[論文レビュー] Multi-Stage Learning for Grasp-Constrained Object Manipulation with a Simulated Panda Robot
本論文は robosuite を紹介します。MuJoCo ベースのモジュラーなシミュレーションフレームワーク兼ロボット学習用ベンチマークで、標準化されたタスク、手続き的環境生成、マルチモーダルセンサを提供し、再現可能な研究を支援します。
This repository contains code and experiment assets for RAES (Reward-Aligned Expert Sequencing) and RSTB (Reward-Saturated Temporal Branching)—two lightweight reinforcement learning (RL) frameworks for long-horizon robotic manipulation without demonstrations, learned high-level controllers, or heavy task engineering. We study the robosuite [1] Stack benchmark (reach → grasp → lift/align → stack) and show that coupling continuous shaping with discrete endpoints into reward pairs produces a smoother, more learnable landscape. RAES aligns modular experts with these reward pairs (reach–grasp; lift/align–stack) and executes them sequentially. Across 10M timesteps and 5 seeds, RAES achieves the strongest performance under paired rewards, reaching 223.27 ± 28.68 mean return and 19.30% ± 2.55% success—surpassing PPO and curriculum baselines—while remaining fully RL-based (no demonstrations or hand-coded subtasks). Note: RAES and RASE (Reward Aligned Sequence of Experts) are used interchangeably in the codebase 1. Zhu Y, Wong J, Mandlekar A, Martín-Martín R, Joshi A, Lin K, Maddukuri A, Nasiriany S, Zhu Y. robosuite: A Modular Simulation Framework and Benchmark for Robot Learning. arXiv:2009.12293 [cs.RO]; 2025. Available at: https://arxiv.org/abs/2009.12293.
研究の動機と目的
- ロボット操作環境とタスクを作成するための柔軟でモジュール型のフレームワークを提供する。
- 入門障壁を下げるために、即座に使える現実的なロボットコントローラと学習パイプラインを提供する。
- 厳密な評価と再現性のための標準化されたベンチマークタスクを提供する。
- 学習とデータ収集を強化するために、多モーダルセンサと人間のデモンストレーションをサポートする。
- 多様なロボットとタスクに跨るデータ駆動型ロボティクスアルゴリズムの再現性のあるベンチマークを可能にする。
提案手法
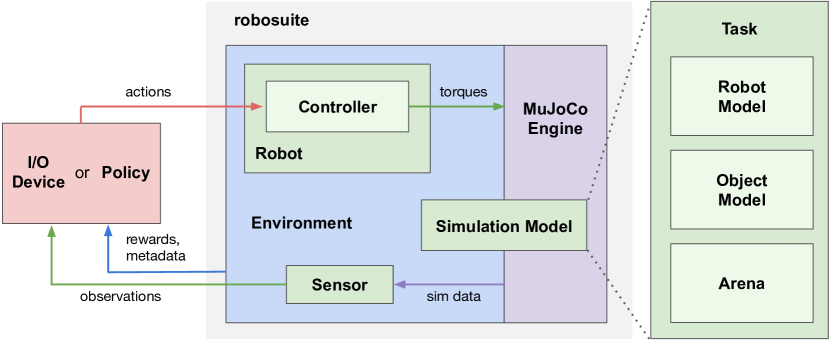
- 2つの主要な API:シミュレーション環境を定義する Modeling API と、物理エンジンと連携する Simulation API。
- タスクの構成:各 Task は RobotModel、Arena、そして Object Model を組み合わせて MuJoCo の MJCF モデルを形成する。
- 環境オブジェクトは OpenAI Gym 風のインターフェースと、設定可能なプロパティ(例:has_renderer、horizon、reward_shaping)を公開する。
- ロボット、コントローラ、センサーはモジュラーで、ロボットアーム、グリッパ、制御方式のプラグアンドプレイ組み合わせを可能にする。
- センサーはマルチモーダル観測(RGB-D、前向き感覚 proprioception、力-トルクなど)を提供し、環境は報酬とタスクメタデータを供給する。
- I/O デバイス(例:キーボード、SpaceMouse)は、デモンストレーションとデバッグのためのリアルタイムテレオペレーションおよびデータ収集を可能にする。
- ベンチマークスイートは、再現可能な実験設定で nine standardized tasks に対して学習アルゴリズム(例:SAC)を評価する。)

実験結果
リサーチクエスチョン
- RQ1モジュラーなフレームワークは、再現性のあるベンチマーキングを伴う多様なロボット操作タスクをどのように支援できるか?
- RQ2操作タスクにおけるコントローラの選択とアクション空間が学習効率に与える影響はどのようなものか?
- RQ3標準化された環境スイートは、データ駆動型ロボティクス手法の公正な比較と進捗追跡を可能にするか?
- RQ4マルチモーダル sensingと人間のデモンストレーションは、シミュレートされたロボティクスの学習パイプラインにどのように組み込まれるか?
- RQ5タスク間で学習性能を最大化する実用的な構成(ロボット、グリッパ、コントローラ)は何か?
主な発見
- robosuite v1.0 は seven robot models、eight grippers、six controllers、そして nine standardized tasks を提供します。
- SAC を用いたベンチマークでは、特定の設定の下で nine 環境中の three を解くことが示されています(Block Lifting、Door Opening、Two Arm Peg-in-Hole)。
- 操作空間コントローラは、少なくとも一部のタスクでジョイント速度コントローラと比較して学習効率を向上させ、タスク空間探索の利点を示唆します。
- Two-arm タスクは、同じフレームワーク内で複数のロボット(Panda または Sawyer)と協調的な操作能力を示します。
- このフレームワークは手続き的な環境生成と、再現可能な実験結果のためのリポジトリをサポートします。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。