[論文レビュー] MultiSpeech: Multi-Speaker Text to Speech with Transformer
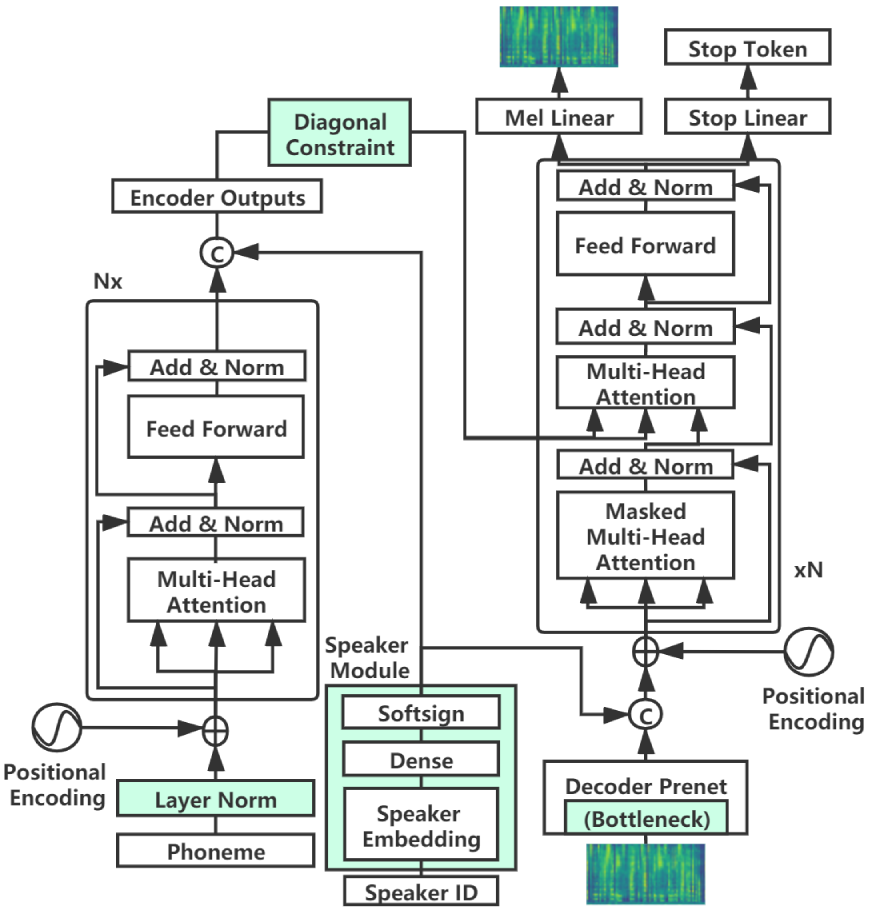
MultiSpeech は、対話者数が多い条件下でのテキスト読み上げの整列性と音質を改善する、三つの技術を備えた堅牢な多話者 Transformer TTS を導入する。これにより、テキスト駆動の予測を強化し、同時に高速な多話者 FastSpeech モデルを訓練する教師としても機能する。
Transformer-based text to speech (TTS) model (e.g., Transformer TTS~\cite{li2019neural}, FastSpeech~\cite{ren2019fastspeech}) has shown the advantages of training and inference efficiency over RNN-based model (e.g., Tacotron~\cite{shen2018natural}) due to its parallel computation in training and/or inference. However, the parallel computation increases the difficulty while learning the alignment between text and speech in Transformer, which is further magnified in the multi-speaker scenario with noisy data and diverse speakers, and hinders the applicability of Transformer for multi-speaker TTS. In this paper, we develop a robust and high-quality multi-speaker Transformer TTS system called MultiSpeech, with several specially designed components/techniques to improve text-to-speech alignment: 1) a diagonal constraint on the weight matrix of encoder-decoder attention in both training and inference; 2) layer normalization on phoneme embedding in encoder to better preserve position information; 3) a bottleneck in decoder pre-net to prevent copy between consecutive speech frames. Experiments on VCTK and LibriTTS multi-speaker datasets demonstrate the effectiveness of MultiSpeech: 1) it synthesizes more robust and better quality multi-speaker voice than naive Transformer based TTS; 2) with a MutiSpeech model as the teacher, we obtain a strong multi-speaker FastSpeech model with almost zero quality degradation while enjoying extremely fast inference speed.
