[論文レビュー] mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
mPLUG-Owl は、凍結された言語モデルと学習可能な視覚知識モジュールおよび視覚要約器を組み合わせたモジュラーな訓練パラダイムを導入し、マルチモーダル理解とマルチターン対話を可能にする。評価は OwlEval で行われた。
Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
研究の動機と目的
- 大規模言語モデルを完全に再訓練せずに、LLMs にマルチモーダル能力を有効化する動機づけ。
- 視覚ファウンデーションモデルと視覚知識モジュール、および視覚要約器を組み合わせたモジュール型アーキテクチャを提案する。
- LLM の生成能力を保持しつつ、画像とテキストを整列させる二段階訓練パラダイムを開発する。
- 結合型指示調整を通じて、単一モーダルおよびマルチモーダルの指示理解とマルチターン対話の改善を実証する。)
提案手法
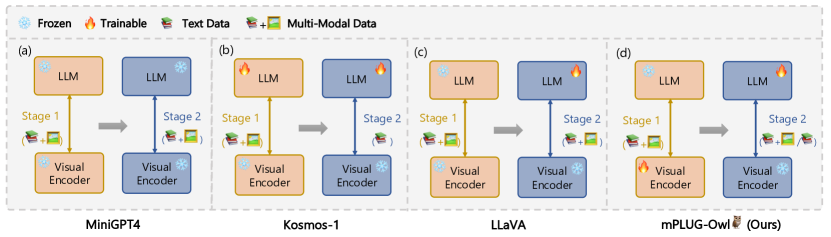
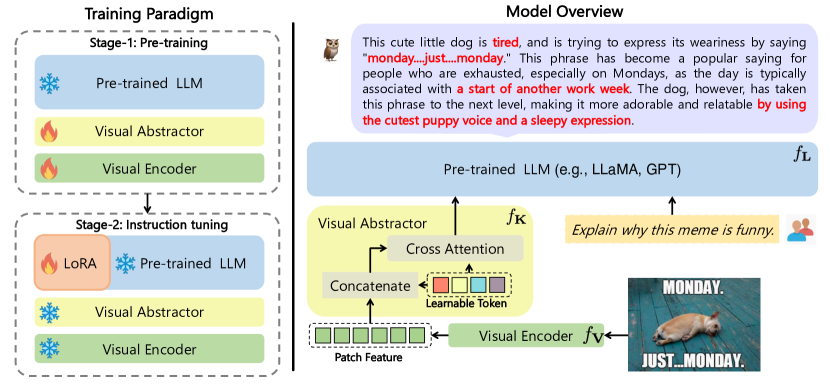
- 視覚ファウンデーションモデル f_V を用いて視覚特徴を抽出する。
- 視覚特徴を学習可能なトークンに要約する視覚要約器 f_K を導入する。
- 画像-テキスト表現を整合させるために視覚コンポーネントを訓練する一方、言語ファウンデーションモデル f_L を凍結する。
- ステージ1: 凍結されたLLM を用い、画像キャプション対を用いて視覚知識と要約器を訓練する。
- ステージ2: f_V を凍結し、f_L および f_K に LoRA を訓練して、言語オンリーおよびマルチモーダルデータを用いた結合指示調整を行う。
実験結果
リサーチクエスチョン
- RQ1モジュラー式の視覚-言語セットアップは、凍結された LLM と視覚知識を整合させてマルチモーダル理解を可能にするか。
- RQ2マルチモーダルデータとテキストのみデータを用いた二段階訓練は、ベースラインと比較して単一モーダルおよびマルチモーダルの指示従いを改善するか。
- RQ3モジュール式のマルチモーダル訓練からどのようなエマージェント能力が生じるか(例: 複数画像間の相関、場面テキスト理解、多言語対話など)?
主な発見
- mPLUG-Owl は OwlEval における指示理解と視覚タスクで MiniGPT-4 や LLaVA などのベースラインを上回る。
- マルチモーダル事前学習と結合指示調整を組み合わせた二段階訓練スキームが最良の性能をもたらす。
- 結合型マルチモーダル指示データとテキストのみ指示データの両方が知識伝達と推論能力を高める。
- アブレーションは、指示調整時のマルチモーダルデータが視覚知識の整合とテキストのみタスクの性能を向上させることを示す。
- 定性的分析は、複数画像間の相関や多言語対話などのエマージェント能力を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。