[論文レビュー] Multi-Concept Customization of Text-to-Image Diffusion
tldr: Custom Diffusion は少数の例から新しい概念を学習するためにクロスアテンション重みの小さなサブセットを微調整し、構成的生成と既存の拡散モデルとの効率的なマルチ概念統合を実現します。
While generative models produce high-quality images of concepts learned from a large-scale database, a user often wishes to synthesize instantiations of their own concepts (for example, their family, pets, or items). Can we teach a model to quickly acquire a new concept, given a few examples? Furthermore, can we compose multiple new concepts together? We propose Custom Diffusion, an efficient method for augmenting existing text-to-image models. We find that only optimizing a few parameters in the text-to-image conditioning mechanism is sufficiently powerful to represent new concepts while enabling fast tuning (~6 minutes). Additionally, we can jointly train for multiple concepts or combine multiple fine-tuned models into one via closed-form constrained optimization. Our fine-tuned model generates variations of multiple new concepts and seamlessly composes them with existing concepts in novel settings. Our method outperforms or performs on par with several baselines and concurrent works in both qualitative and quantitative evaluations while being memory and computationally efficient.
研究の動機と目的
- 事前学習時に見られなかったユーザー固有の概念(例:ペット、物体)に対する大規模テキスト対画像モデルのパーソナライズを動機づける。
- 既存の概念知識を保持しつつ新しい概念を学習する、簡潔なファインチューニング手法を開発する。
- 破局的忘却なしに、単一の画像生成で複数の新しい概念の組み合わせを可能にする。
- トレーニング時間とメモリ使用量を実用レベルまで最小化する。
提案手法
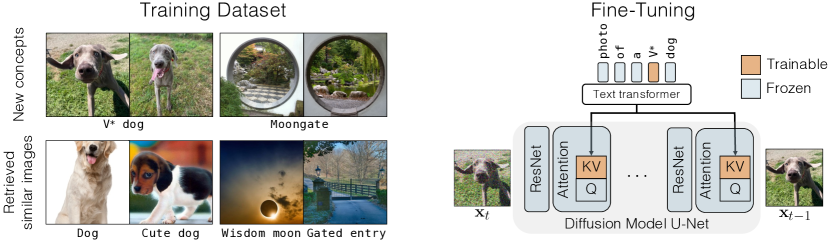
- 微調整中に更新するクロスアテンション層の最小で影響力のあるパラメータサブセット(キーとバリューの射影)を特定する。
- 個別概念を示す新しい修飾トークン V* を使用し、クロスアテンション行列とともにその埋め込みを最適化する。
- 言語の崩れと過学習を防ぐため、類似キャプションを持つ実画像の正則化データセットを組み込む。
- 収束を改善するため、ファインチューニング時に画像リサイズなどの拡張を適用する。
- 複数の概念については、共同訓練するか、閉形式の制約付き最適化(最小二乗法)で概念を統合して組み合わせを可能にする。
- ターゲット概念の写像を事前計算された正則化写像と一致させるよう、制約付き最適化目的で組成を固定する。
実験結果
リサーチクエスチョン
- RQ1少数のクロスアテンション重みのサブセットだけで新しい概念を学習するのに十分か?
- RQ2クロスアテンションのキーと値だけを更新して既存の知識を保持しつつ新しい概念学習を可能にするか?
- RQ3複数の新しい概念を同時に学習し、斬新なプロンプトで一貫して組み合わせられるか?
- RQ4閉形式の制約付き最適化による複数のファインチューニング概念の統合はどれほど効果的か?
主な発見
| 方法 | テキスト整合 | 画像整合 | KID (検証) |
|---|---|---|---|
| Single-concept: Textual Inversion | 0.670 | 0.827 | 22.27 |
| Single-concept: DreamBooth | 0.781 | 0.776 | 32.53 |
| Single-concept: Ours (w/ fine-tune all) | 0.795 | 0.748 | 19.27 |
| Single-concept: Ours | 0.795 | 0.775 | 20.96 |
| Multi-concept: Textual Inversion | 0.544 | 0.630 | — |
| Multi-concept: DreamBooth | 0.783 | 0.695 | — |
| Multi-concept: Ours (w/ fine-tune all) | 0.787 | 0.691 | — |
| Multi-concept: Ours (Sequential) | 0.797 | 0.700 | — |
| Multi-concept: Ours (Optimization) | 0.800 | 0.695 | — |
| Multi-concept: Ours (Joint) | 0.801 | 0.706 | — |
- クロスアテンション重みの更新は過度に影響力が大きく、モデルの約3%のパラメータを更新するだけで概念学習が可能。
- 正則化セットを用いたファインチューニングは過学習と語彙の崩れを減少させ、画像と言語の整合を改善。
- 他のベースラインと比較して、我々の手法は2つの A100 GPU で約6分程度のファインチューニングと、概念ごと約75 MB程度のストレージを実現し、速く小さい。
- マルチ概念の訓練と閉形式の構成は、共有シーンで一貫した生成を可能にし、多くのケースでベースラインを上回るか同等。
- DreamBooth と Textual Inversion と比較して、Custom Diffusion は単一概念シナリオでより高いテキスト・画像整合性と低い KID を達成。
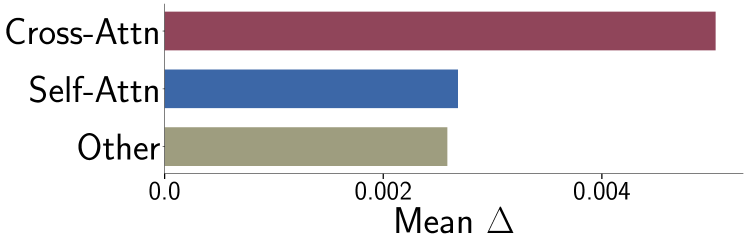
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。