[論文レビュー] mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
mPLUG-2は、テキスト、画像、ビデオの統一事前学習のためのモジュール化されたトランスフォーマー枠組みを導入し、モダリティ固有のコンポーネントを共有の普遍モジュールから切り離して、タスク固有のモジュールの柔軟な組み立てと強力なクロスモーダル性能を実現します。
Recent years have witnessed a big convergence of language, vision, and multi-modal pretraining. In this work, we present mPLUG-2, a new unified paradigm with modularized design for multi-modal pretraining, which can benefit from modality collaboration while addressing the problem of modality entanglement. In contrast to predominant paradigms of solely relying on sequence-to-sequence generation or encoder-based instance discrimination, mPLUG-2 introduces a multi-module composition network by sharing common universal modules for modality collaboration and disentangling different modality modules to deal with modality entanglement. It is flexible to select different modules for different understanding and generation tasks across all modalities including text, image, and video. Empirical study shows that mPLUG-2 achieves state-of-the-art or competitive results on a broad range of over 30 downstream tasks, spanning multi-modal tasks of image-text and video-text understanding and generation, and uni-modal tasks of text-only, image-only, and video-only understanding. Notably, mPLUG-2 shows new state-of-the-art results of 48.0 top-1 accuracy and 80.3 CIDEr on the challenging MSRVTT video QA and video caption tasks with a far smaller model size and data scale. It also demonstrates strong zero-shot transferability on vision-language and video-language tasks. Code and models will be released in https://github.com/alibaba/AliceMind.
研究の動機と目的
- モダリティの協調と結合をバランスさせる統一的でありながらモジュラーな多モーダル事前学習アプローチの動機付け。
- 多様な uni-および cross-modal タスクをサポートする普遍的なモジュールの共有ネットワークとモダリティ固有コンポーネントを開発。
- テキスト、画像、およびビデオの理解と生成のための柔軟なタスク固有モジュール選択を可能にする。
- 画像テキストおよびビデオテキストの理解と生成を含む30以上の下流タスクで強力な性能を示す。
- 限られた事前学習データでのゼロショット転送可能性と効率性を示す。
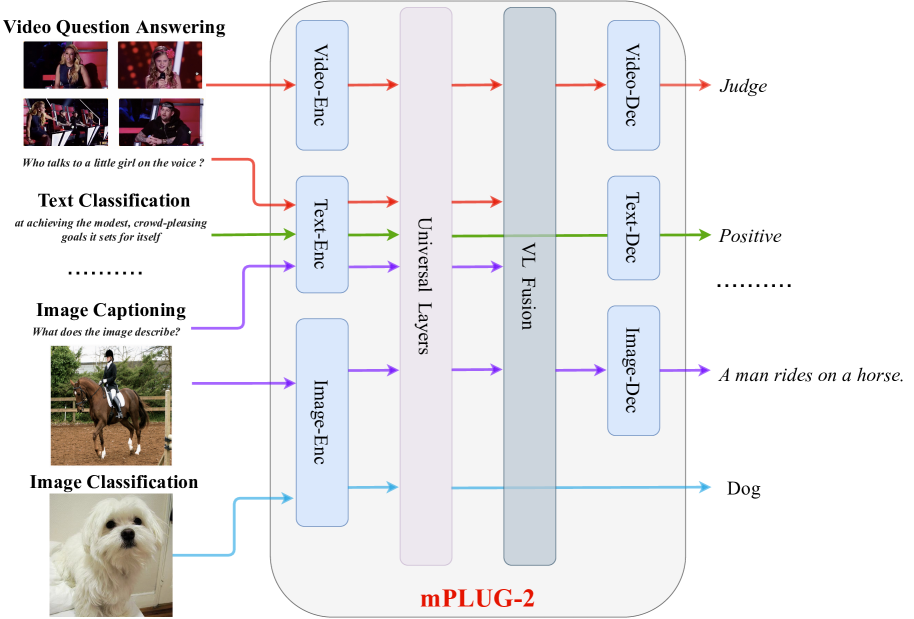
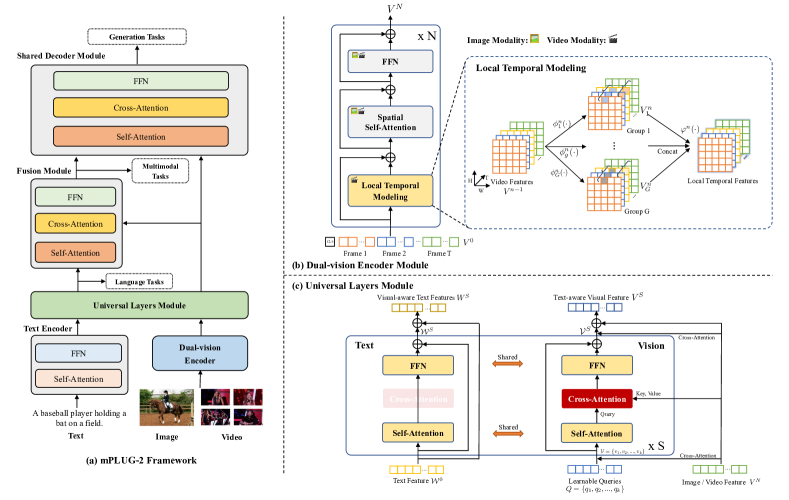
提案手法
- 画像とビデオのための空間的および局所的時間モデリングを備えたデュアルビジョンエンコーダを提案。
- 自己注意とクロス注意操作を介してビジョンと言語を共有意味空間にマッピングする普遍層を導入。
- 生成タスクのためのクロスモーダル表現を統合するクロスモーダルフュージョンモジュールを追加。
- uni-modal および cross-modal 生成タスクの両方に対応する共有Transformersベースのデコーダを採用。
- FlamingoとOFAに触発された言語 MLM、クロスモーダルマッチング損失、指示ベースの言語モデリング目標を用いて事前学習。
実験結果
リサーチクエスチョン
- RQ1モジュール化は、テキスト、画像、ビデオタスク間のモダリティ結合を可能にしつつ、モダリティ結合を緩和できるか。
- RQ2共有普遍モジュールとモダリティ固有コンポーネントは、 uni-modal および cross-modal ベンチマークのパフォーマンスにどのように影響するか。
- RQ3モジュール化された多モーダル基盤モデルを使用する際の、単一ネットワークアプローチと比較した効率性と転移性の向上はどの程度か。
- RQ4視覚言語およびビデオ言語設定の検索、QA、キャプショニング、生成を含む30以上のタスクで、最先端または競争力のある結果をどの程度達成できるか。
主な発見
- 30を超える下流タスクで、画像テキストおよびビデオテキストの理解と生成において最先端または競争力のある結果を達成。
- より小さなモデルとデータフットプリントでMSRVTTのビデオQAおよびビデオキャプションタスクで新しい最先端結果を示す(トップ-1 48.0、CIDEr 80.3)。
- ビジョン言語およびビデオ言語タスクで強力なゼロショット転移性を示す。
- mPLUG-2 Baseおよびフルバージョンは、ビデオからテキストの検索およびビデオQAベンチマークで、事前学習データを大幅に減らしても複数の従来手法より上回る。
- モジュール設計により、タスク固有モジュールの柔軟な組み立てが可能となり、モデルサイズを過度に増やすことなく uni-modal および cross-modal の性能を向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。