[論文レビュー] Multimodal Chain-of-Thought Reasoning in Language Models
本論文は Multimodal-CoT を提案する。2段階のファインチューニングフレームワークで、テキストとビジョンの両方の入力から推論根拠を生成し、それらのマルチモーダル根拠を用いて解答を推論する。ScienceQA で 1B-models に対して最先端を達成している。
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
研究の動機と目的
- テキスト+ビジョンによるマルチモーダル Chain-of-Thought (CoT) 推論を動機づけ、解答推論を改善する。
- 1B-models が CoT で苦戦する理由と、ビジョンが推論の落とし穴をどう緩和できるかを調査する。
- 推論根拠の生成と解答推論を分離する2段階のファインチューニングフレームワークを提案する。
- ScienceQA ベンチマークでアプローチを評価し、言語のみのモデルやより大規模なモデルと比較する。
提案手法
- 2段階でテキスト・ツー・テキスト型の Transformer(T5ベース)をファインチューニングする:推論根拠の生成と解答推論。
- 視覚エンコーダ(DETR)を用いて画像特徴を抽出し、ゲート付き融合機構を介して言語表現と融合する。
- 第1段階で言語+視覚入力から推論根拠 R を生成し、第2段階で元の入力と R を条件として解答を推論する。
- ScienceQA からの注釈付き推論根拠と解答を用いた教師あり学習を行う2段階の訓練スキームを採用する。
- 言語表現と視覚表現間のアテンションベースの相互作用を通じて視覚特徴を組み込み、根拠の品質と解答精度を向上させる。
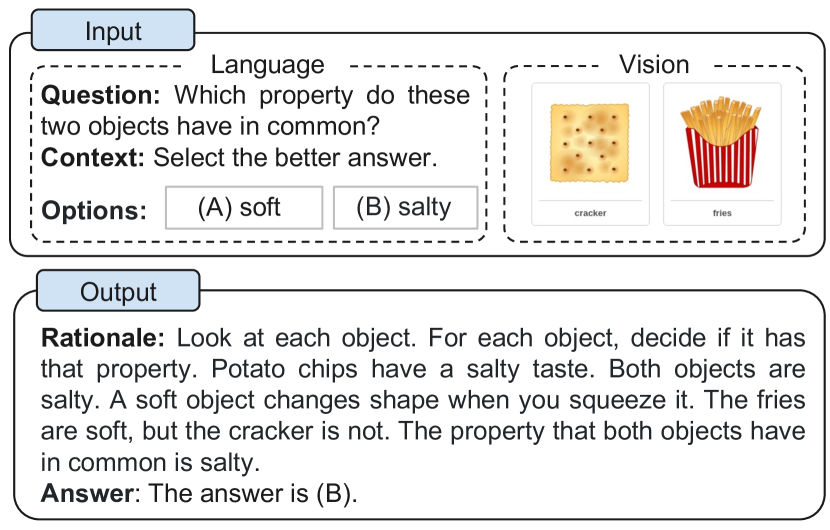
実験結果
リサーチクエスチョン
- RQ1マルチモーダル(テキスト+ビジョン)CoT 推論は、言語のみの CoT をマルチモーダル QA ベンチマークで上回るか?
- RQ2マルチモーダル入力が利用可能な場合、1B-models は2段階の根拠生成と解答推論のフレームワークの恩恵を受けるか?
- RQ3根拠の品質に対する視覚特徴(DETR)とキャプションの影響はどのようか?
- RQ4マルチモーダル融合(アテンション付きゲート融合)は、テキストのみのベースラインと比較して推論と精度にどのように影響するか?
主な発見
| Model | Size | NAT | SOC | LAN | TXT | IMG | NO | G1-6 | G7-12 | Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| Human | - | 90.23 | 84.97 | 87.48 | 89.60 | 87.50 | 88.10 | 91.59 | 82.42 | 88.40 |
| MCAN (2019) | 95M | 56.08 | 46.23 | 58.09 | 59.43 | 51.17 | 55.40 | 51.65 | 59.72 | 54.54 |
| Top-Down (2018) | 70M | 59.50 | 54.33 | 61.82 | 62.90 | 54.88 | 59.79 | 57.27 | 62.16 | 59.02 |
| BAN (2018) | 112M | 60.88 | 46.57 | 66.64 | 62.61 | 52.60 | 65.51 | 56.83 | 63.94 | 59.37 |
| DFAF (2019) | 74M | 64.03 | 48.82 | 63.55 | 65.88 | 54.49 | 64.11 | 57.12 | 67.17 | 60.72 |
| ViLT (2021) | 113M | 60.48 | 63.89 | 60.27 | 63.20 | 61.38 | 57.00 | 60.72 | 61.90 | 61.14 |
| Patch-TRM (2021) | 90M | 65.19 | 46.79 | 65.55 | 66.96 | 55.28 | 64.95 | 58.04 | 67.50 | 61.42 |
| VisualBERT (2019) | 111M | 59.33 | 69.18 | 61.18 | 62.71 | 62.17 | 58.54 | 62.96 | 59.92 | 61.87 |
| UnifiedQA Base (2020) | 223M | 68.16 | 69.18 | 74.91 | 63.78 | 61.38 | 77.84 | 72.98 | 65.00 | 70.12 |
| UnifiedQA Base + CoT | 223M | 71.00 | 76.04 | 78.91 | 66.42 | 66.53 | 81.81 | 77.06 | 68.82 | 74.11 |
| GPT-3.5 (2020) | 175B | 74.64 | 69.74 | 76.00 | 74.44 | 67.28 | 77.42 | 76.80 | 68.89 | 73.97 |
| GPT-3.5 + CoT | 175B | 75.44 | 70.87 | 78.09 | 74.68 | 67.43 | 79.93 | 78.23 | 69.68 | 75.17 |
| Multimodal-CoT Base | 223M | 87.52 | 77.17 | 85.82 | 87.88 | 82.90 | 86.83 | 84.65 | 85.37 | 84.91 |
| Multimodal-CoT Large | 738M | 95.91 | 82.00 | 90.82 | 95.26 | 88.80 | 92.89 | 92.44 | 90.31 | 91.68 |
- 視覚特徴を取り入れた Multimodal-CoT は ScienceQA で GPT-3.5 を 16 ポイント上回る(Large 設定で 91.68% vs. 75.17%).
- 2段階の Multimodal-CoT は、解答を直接予測する1段階のベースラインより高い精度を達成。
- 視覚特徴(DETR)の使用は根拠の品質(RougeL)と最終解答の精度(84.91%)を大幅に改善し、幻覚に起因する誤りを減少。
- 異なる視覚特徴は性能に影響を与える;DETR は強力な利得を提供する一方、CLIP と ResNet はこの設定では劣る。
- アプローチはバックボーンモデル(UnifiedQA Base/Large、FLAN-T5 Base/Large)間で一般化し、1B〜約0.7B パラメータ規模でも有効。
- アブレーションでは、2段階設計や視覚特徴を除くと性能が低下する(例: w/o Two-Stage Framework は Avg が 82.57 に、 w/o Vision Features は Avg が 70.53 に低下)。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。