[論文レビュー] Multimodal Foundation Models: From Specialists to General-Purpose Assistants
本論文は、マルチモーダル基盤モデルの包括的な分類と進化のレビューを提供し、専門的なビジョンモデルから大規模言語モデルとツール連携によって導かれる汎用的なビジュアルアシスタントへの移行を詳述する。
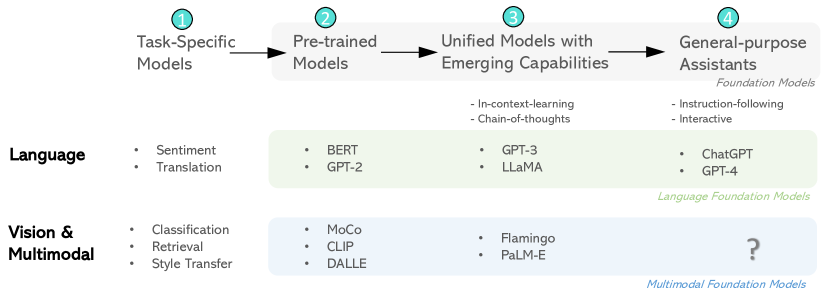
This paper presents a comprehensive survey of the taxonomy and evolution of multimodal foundation models that demonstrate vision and vision-language capabilities, focusing on the transition from specialist models to general-purpose assistants. The research landscape encompasses five core topics, categorized into two classes. (i) We start with a survey of well-established research areas: multimodal foundation models pre-trained for specific purposes, including two topics -- methods of learning vision backbones for visual understanding and text-to-image generation. (ii) Then, we present recent advances in exploratory, open research areas: multimodal foundation models that aim to play the role of general-purpose assistants, including three topics -- unified vision models inspired by large language models (LLMs), end-to-end training of multimodal LLMs, and chaining multimodal tools with LLMs. The target audiences of the paper are researchers, graduate students, and professionals in computer vision and vision-language multimodal communities who are eager to learn the basics and recent advances in multimodal foundation models.
研究の動機と目的
- 視覚および視覚言語領域におけるマルチモーダル基盤モデルの全体像と分類法を説明する。
- 監視信号の異なる視覚理解と生成の学習パラダイムを分析する。
- 一般目的のビジュアルアシスタントとLLMsとの相互作用に向けた取り組みを論じる。
- 統一ビジョンモデル、エンドツーエンドのマルチモーダル LLM、LLMsとのツール連携といった新興トピックを提示する。
提案手法
- マルチモーダル基盤モデルを特定目的と汎用アシスタントのカテゴリに分類する。
- 歴史的および現代の学習パラダイムを調査する:教師あり事前学習、言語監督、画像のみの自己教師あり学習。
- テキストから画像へ生成およびテキストベースの編集パラダイムを含む視覚生成手法を要約する。
- 統一ビジョンモデルへ向かう進展とマルチモーダルタスクにおけるLLMsとの相互作用を説明する。
- 大規模マルチモーダルモデルの訓練戦略と、LLMsとツールを連携させるマルチモーダルエージェントの設計を論じる。

実験結果
リサーチクエスチョン
- RQ1視覚および視覚言語タスクにおけるマルチモーダル基盤モデルを支える中核的な構成要素と学習パラダイムは何か?
- RQ2専門家モデルから汎用ビジュアルアシスタントへ、現在のアプローチはどのように移行しているか?
- RQ3統一ビジョンモデル、エンドツーエンドのマルチモーダル LLM、ツール連携マルチモーダルエージェントの主要な課題と新たな方向性は何か?
主な発見
- 特定目的の事前学習モデルと汎用アシスタントという二分類の分類法を特定。
- 汎用アシスタントの3つの広範なトピック:統一ビジョンモデル、エンドツーエンドのマルチモーダル LLM、LLMsとのツール連携を文書化。
- 視覚理解の学習シグナルの要約:ラベル監督、言語監督、画像のみ自己監督、さらにマルチモーダル融合およびピクセル/領域レベルの事前学習。
- テキスト条件付き生成や人間適合生成技術を含む視覚生成の動向の概要。
- 対話型でツール拡張機能を備えた能力のためのビジョンモデルとLLMsの統合に向けたマルチモーダルエージェントの進展について論じる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。