[論文レビュー] Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
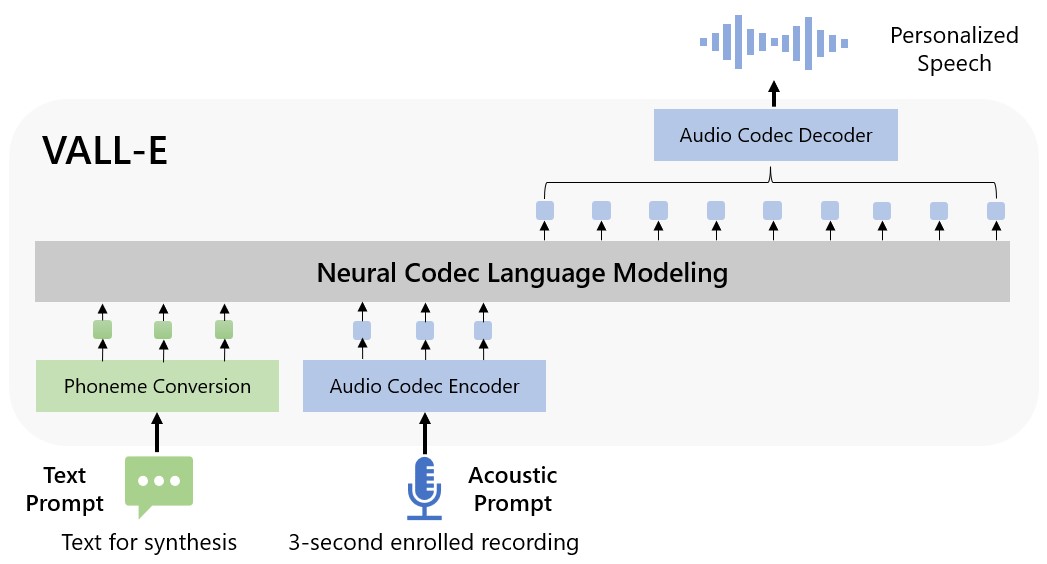
本論文は VALL-E を提案します。VALL-E は離散オーディオコーデックコードと enrolled 録音からの prompts を用いて、強い自然さと話者類似性を持つゼロショット TTS を実現する言語モデルベースの TTS システムで、データ 60k 時間で訓練されている。
We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called Vall-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. Vall-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that Vall-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find Vall-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis. See https://aka.ms/valle for demos of our work.
研究の動機と目的
- TTS訓練データを数十万時間規模に拡大し、ゼロショットの汎化性能を向上させる。
- TTSを、離散オーディオコーデックコードを中間表現として用いる条件付き言語モデリングとして扱う。
- 3秒の登録録音から未見の話者を合成するためのプロンプトベースのインコンテキスト学習を有効にする。
- 合成時に話者の感情と音響環境を保つ。
- LibriSpeechとVCTKで最先端ベースラインに対して優れたゼロショット性能を示す。
提案手法
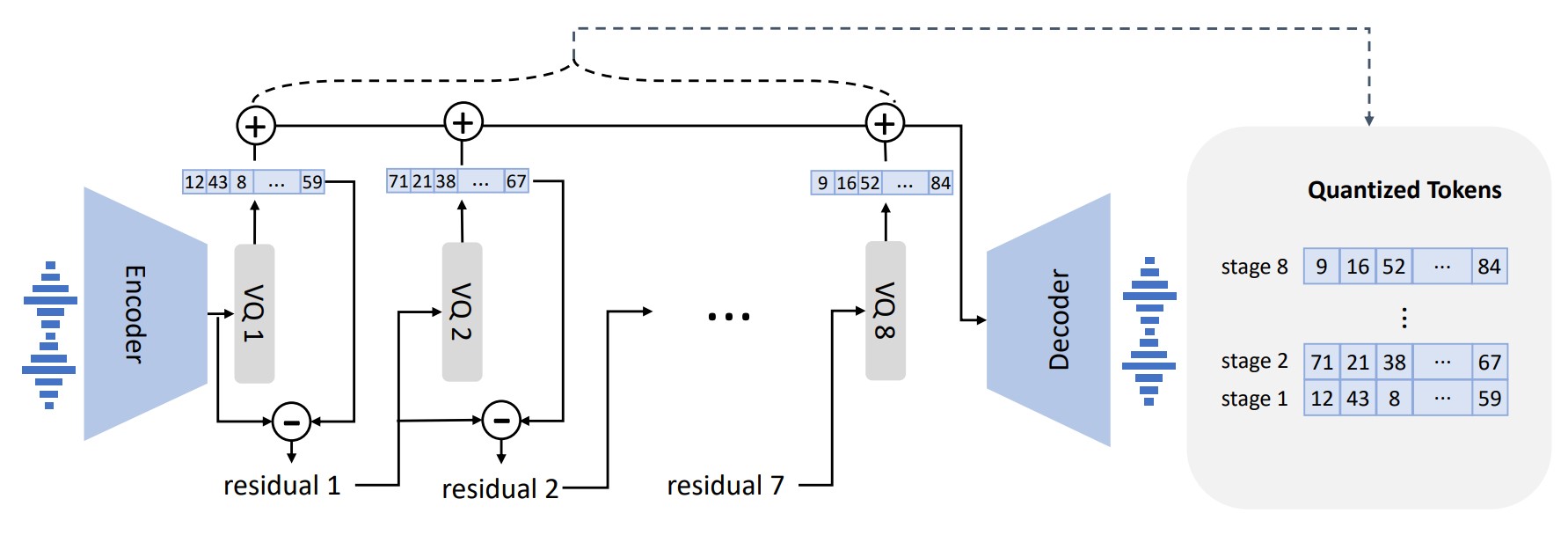
- 市販のニューラル音声コーデック(EnCodec)からの離散コードで音声を表現する。
- 発音記号プロンプトと登録録音からの音響プロンプトを用いて、音響コード行列を生成する条件付きコーデック言語モデリングとしてTTSを形成する。
- 品質と速度のバランスをとるため、最初の量子化器には自己回帰デコーダを用いた階層モデルを、以降の量子化器には非自己回帰モデルを使用する。
- 約7k話者を含むLibriLightデータの60k時間を用いて訓練し、監督にはASR生成の転写を使用する。
