[論文レビュー] MotionGPT: Human Motion as a Foreign Language
MotionGPT は、人間の動作と言語を単一の生成モデルに統合し、動作をトークンに量子化し、言語モデルのバックボーンを用いてプロンプトによる多様な動作タスクを実行することで、text-to-motion、motion-to-text、予測、及び中間タスクで強力な結果を達成します。
Though the advancement of pre-trained large language models unfolds, the exploration of building a unified model for language and other multi-modal data, such as motion, remains challenging and untouched so far. Fortunately, human motion displays a semantic coupling akin to human language, often perceived as a form of body language. By fusing language data with large-scale motion models, motion-language pre-training that can enhance the performance of motion-related tasks becomes feasible. Driven by this insight, we propose MotionGPT, a unified, versatile, and user-friendly motion-language model to handle multiple motion-relevant tasks. Specifically, we employ the discrete vector quantization for human motion and transfer 3D motion into motion tokens, similar to the generation process of word tokens. Building upon this "motion vocabulary", we perform language modeling on both motion and text in a unified manner, treating human motion as a specific language. Moreover, inspired by prompt learning, we pre-train MotionGPT with a mixture of motion-language data and fine-tune it on prompt-based question-and-answer tasks. Extensive experiments demonstrate that MotionGPT achieves state-of-the-art performances on multiple motion tasks including text-driven motion generation, motion captioning, motion prediction, and motion in-between.
研究の動機と目的
- Motivate and enable a unified motion-language pre-training framework to leverage large-scale language data for motion tasks.
- Develop a motion tokenizer to convert continuous motion into discrete tokens forming a motion vocabulary.
- Train a motion-aware language model that jointly handles motion tokens and text tokens in a single vocabulary.
- Apply instruction tuning to enable prompt-based, multi-task learning for diverse motion-related tasks.
提案手法
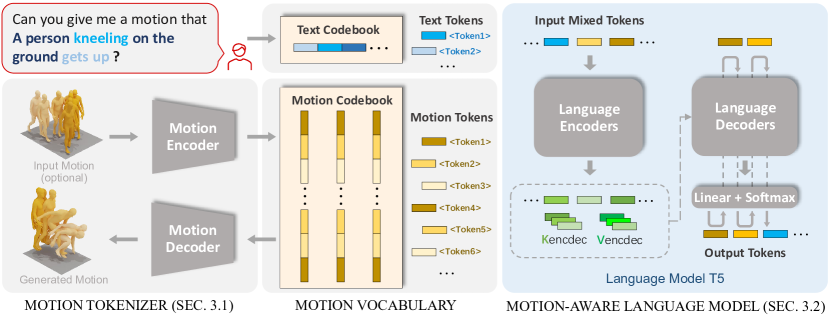
- Introduce a motion tokenizer using a VQ-VAE to convert M-frame motions into a sequence of L discrete motion tokens from a learnable codebook Z.
- Create a unified vocabulary V by combining motion tokens with text tokens, enabling the model to process and generate both modalities within a single transformer-based backbone.
- Pre-train a motion-language model (based on T5) on a mixture of motion and language data to capture cross-modal semantics.
- Apply a three-stage training scheme: (i) train the motion tokenizer, (ii) perform motion-language pre-training with unsupervised and supervised objectives, (iii) execute instruction tuning with a diverse set of prompts for multiple motion tasks.
- Utilize an autoregressive objective to maximize the likelihood of target token sequences conditioned on source sequences across motion and text, enabling flexible generation from prompts.
実験結果
リサーチクエスチョン
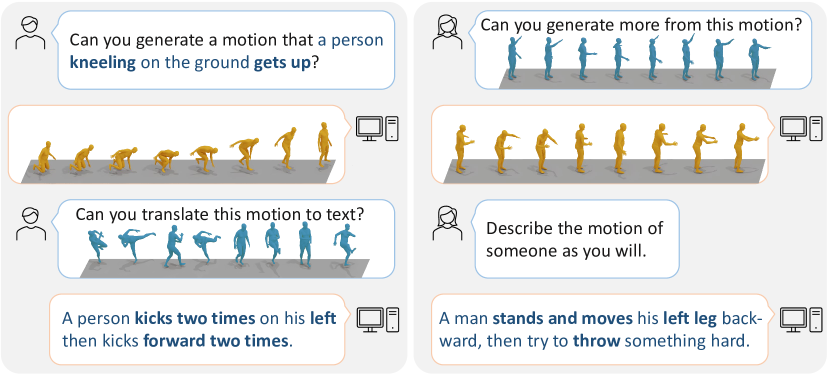
- RQ1Can a single unified model handle multiple motion tasks (text-to-motion, motion-to-text, prediction, in-between) via a motion-language framework?
- RQ2Does learning a discrete motion vocabulary and jointly training with language data improve generalization to unseen motion-language tasks?
- RQ3How effective is instruction tuning with prompt-based datasets in enabling zero-shot or few-shot adaptation to varied motion tasks?
主な発見
- MotionGPT achieves competitive or state-of-the-art performance across diverse motion tasks including text-to-motion, motion captioning, motion prediction, and motion in-between.
- A motion tokenizer based on VQ-VAE effectively represents motion as discrete tokens suitable for integration with language models.
- Joint training of motion and language within a unified vocabulary enables the model to reason with both modalities using a single transformer backbone.
- Instruction tuning with a large set of prompts improves versatility and performance on unseen tasks, while larger model sizes without ample motion data do not always yield gains.
- The three-stage training scheme (tokenizer training, motion-language pre-training, and instruction tuning) is shown to be effective for learning cross-modal relationships.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。