[論文レビュー] Nemotron-4 340B Technical Report
Nemotron-4-340B モデルファミリ(Base、Instruct、Reward)はオープンソース化されており、整列のための合成データを強く重視し、RewardBenchで最上位スコアを達成し、標準ベンチマークでも競争力のある結果を示しています。
We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
研究の動機と目的
- 340B規模のオープンアクセス言語モデルファミリを寛容なライセンスのもとで公開する。
- 指示に従う能力、チャット機能、報酬ベースの整列における高い性能を示す。
- モデルの整列とデータ効率のための合成データ生成の有効性を示す。
- 再現性とコミュニティ利用を促進するため、訓練データ、パイプライン、コードを詳細に提供する。
提案手法
- 9T トークンのマルチストリーム事前学習(英語、マルチリンガル、コードデータを含む)。"
- RoPE、SentencePiece、グループ化クエリ注意機構、バイアス項なしのデコーダーのみの Transformer アーキテクチャ。"
- 2 段階の整列:監視付きファインチューニング(SFT)とその後の嗜好ファインチューニング(DPO および RPO)。
- 整列のための合成データを98%以上 extensively 使用。合成データ生成パイプラインと HelpSteer2 報酬データを活用。
- 弱い段階から強い段階への反復的整列により、生成機とモデル能力を継続的に改善。
- Nemotron-4-340B-Reward を高品質な報酬モデルとして公開し、整列とデータフィルタリングを指針。
実験結果
リサーチクエスチョン
- RQ1Nemotron-4-340B-Base は標準的な推論・ベンチマークタスクでオープンアクセス基準とどう比較されるか?
- RQ2大規模言語モデルの整列における合成データ生成の効果は、人間が注針したデータのみと比較してどうか?
- RQ3報酬モデリングと人間のフィードバックによる強化学習(RLHF)は指示遵守と安全性にどう影響するか?
- RQ4弱い段階から強い段階への反復的整列は、従来の単一パス整列を超えてデータ品質とモデル性能を向上させるか?
- RQ52 段階の SFT(特にコードモデルに焦点を当てた SFT の後に一般 SFT)を下流タスクにどのような影響を与えるか?
主な発見
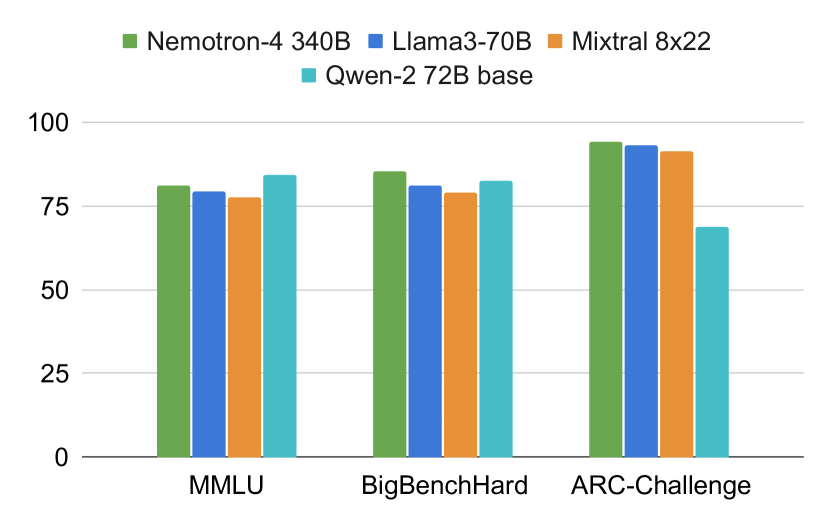
| サイズ | ARC-c | Winogrande | Hellaswag | MMLU | BBH | HumanEval | |
|---|---|---|---|---|---|---|---|
| Mistral 8x22B | 91.30 | 84.70 | 88.50 | 77.75 | 78.90 | 45.10 | |
| Llama-3 70B | 93.00 | 85.30 | ∗ | 88.00 | 79.50 | 81.30 | ∗ |
| Qwen-2 72B | 68.90 | 85.10 | 87.60 | 84.20 | 82.40 | 64.60 | |
| Nemotron-4-340B-Base 340B | 94.28 | 89.50 | 90.53 | 81.10 | 85.44 | 57.32 |
- Nemotron-4-340B-Base は公表されているオープンアクセスのベースの中で、常識推論タスクおよび BBH で最も高い精度を達成。
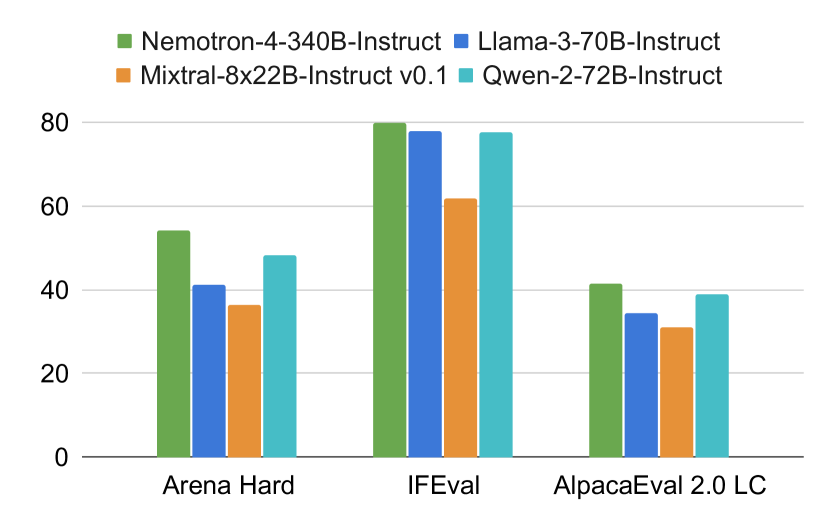
- Nemotron-4-340B-Instruct は指示遵守とチャット機能で対応する指示モデルを上回る。
- Nemotron-4-340B-Reward は RewardBench でトップの精度を達成し、公開時点でいくつかの独自モデルを凌駕。
- 整列データの 98% 以上が合成生成であり、モデル整列のための効果的な合成データ生成を示す。
- 著者は合成データパイプライン、生成プロンプト、報酬モデルを公開し、オープンな研究と再現性を支援。
- ベースモデルには 9.4B の埋め込みパラメータと 331.6B の非埋め込みパラメータを含み、9T トークンで 96 層の Transformer が訓練されている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。