- 未見の話者のゼロショット合成を可能にするため、音素プロンプトと音響プロンプトを用いたプロンプトベースの推論を採用する。
- WERと話者類似度の指標、および人間評価の CMOS/SMOS を用いて評価する。
実験結果
リサーチクエスチョン
- RQ1離散的な音響コード上の条件付き言語モデリングとして合成を位置づけることで、ゼロショットTTSは達成可能か。
- RQ2半教師付き音声データのスケーリングはゼロショットTTSの性能と未見話者への一般化を改善するか。
- RQ3プロンプトベースのインコンテキスト学習はファインチューニングなしで自然で話者忠実な音声を実現できるか。
- RQ4ARとNARコンポーネントは合成品質と推論速度にどう寄与するか。
- RQ5標準TTSおよびデータセット横断評価(LibriSpeech、VCTK)におけるVALL-Eの頑健性はどうか。
主な発見
| モデル | WER | SPK |
|---|---|---|
| GroundTruth | 2.2 | 0.754 |
| GSLM | 12.4 | 0.126 |
| AudioLM* | 6.0 | - |
| YourTTS | 7.7 | 0.337 |
| VALL-E | 5.9 | 0.580 |
| VALL-E-continual | 3.8 | 0.508 |
- VALL-EはLibriSpeechおよびVCTKで、音声の自然さと話者類似性の点で最先端ゼロショットTTSベースラインを大幅に上回る。
- LibriSpeechでは、VALL-Eはベースラインに対してCMOSの +0.12、SMOSの +0.93の改善を達成;VCTKではCMOS +0.23、SMOS +0.04でグランドトゥルースを上回る。
- VALL-E-continual(継続にグランドトゥルース3sプロンプトを使用)はWERを3.8に低減し、強い話者類推性を維持します(SMOS 0.508)。
- 人間評価はSMOSでVALL-Eがグランドトゥルースに近く(0. の差はマージン内)CMOSはベースラインより改善(LibriSpeechで+0.12、VCTKで+0.23)。
- アブレーション研究は、音素プロンプトの重要な役割(WERを低減)と音響プロンプトの役割(話者類似性を高める)を示す。
- 他のスピーチ・トゥ・スピーチLMシステム(GSLM、AudioLM)と比較して、VALL-EはゼロショットTTSにおいてより高い頑健性と話者忠実性を示します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。