[論文レビュー] Multi-Source Conformal Inference Under Distribution Shift
分布に依存しない予測区間を、欠測アウトカムと分布シフトの下で、データ源が複数あり、データ適応的重み付けとプライバシー保護型連合更新を用いてターゲット集団に対して開発する。
Recent years have experienced increasing utilization of complex machine learning models across multiple sources of data to inform more generalizable decision-making. However, distribution shifts across data sources and privacy concerns related to sharing individual-level data, coupled with a lack of uncertainty quantification from machine learning predictions, make it challenging to achieve valid inferences in multi-source environments. In this paper, we consider the problem of obtaining distribution-free prediction intervals for a target population, leveraging multiple potentially biased data sources. We derive the efficient influence functions for the quantiles of unobserved outcomes in the target and source populations, and show that one can incorporate machine learning prediction algorithms in the estimation of nuisance functions while still achieving parametric rates of convergence to nominal coverage probabilities. Moreover, when conditional outcome invariance is violated, we propose a data-adaptive strategy to upweight informative data sources for efficiency gain and downweight non-informative data sources for bias reduction. We highlight the robustness and efficiency of our proposals for a variety of conformal scores and data-generating mechanisms via extensive synthetic experiments. Hospital length of stay prediction intervals for pediatric patients undergoing a high-risk cardiac surgical procedure between 2016-2022 in the U.S. illustrate the utility of our methodology.
研究の動機と目的
- 複数の異種データ源を用いてターゲットサイトの欠測アウトカムに対する妥当な予測区間を提供する。
- 条件付きアウトカム分布がサイト間で異なる場合に、ソースサイトの情報を活用する。
- 個人レベルのデータを共有せずに、名目上のカバレッジを達成する。
- 効率を損なうことなく、迷惑成分の機械学習予測を取り入れる。
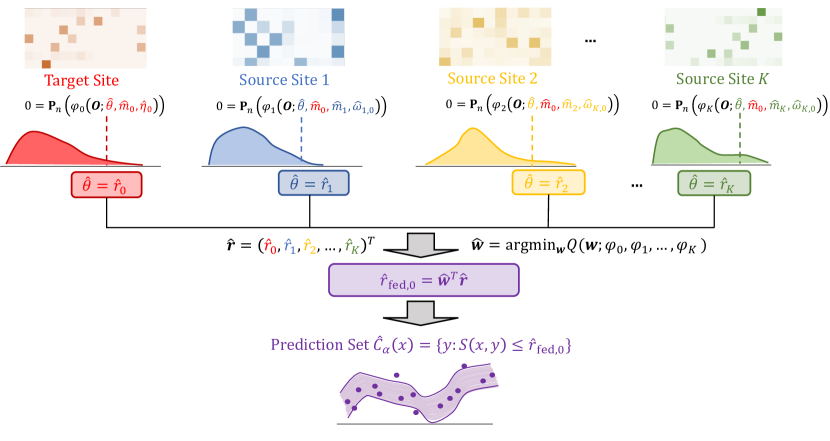
提案手法
- conformal スコア S(X,Y) とターゲット分位点 r0 を定義して 1-α の周辺カバレッジを達成する。
- 一般的な条件付きアウトカム分布(CCOD)と欠測-at-random 仮定の下で r0 の効率的影響関数を導出する。
- パラメトリック様の収束率を達成するためにクロスフィッティングと SuperLearner ベースのニーズ推定を提案する。
- CCOD が破られた場合にサイト固有の分位点 r_k を結合するデータ適応連合重み付けを導入する。
- データ共有を最小限に抑えつつ、密度比とサイト固有量を計算するプライバシー保護手順を提供する。
- 指定条件下で重み付け集合が名目上のカバレッジを維持できるオラクルカバレッジ結果を提供する。
実験結果
リサーチクエスチョン
- RQ1複数の異種サイトから欠測アウトカムデータを用いてターゲット集団の妥当な分布に依存しない予測区間を構築できるか。
- RQ2アウトカムの条件付き分布がサイト間で同一でない場合、ソースサイトの情報をどのように統合できるか。
- RQ3共変量シフトと異質性を多サイトの conformal 推論で扱うための効率的影響関数と推定戦略は何か。
- RQ4データ適応的連合は、ターゲットのみまたはプールデータ手法と比較してカバレッジと区間幅にどう影響するか。
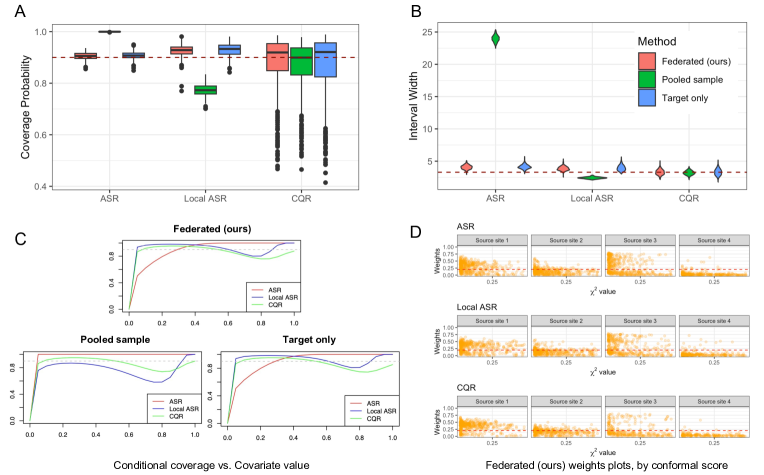
主な発見
- 提案手法は MAR および CCOD 仮定の下で名目上のカバレッジを満たす妥当な予測区間を、複数サイトの情報を活用して提供する。
- CCOD 下の効率的影響関数により、ターゲットサイトの分位点 r0 の推定を改善するためにサイト間のデータを結合できる。
- データ適応的連合メカニズムは CCOD が破られた場合にサイトへ重み付けを割り当て、非情報源からのバイアスを減らして効率を改善する。
- クロスフィットと SuperLearner により、ギャップのない形でニーズ推定を柔軟に行いつつカバレッジ保証を維持する。
- 実証的結果は、連合区間がターゲットのみおよびプール手法と比べて、さまざまなシミュレーション状況でより狭く、競争力のある正確さを示す。
- 先天性心臓欠損症の病院滞在期間データを用いた応用は、ターゲットのみの方法より顕著な区間狭窄を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。