[論文レビュー] Muse: Text-To-Image Generation via Masked Generative Transformers
Museは凍結したLLM埋め込みを条件に離散潜在空間でマスク付きトークン予測を行うテキスト→画像Transformerを導入し、最先端のFID/CLIPを達成するとともに、高速で並列デコードとゼロショット編集を可能にします。
We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing. More results are available at https://muse-model.github.io
研究の動機と目的
- 離散トークン空間でのマスクモデル化を活用し、テキストから画像への合成を進展させる。
- 事前学習済み言語モデルの埋め込みを組み込み、意味的忠実性と空間推論を向上させる。
- 拡散/自己回帰ベースラインと比較して、離散トークン上の並列デコードにより推論効率を向上させる。
- ファインチューニングなしでゼロショットの画像編集(インペインティング、アウトペインティング、マスクなし編集)を可能にする。
- CC3MとCOCOで評価し、最新の品質と整合性を実証する。
提案手法
- 画像を離散トークンへエンコードするため、デュアルVQGANトークナイザを使用(256×256でf=16、512×512でf=8)。
- 凍結されたT5-XXLテキスト埋め込みを用いて画像デコーダを条件付け、豊富な言語条件を提供する。
- テキスト埋め込みへのクロスアテンションと画像トークン間の自己アテンションを介してマスク済み画像トークンを予測する、ベースのマスク付きTransformerを使用する。
- コサインスケジュールからサンプリングされる可変マスキング率で訓練し、頑健なトークン予測と柔軟なサンプリングを奨励する。
- 低解像度トークンを高解像度トークンへ変換する超解像Transformerを続け、テキスト埋め込みで条件付ける。
- サンプリング時に分類器フリーガイダンスを適用してテキストと画像の整合性を改善し、ネガティブプロンプトを可能にする。
- ステップごとに複数のトークンを予測する反復的な並列デコードを実行し、自己回帰や拡散モデルよりも高速な推論を実現する。
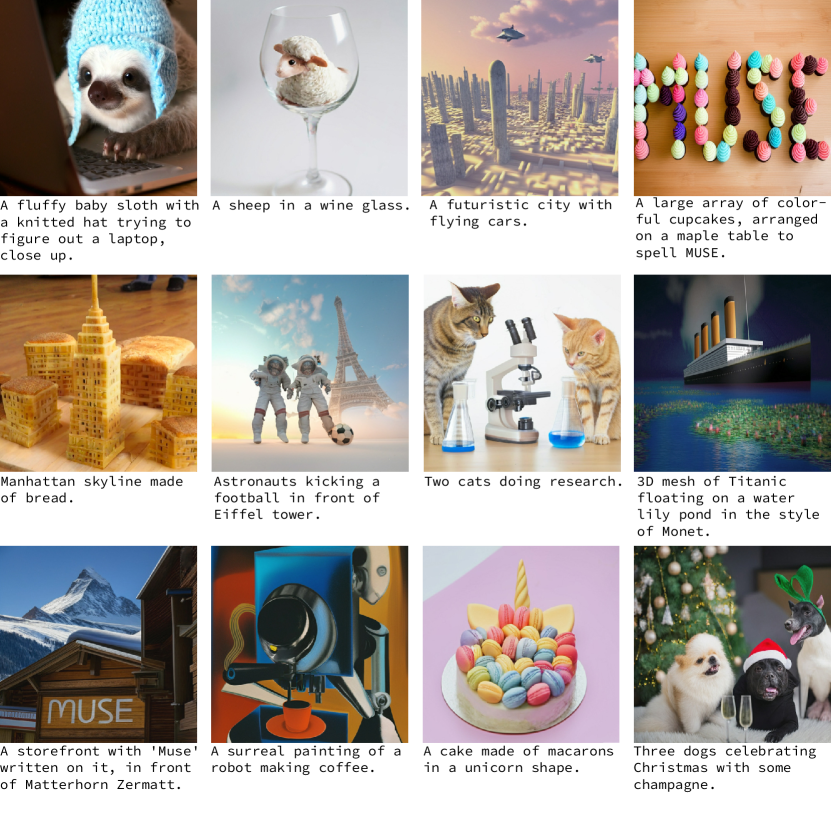
実験結果
リサーチクエスチョン
- RQ1事前学習済みLLM埋め込みを条件にしたマスク付き離散トークン画像モデルは、最先端の画像忠実度とテキスト整合性を達成できるか?
- RQ2256×256および512×512出力の場合、ベースと超解像トークン変換器の組み合わせの性能はどうか?
- RQ3ディスクリートトークンフレームワークでの並列デコードによって、拡散/自己回帰ベースラインと比べてどの程度の推論効率向上が得られるか?
- RQ4ファインチューニングなしで、ゼロショット編集(インペインティング、アウトペインティング、マスクなし編集)はどの程度実現可能か?
- RQ5高速サンプリングを維持しつつ、CC3MとCOCOにおけるFIDとCLIPの観点でMuseはどう機能するか?
主な発見
| モデル | モデルタイプ | パラメータ | FID-30K | ゼロショット | CLIP |
|---|---|---|---|---|---|
| VQGAN | 自己回帰 | 600M | 28.86 | 0.20 | - |
| ImageBART | 拡散+自己回帰 | 2.8B | 22.61 | 0.23 | - |
| LDM-4 | 拡散 | 645M | 17.01 | 0.24 | - |
| RQ-Transformer | 自己回帰 | 654M | 12.33 | 0.26 | - |
| Draft-and-revise | 非自己回帰 | 654M | 9.65 | 0.26 | - |
| Muse(base model) | 非自己回帰 | 632M | 6.8 | 0.25 | - |
| Muse(base + super-res) | 非自己回帰 | 632M + 268M | 6.06 | 0.26 | - |
- MuseはCC3Mで最先端のFIDを達成(6.06、632M base + 268M super-res tokens)。
- Muse-3BはCOCOゼロショットFID7.88、CLIP 0.32を達成。
- Museは人間の整合性プロンプトで比較可能なモデルを上回り、ユーザ研究でプロンプト-画像整合性がStable Diffusionより約2.7×有利。
- 離散トークンと並列デコードにより、拡散または自己回帰モデルより推論が大幅に高速(例:TPUv4上で256×256–512×512画像あたり0.5–1.3s)。
- 条件付きトークンリサンプリングによって、ファインチューニングや逆推定なしで直接ゼロショットの画像編集(インペインティング、アウトペインティング、マスクなし編集)を可能にする。
- 定性的な結果は基数、構図、スタイル、テキストレンダリングの強い理解を示す一方で、長い複数語フレーズや高基数には依然課題が残る。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。