[論文レビュー] MultiModal-GPT: A Vision and Language Model for Dialogue with Humans
MultiModal-GPT は LoRA を用いて OpenFlamingo をマルチモーダル対話に微調整し、統一された視覚-言語と言語のみの指示データを用いて、複数ターンの人間対話を改善します。
We present a vision and language model named MultiModal-GPT to conduct multi-round dialogue with humans. MultiModal-GPT can follow various instructions from humans, such as generating a detailed caption, counting the number of interested objects, and answering general questions from users. MultiModal-GPT is parameter-efficiently fine-tuned from OpenFlamingo, with Low-rank Adapter (LoRA) added both in the cross-attention part and the self-attention part of the language model. We first construct instruction templates with vision and language data for multi-modality instruction tuning to make the model understand and follow human instructions. We find the quality of training data is vital for the dialogue performance, where few data containing short answers can lead the model to respond shortly to any instructions. To further enhance the ability to chat with humans of the MultiModal-GPT, we utilize language-only instruction-following data to train the MultiModal-GPT jointly. The joint training of language-only and visual-language instructions with the \emph{same} instruction template effectively improves dialogue performance. Various demos show the ability of continuous dialogue of MultiModal-GPT with humans. Code, dataset, and demo are at https://github.com/open-mmlab/Multimodal-GPT
研究の動機と目的
- 多様な視覚-言語指示に従える汎用的なマルチモーダル対話エージェントの開発を動機づける。
