[論文レビュー] mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
mPLUG-Owl2はモダリティ適応型言語デコーダとビジュアル要約器を導入し、モダリティ間の協調を可能にしつつモダリティ固有の特徴を保持することで、単一の汎用モデルでテキストおよびマルチモーダルタスクの最先端結果を達成します。
Multi-modal Large Language Models (MLLMs) have demonstrated impressive instruction abilities across various open-ended tasks. However, previous methods primarily focus on enhancing multi-modal capabilities. In this work, we introduce a versatile multi-modal large language model, mPLUG-Owl2, which effectively leverages modality collaboration to improve performance in both text and multi-modal tasks. mPLUG-Owl2 utilizes a modularized network design, with the language decoder acting as a universal interface for managing different modalities. Specifically, mPLUG-Owl2 incorporates shared functional modules to facilitate modality collaboration and introduces a modality-adaptive module that preserves modality-specific features. Extensive experiments reveal that mPLUG-Owl2 is capable of generalizing both text tasks and multi-modal tasks and achieving state-of-the-art performances with a single generic model. Notably, mPLUG-Owl2 is the first MLLM model that demonstrates the modality collaboration phenomenon in both pure-text and multi-modal scenarios, setting a pioneering path in the development of future multi-modal foundation models.
研究の動機と目的
- 一般用途のモ multimodal foundation modelが、モダリティ協調を通じてテキストとマルチモーダルタスクの両方を改善するよう動機づける。
