[論文レビュー] Noise2Music: Text-conditioned Music Generation with Diffusion Models
Noise2Musicは、スペクトログラムまたは低忠実度波形を中間表現として利用する cascaded diffusion モデルを用いて、24 kHzで30秒のテキスト条件付き音楽を生成し、セマンティック整合のために大規模言語モデルを grounding します。
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
研究の動機と目的
- 高品質なテキスト条件付き音楽生成をスケールで実現・促進する。
- 自由形式テキストプロンプトに条件付けられた30秒音楽を生成する拡散ベースのパイプラインを開発する。
- 大規模言語モデルと音楽-テキスト埋め込みを活用して、音声内の微細な意味属性をグラウンド化する。
提案手法
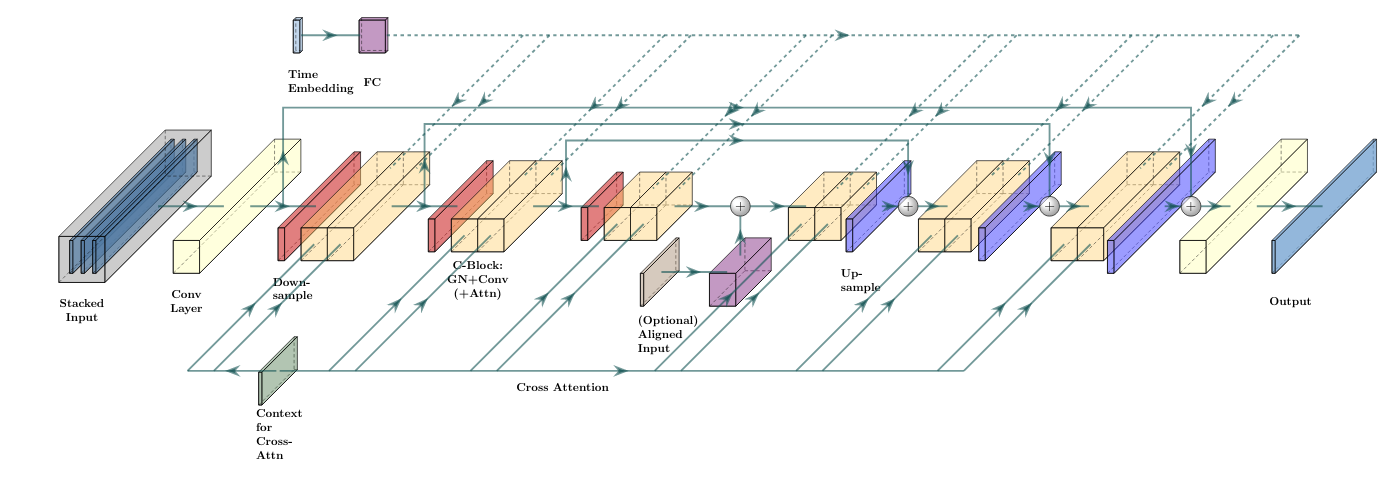
- 生成器として中間表現を出力し、最終的な高忠実度音声へと精練する cascader からなるディフュージョンモデルの連鎖を訓練する。
- 2つの中間表現を検討する: (i) ログメルスペクトログラムと (ii) 3.2 kHz 波形。
- 事前訓練済み言語モデルエンコーダ(T5)へのクロスアテンションを介してテキストでディフュージョンモデルを条件付けする。
- 16 kHz の中間音声から 24 kHz 音声を生成する最終的な超解像 Cascader を使用する。
- MuLan-LM を用いた擬似ラベリングで大規模なテキスト-音声ペアを作成し、 MuLaMCap を訓練データ多様性のために構築する。
- 4つの 1D U-Net ディフュージョンモデル(波形生成器、波形 cascader、スペクトログラム生成器、スペクトログラム vocoder)と超解像 cascader を、異なる訓練・増強スキームの下で訓練する。
- 推論時には CFG、前/後/前重み付きデノイズスケジュール、そして品質と多様性のバランスを取るための調整された確率性を用いる。
実験結果
リサーチクエスチョン
- RQ1拡散ベースのアーキテクチャは、長さ30秒の音楽クリップを任意のテキストプロンプトで高忠実度に生成できるか。
- RQ2大規模言語モデルと音楽-テキスト埋め込みによる grounding は、ジャンル、テンポ、ムード、時代といった微細な意味属性を持つ grounded な制御を音楽生成に提供するか。
- RQ3スペクトログラム vs. 波形といった中間表現は、テキスト条件付き音楽生成の品質と意味的整合にどのような影響を与えるか。
主な発見
| Dataset/Model | FAD VGG | FAD Trill | FAD MuLan | |
|---|---|---|---|---|
| MusicCaps (Agostinelli et al., 2023) | Riffusion | 13.371 | 0.763 | 0.487 |
| MusicCaps (Agostinelli et al., 2023) | Mubert (MubertAI, 2022) | 9.620 | 0.449 | 0.366 |
| MusicCaps (Agostinelli et al., 2023) | MusicLM (Agostinelli et al., 2023) | 4.0 | 0.44 | - |
| MusicCaps (Agostinelli et al., 2023) | Noise2Music Waveform | 2.134 | 0.405 | 0.110 |
| MusicCaps (Agostinelli et al., 2023) | Noise2Music Spectrogram | 3.840 | 0.474 | 0.180 |
| AudioSet-Music-Eval | Noise2Music Waveform | 2.240 | 0.252 | 0.193 |
| AudioSet-Music-Eval | Noise2Music Spectrogram | 3.498 | 0.323 | 0.276 |
| MagnaTagATune | Noise2Music Waveform | 3.554 | 0.352 | 0.235 |
| MagnaTagATune | Noise2Music Spectrogram | 5.553 | 0.419 | 0.346 |
- Noise2Music のモデルは、ジャンル、テンポ、楽器、ムード、時代といった高レベルおよび微細なプロンプト属性を反映した30秒の音声を生成する。
- 中間表現を出力する生成器と最終音声を整える cascader、そして超解像のステップを組み合わせた2段 cascaded diffusion が、高忠実度の24 kHz 出力を達成する。
- MuLan と LaMDA を用いた大規模な擬似ラベリングは、標準的なメタデータを超えたニュアンス的意味論の grounding を可能にする。
- FAD スコアと MuLan の類似度は、Riffusion や Mubert などのベースラインと比較して、複数データセットで品質と意味的整合性が競争力がある、あるいはそれを上回ることを示している。
- 人間の聴取テストでは、Noise2Music の波形が MusicLM と比較して MusicCaps プロンプトにおける意味的整合性で競合的であることが示された。
- 多語彙の擬似ラベルとテキストエンコーディング(T5)とのクロスアテンションによる grounding プロンプトは、知覚的および意味的忠実度を向上させる。
![Figure 2: We plot how $\text{FAD}_{\text{VGG}}$ and the MuLan similarity score vary as inference parameters are adjusted. The CFG parameters take values from [1, 2, 5, 10, 15], while “B”ack-heavy, “U”niform and “F”ront-heavy denoising step schedules have been applied.](https://ar5iv.labs.arxiv.org/html/2302.03917/assets/figures/ablations.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。