研究の動機と目的
- ノイズが多く多様な話者条件下での多話者 Transformer TTS におけるテキスト読み上げの整列性を改善する。
- 合成品質を安定化・向上させるためのアーキテクチャと訓練技術を提案する。
- 高速でスケーラブルな多話者推論を実現し、FastSpeech への知識蒸留を可能にする。
提案手法
- エンコーダ-デコーダのアテンションに対する対角制約を導入し、単調な対角整列を促す。
- 位置埋め込みを追加する前に、エンコーダの音素埋め込みにレイヤーノーマライゼーションを適用して位置情報を保持する。
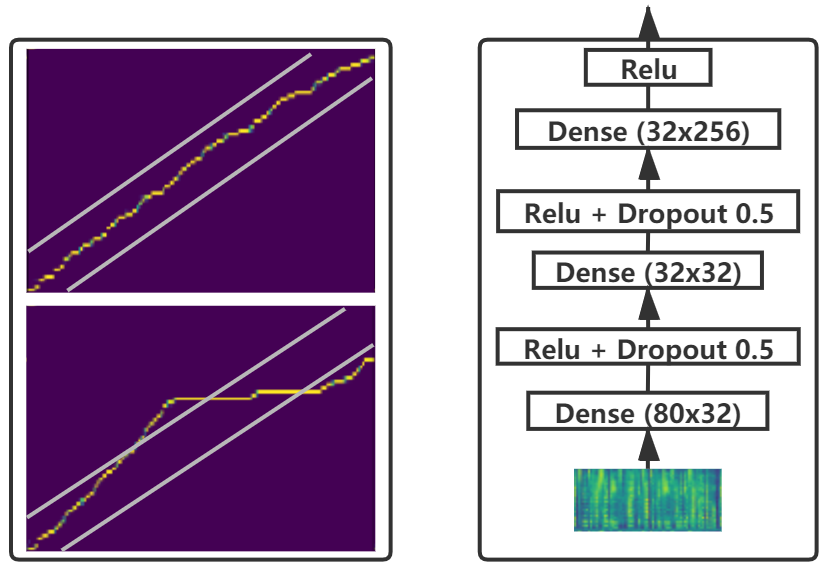
- 近接フレームのコピーを防ぎ、テキスト駆動の予測を強制する小さなデコーダ事前ネットのボトルネック(例:80-32-32-256)を使用する。
- 自己回帰推論時にアテンションのスライディングウィンドウを組み込み、整列の進行を維持する。
- MultiSpeech を VCTK、LibriTTS などの多話者データセット上で訓練し、Transformer ブロックをそれぞれ 4 層、隠れサイズ 256 で用いる。
- WaveNet をボコーダとして波形合成を行い MOS ベースの評価を実施し、教師-学生蒸留を介して FastSpeech へ拡張する。
実験結果
リサーチクエスチョン
- RQ1対角アテンション制約は多話者 Transformer TTS における整列学習を改善できるか?
- RQ2音素埋め込みに対するレイヤーノーマライゼーションは位置情報と整列品質を改善するか?
- RQ3前ネットのボトルネックは多話者 Transformer TTS におけるフレームコピーを防ぎ、テキスト駆動のデコードを促進するか?
- RQ4MultiSpeech は品質低下なく FastSpeech に対して効果的な教師となり得るか?
主な発見
| Setting | VCTK MOS (95% CI) | LibriTTS MOS (95% CI) |
|---|---|---|
| GT | 4.04±0.14 | |
| GT mel + Vocoder | 3.89±0.20 | |
| Transformer based TTS | 2.64±0.35 | |
| MultiSpeech | 3.65±0.14 | |
| GT | 4.14±0.16 | |
| GT mel + Vocoder | 3.90±0.08 | |
| Transformer based TTS | 1.49±0.09 | |
| MultiSpeech | 2.95±0.14 |
- MultiSpeech は VCTK と LibriTTS で naïve な Transformer ベースの多話者 TTS よりも高い MOS を示す。
- VCTK では MultiSpeech MOS = 3.65 (0.14)、対角率 r = 0.694;LibriTTS では MOS = 2.95 (0.14)。
- アブレーションにより対角制約、レイヤーノーマライゼーション、前ネットボトルネックのいずれかを削除すると MOS および/または対角率が低下することが示される;三つすべてを削除すると MOS は 2.64 (0.35)、r は 0.366 まで低下。
- エンコーダ入力の LN は、学習可能重み(LW)およびベースライン(それぞれ 0.506、0.637)よりも対角注意率が高い(r = 0.694)。
- MultiSpeech を教師として使用すると、マルチスピーカ FastSpeech は MOS 3.53 (0.22) で、GT 4.02 (0.09) および FastSpeech ベースライン 3.45 (0.13) よりも高く、推論が substantially faster。
- GT メル + Vocoder 上の MultiSpeech MOS は GT に近い。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。