- 凍結した基盤モデル上でLow-rank Adaptation(LoRA)を活用して効率的なファインチューニングを実現する。
- 視覚言語データと言語のみデータの両方を訓練するための統一された指示テンプレートを開発する。
- データ品質が対話性能に与える影響を調査し、性能を低下させる可能性のあるデータセットを特定する。
- 定性的デモと評価を通じて人間に近い対話能力を継続的に示す。
提案手法
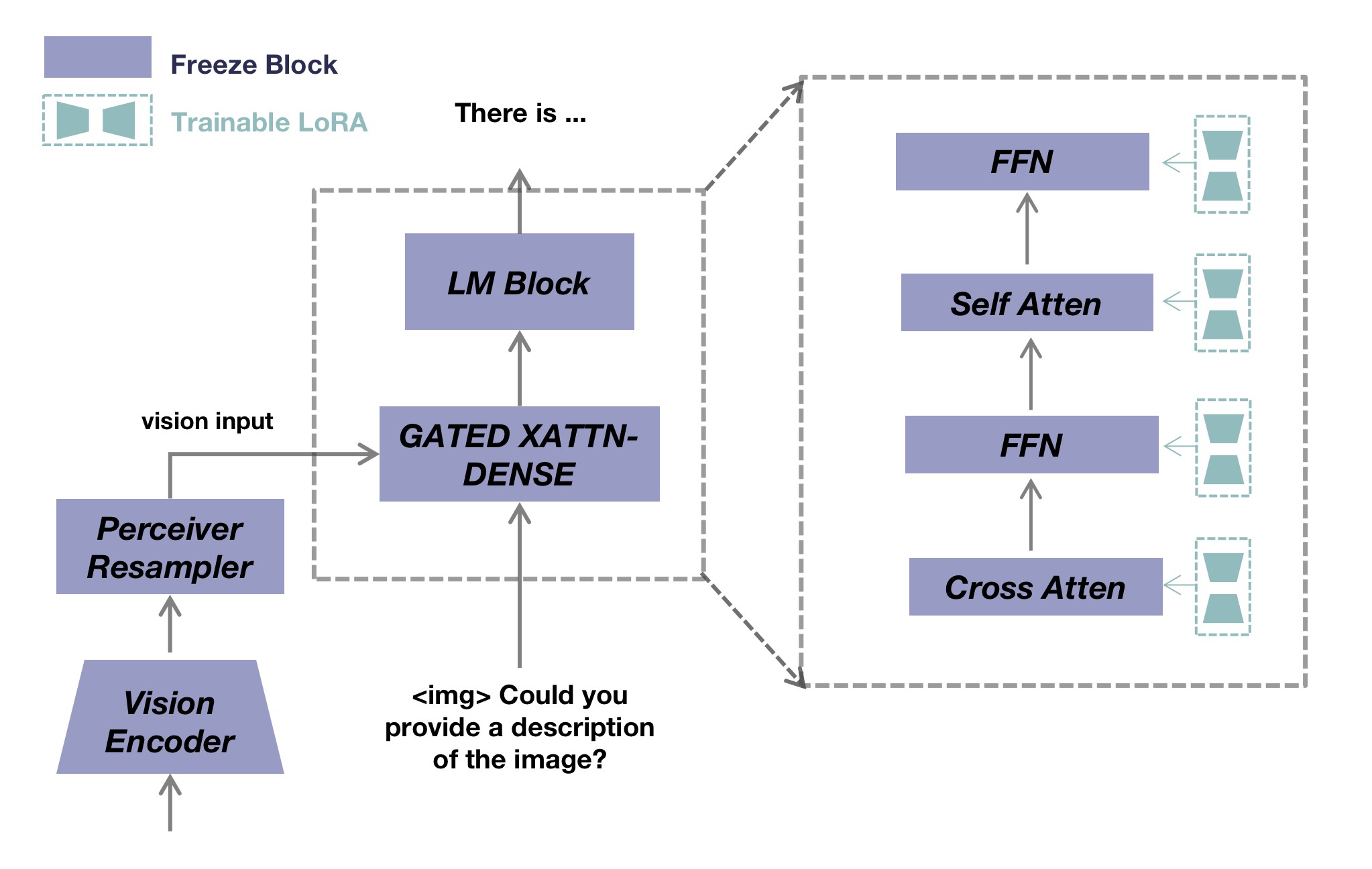
- ベースとなるアーキテクチャは OpenFlamingo を基盤とし、CLIP 由来の視覚エンコーダと LLaMA 言語デコーダへ接続する perceiver リサンプラーを用いる。
- LoRA はファインチューニングの際、言語デコーダ内の自己注意、クロスアテンション、及び前方伝播ネットワークに適用される。
- 統一された指示テンプレートを用いて言語のみデータと視覚言語データを共通の訓練フォーマットへ変換する。
- 結合訓練では言語のみ指示データ(例: Dolly 15k、Alpaca GPT4)と視覚言語指示データ(例: LLaVA、Mini-GPT4、A-OKVQA、COCO Caption、OCR VQA)を両方使う。
- 損失には応答と EOS トークンのみが寄与し、モデルは次のトークンを予測する。
- 訓練の詳細には eight A100 GPUs、 one epoch、 batch size 1 per GPU、gradient accumulation、LoRA updates every 16 iterations.
実験結果
リサーチクエスチョン
- RQ1統合された視覚-言語および言語のみ指示テンプレートは、結合訓練を通じて効果的なマルチモーダル対話を実現できるか?
- RQ2トレーニングデータの品質と構成は、マルチモーダル会話の品質と長さにどのような影響を与えるか?
- RQ3基盤モデルを凍結し、LoRA をターゲットとするコンポーネントを用いることで、頑健なマルチモーダル対話性能を得られるか?
- RQ4多様な視覚言語データセットを含めることが連続対話能力に与える影響は?
- RQ5モデルは一貫したマルチターン会話を維持し、カウント、説明、一般的な問い合わせといったタスクを実行できるか?
主な発見
- データ品質は対話性能に重大な影響を与え、短い回答のデータセットはモデルの回答を過度に簡潔にしてしまう。
- 視覚言語指示データと言語のみ指示データの両方を結合訓練すると、どちらか一方のみを用いた場合より会話能力が大幅に向上する。
- 低品質または過度に短いデータセット(例: VQA v2.0、OKVQA、GQA、CLEVR、NLVR)を除外することで、回答を急いで短くすることを防ぎ、ユーザーフレンドリーさが向上する。
- 統一された指示テンプレートは、データの両方のモダリティを効果的に活用して、マルチモーダルな理解と応答生成を高める。
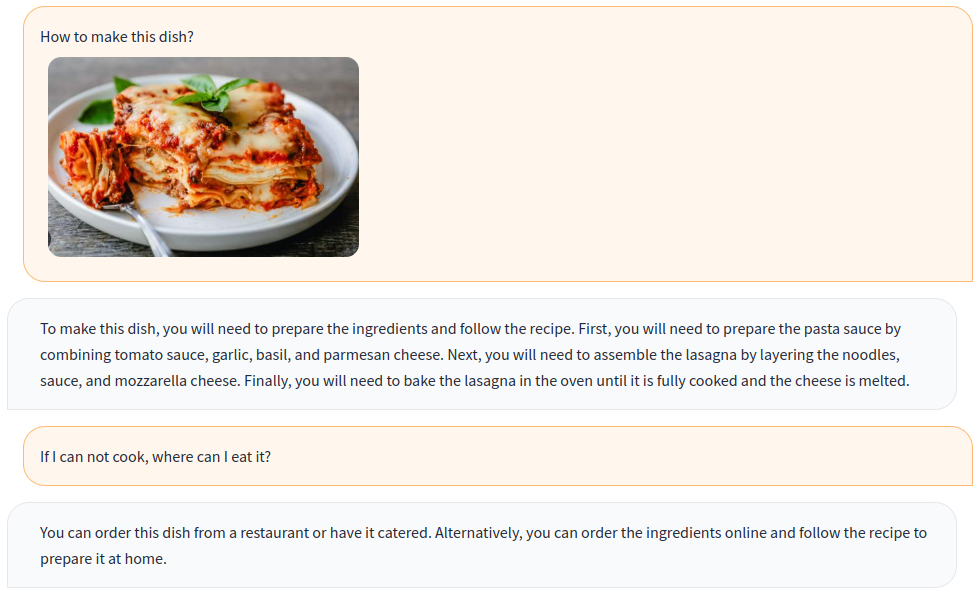
- このアプローチは、レシピ、飲食の推奨、OCR、カウントなど、さまざまなデモンストレーションタスクを通じて人間との継続的な対話を示している。
- コード、データセット、デモは https://github.com/open-mmlab/Multimodal-GPT のプロジェクトリポジトリで利用可能。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。