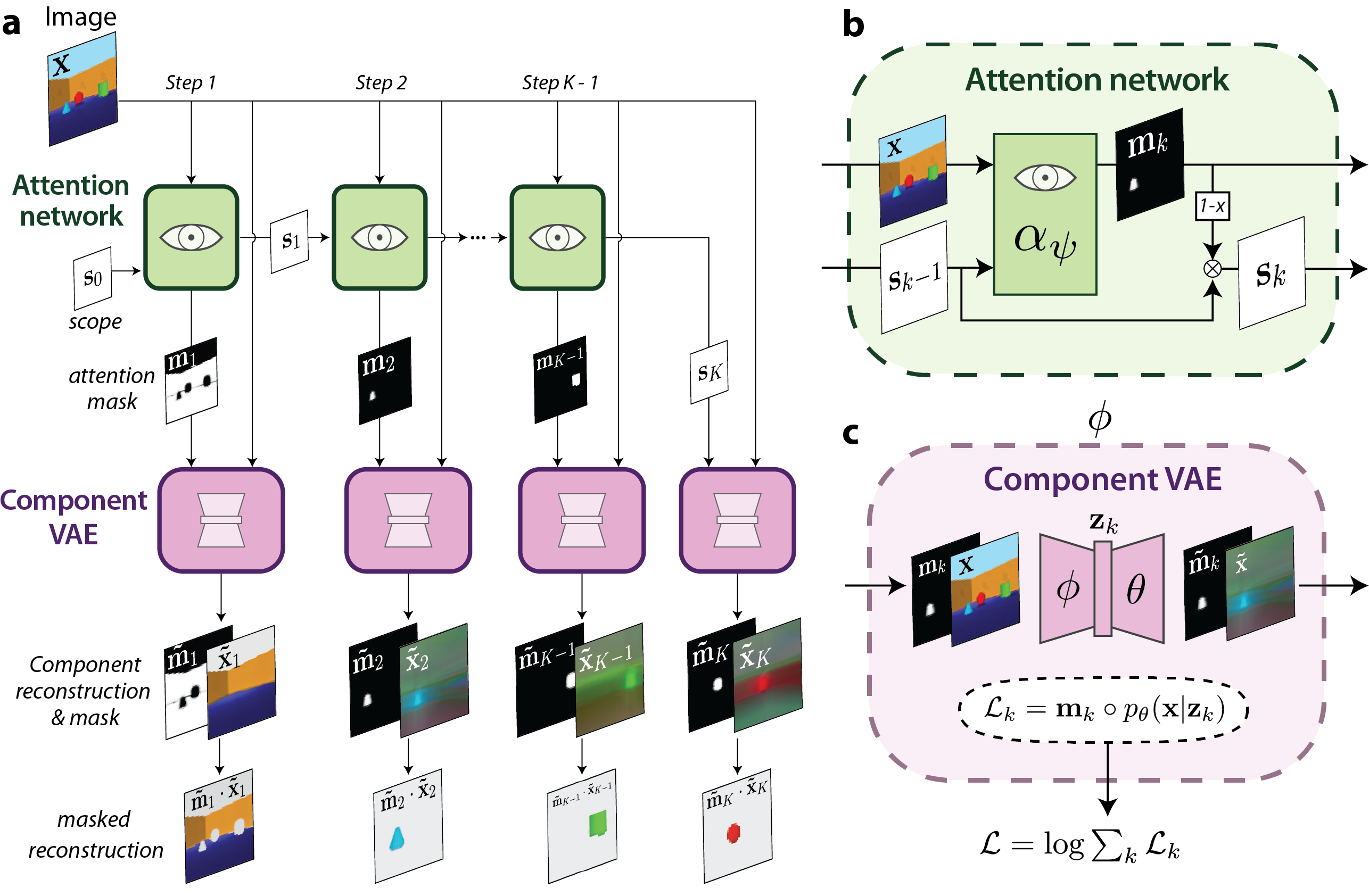
- 監視なしでシーンを覆うマスク列を生成する再帰的アテンションネットワークを使用する。
- マスクされた領域を再構成するだけのコンポーネント VAE を各マスク領域に適用し、遮られた領域を推定できるようにする。
- VAE の再構成、スロットごとの潜在変数に対するKL正則化、デコード済みマスクとアテンションマスクを揃えるKL項を組み合わせた損失で端から端の訓練を行う。
- 全体の画像を K スロットで覆うよう、マスクの範囲を確保するスコープ変数を維持する(マスクの和は1になる)。
- スロット数を変動可能(K)とし、テスト時に見た enemmän のオブジェクトを上回る/下回るシーンへ一般化する。
- 分離とマスクモデリングを制御するハイパーパラメータ beta と gamma で最適化する。
実験結果
リサーチクエスチョン
- RQ1MONet は教師なしで複雑なシーンを意味のあるオブジェクトへ分解することができるか?
- RQ2学習されたマスクはオブジェクト、壁、背景など意味のあるシーン要素に対応するか?
- RQ3MONet はオクルージョンと可変オブジェクト数に対応し、未見の構成へ一般化できるか?
- RQ4スロット間の潜在表現は解釈可能な特徴へ分離されるか?
- RQ5構成的処理は再構成の効率性と精度にどのような影響を与えるか?
主な発見
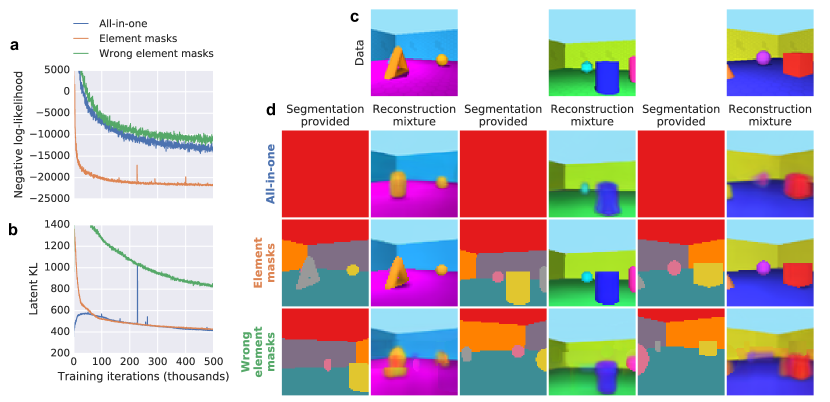
- MONet は非自明な3Dシーンをオブジェクトと背景要素へ教師なしで分解することを達成する。
- テスト時に追加のスロット(例: 9 スロット)へ一般化し、訓練時より多いオブジェクトを含むシーンへも適用可能。
- スロット内の潜在因子は分離可能で、トラバーサルで制御可能な解釈可能な特徴を示す。
- MONet は遮蔽されたオブジェクトや高度に重なる形状を含むシーンを、複数のデータセット(Objects Room、Multi-dSprite、CLEVR)で正確にセグメンテーションと再構成を行う。
- このアプローチは遮蔽領域の一貫したインペイントを生み出し、データセット間の堅牢な適用性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。