- モダリティを分離しつつ、共有インターフェースを介してクロスモーダル相互作用を可能にするモジュラーアーキテクチャを開発する。
- モダリティ固有の特徴を保持しつつ協調を可能にするモダリティ適応モジュールを提案する。
- 視覚言語事前学習と視覚言語指示チューニングを統合した二段階の学習パラダイムを導入する。
- 標準的な視覚言語ベンチマークと単純テキストタスクの両方で強い一般化能力を示す。
提案手法
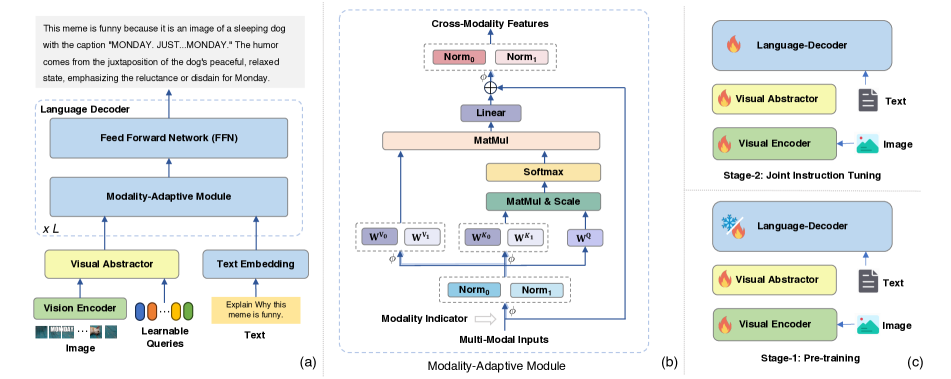
- ビジョンエンコーダ、視覚要約器、テキスト埋め込み層、言語デコーダを普遍的なインターフェースとして備えたモジュラーアーキテクチャを使用する。
- 計算量を削減するために学習可能なクエリを備えた視覚要約器を導入する。
- キーと値のモダリティ固有の射影を分離しつつクエリを共有するModality-Adaptive Module (MAM)を提案し、粒度干渉を生じさせずにクロスモーダル協調を可能にする。
- 視覚と言語の特徴を共通の意味空間へ射影しつつ、別々の値射影と異なる層正規化を通じてモダリティの特性を維持する。
- 二段階の学習パラダイムを採用する:(i)訓練可能な視覚エンコーダを用いた視覚言語 pre-training、(ii)視覚言語指示チューニングの結合。
- 視覚要約器には固定の学習可能なクエリセットを使用して高レベルな意味特徴を抽出し、デコード前に系列長を削減する。
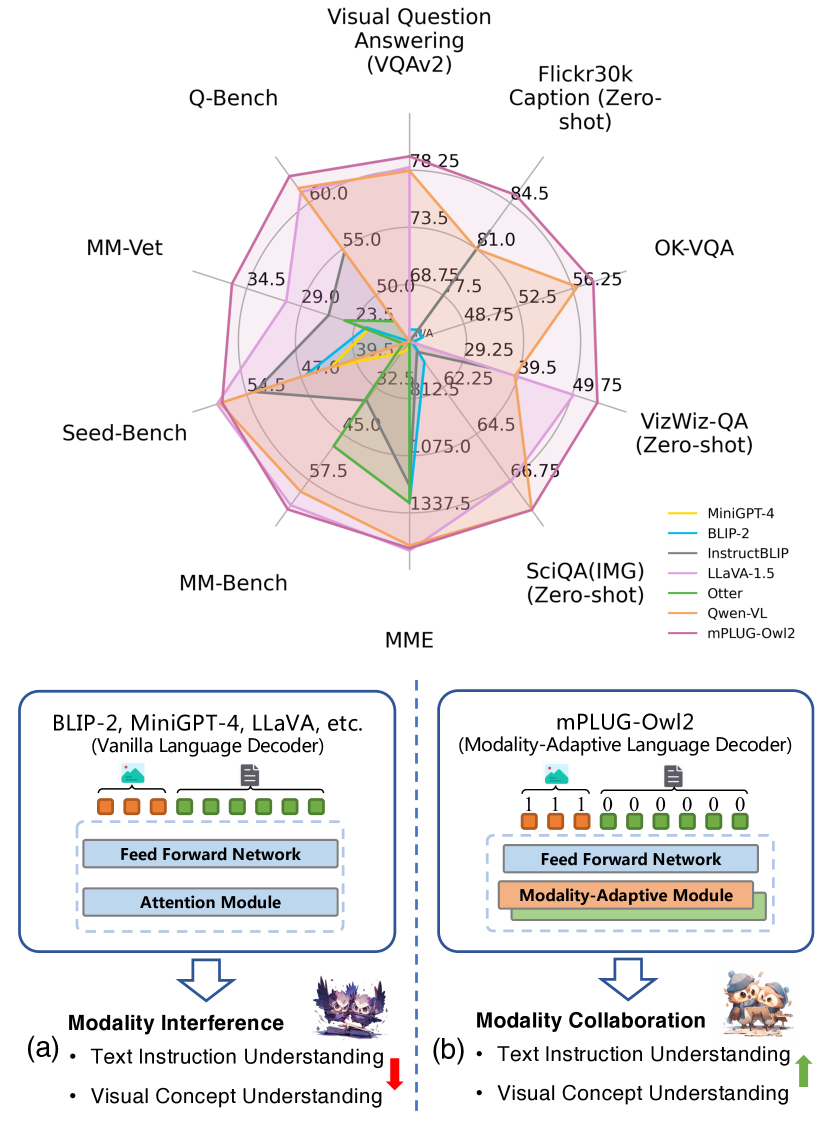
実験結果
リサーチクエスチョン
- RQ1モダリティ協調は単一の汎用モデルにおいてテキストのみタスクとマルチモーダルタスクの両方の性能を改善できるか?
- RQ2デコーダと注意機構をどのように設計すればモダリティ干渉を緩和しつつモダリティ固有情報を保持できるか?
- RQ3視覚言語機能と純テキスト能力の共同最適化を最も適切にサポートする学習レジメンは何か?
- RQ4視覚解像度と視覚要素検索クエリ数を増やすとOCR重視・細粒度タスクの性能は向上するか?
- RQ5提案されたモダリティ適応モジュールはゼロショットおよび指示調整性能をベンチマーク全体でどのように影響するか?
主な発見
- mPLUG-Owl2は単一の汎用モデルで8つの視覚言語ベンチマークで最先端の性能を達成。
- モデルはMMBench、MM-Vet、Q-Benchといったマルチモーダルベンチマークで強力なゼロショット性能を示し、MMEでも競争力のある結果を示す。
- 純テキストベンチマークも改善し、他の指示調整LLMと比べてMMLUおよびBBHで顕著な向上を示す。
- Modality-Adaptive Module (MAM)はモダリティ干渉を低減しつつモダリティ協調を可能にすることを、アテンションの可視化とアブレーション研究で示した。
- 訓練可能な視覚エンコーダを用いた視覚言語指示チューニングの組み合わせにより強力なマルチモーダルおよびテキスト性能を得られ、両モダリティを同時に訓練した場合にはMAMがさらなる安定した利益をもたらす。
- 視覚要約器の解像度と学習可能クエリ数を増やすと、OCR重視・細粒度視覚言語タスクの性能が大幅に向上する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。