[論文レビュー] More Control for Free! Image Synthesis with Semantic Diffusion Guidance
本論文は Semantic Diffusion Guidance (SDG) を紹介する。これは、言語と画像の誘導を無条件拡散モデルへ組み込み、制御可能な画像合成を実現する統一された再学習不要のフレームワークであり、自己教師付きの CLIP 微調整ステップを含む。
Controllable image synthesis models allow creation of diverse images based on text instructions or guidance from a reference image. Recently, denoising diffusion probabilistic models have been shown to generate more realistic imagery than prior methods, and have been successfully demonstrated in unconditional and class-conditional settings. We investigate fine-grained, continuous control of this model class, and introduce a novel unified framework for semantic diffusion guidance, which allows either language or image guidance, or both. Guidance is injected into a pretrained unconditional diffusion model using the gradient of image-text or image matching scores, without re-training the diffusion model. We explore CLIP-based language guidance as well as both content and style-based image guidance in a unified framework. Our text-guided synthesis approach can be applied to datasets without associated text annotations. We conduct experiments on FFHQ and LSUN datasets, and show results on fine-grained text-guided image synthesis, synthesis of images related to a style or content reference image, and examples with both textual and image guidance.
研究の動機と目的
- 事前学習済みの無条件拡散モデル内で、テキスト、画像、またはその両方の誘導を用いた、細粒度で連続的な画像合成の制御を可能にする。
- 言語アノテーションを持たないデータセットに対して、テキスト誘導による合成をサポートする。
- 参照画像からのコンテンツ誘導またはスタイル誘導を用いた画像誘導合成を可能にする。
- 言語と画像信号を組み合わせたマルチモーダルな誘導の統合フレームワークを提供する。
提案手法
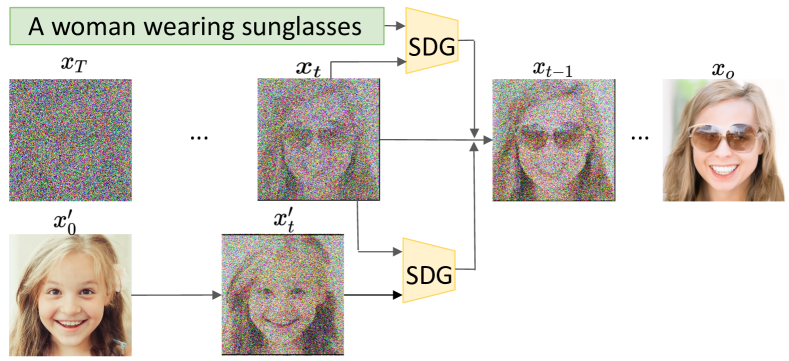
- 勾配ベースの誘導関数を介して、定番の無条件拡散モデルに誘導を注入する。
- ノイズの多い拡散タイムステップを扱うため、時間依存の画像エンコーダを介してCLIPベースの言語誘導を使用する。
- 2つの画像誘導モードを定義する:コンテンツ誘導(埋め込みの意味的類似性)とスタイル誘導(特徴マップのGram行列整合性)。
- 言語と画像の誘導信号を可変重みで線形結合して、多モード誘導を可能にする。
- テキストアノテーションを回避するため、ノイズを加えた画像上で自己教師付き対比目的関数を用いてCLIP画像エンコーダを微調整する。
実験結果
リサーチクエスチョン
- RQ1SDGは、画像とテキストのペアデータを必要とせず、細粒度で多様なテキストから画像への合成を提供できるか?
- RQ2SDGは、内容やスタイルを保持しつつ構造的な変化を許容する、意味のある画像誘導を提供できるか?
- RQ3マルチモーダル(テキスト+画像)誘導は、単一モダリティ誘導と比べて品質・多様性・誘導との整合性の点でどうなるか?
主な発見
| Method | FID | LPIPS | Top 1 | Top 5 | Top 10 | Top 20 |
|---|---|---|---|---|---|---|
| ILVR (Image Guidance, N=32) | 17.15 | 0.439 | 0.205 | 0.416 | 0.556 | 0.727 |
| SDG (Image Guidance) | 14.37 | 0.583 | 0.520 | 0.742 | 0.816 | 0.906 |
| StyleGAN+CLIP (Text Guidance) | 57.45 | 0.578 | 0.749 | 0.934 | 0.974 | 0.996 |
| SDG (Text Guidance) | 28.38 | 0.610 | 0.553 | 0.795 | 0.878 | 0.947 |
- SDGは、従来の画像誘導法(FIDおよびLPIPS)よりも高い画像品質と多様性を達成しつつ、誘導との意味的整合性を可能にする。
- 画像誘導合成では、SDGはLSUNおよびFFHQのサブセット全体で、品質(FIDが低い)と多様性(LPIPSが高い)の両方でILVRを上回る。
- テキスト誘導合成では、SDGはStyleGAN+CLIPとプロンプトへの整合性で競合的な結果を示しつつ、より良い多様性を維持する。
- マルチモーダル誘導は、言語指示と参照画像の手掛かりの両方を満たす画像を可能にし、内容とスタイルの柔軟な制御を提供します。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。