[論文レビュー] Non-Determinism of "Deterministic" LLM Settings
本論文は、固定入力と決定論的ハイパーパラメータを使用しても大規模言語モデルが非決定論的であり続ける方法を分析し、複数の実行とタスクにおいて生の出力と解析済みの回答にばらつきが生じることを示している。
LLM (large language model) practitioners commonly notice that outputs can vary for the same inputs under settings expected to be deterministic. Yet the questions of how pervasive this is, and with what impact on results, have not to our knowledge been systematically investigated. We investigate non-determinism in five LLMs configured to be deterministic when applied to eight common tasks in across 10 runs, in both zero-shot and few-shot settings. We see accuracy variations up to 15% across naturally occurring runs with a gap of best possible performance to worst possible performance up to 70%. In fact, none of the LLMs consistently delivers repeatable accuracy across all tasks, much less identical output strings. Sharing preliminary results with insiders has revealed that non-determinism perhaps essential to the efficient use of compute resources via co-mingled data in input buffers so this issue is not going away anytime soon. To better quantify our observations, we introduce metrics focused on quantifying determinism, TARr@N for the total agreement rate at N runs over raw output, and TARa@N for total agreement rate of parsed-out answers. Our code and data are publicly available at https://github.com/breckbaldwin/llm-stability.
研究の動機と目的
- 同一の実行を繰り返して得られるLLM応答のばらつきの程度を定量化する。
- 最終的な解析済み回答の安定性を、生のモデル出力と比較して評価する。
- 安定性、正確さ、入力長、出力長の相関を調査する。
- LLMアプリケーションのベンチマーク、デプロイ、解析パイプラインに関する洞察を提供する。
提案手法
- 複数のタスクとモデルに対して、思考過程を用いずにfew-shot promptingを用いる。
- 温度を0、top-pを1に設定し、固定種と各設定につき5回の同一実行を行う。
- BBHおよびMMLUベンチマークタスクを、GPT-3.5 Turbo、GPT-4o、Llama-3-70B-Instruct、Llama-3-8B-Instruct、Mixtral-8x7B-Instructを用いて評価する。
- 最小/中央値/最大精度、精度のばらつき、解析済みおよび生の出力に対する総一致率(TAR)などの指標で安定性を測定する。
- Spearman順位相関を用いて相関を分析し、正規性検定で非正規分布を評価する。
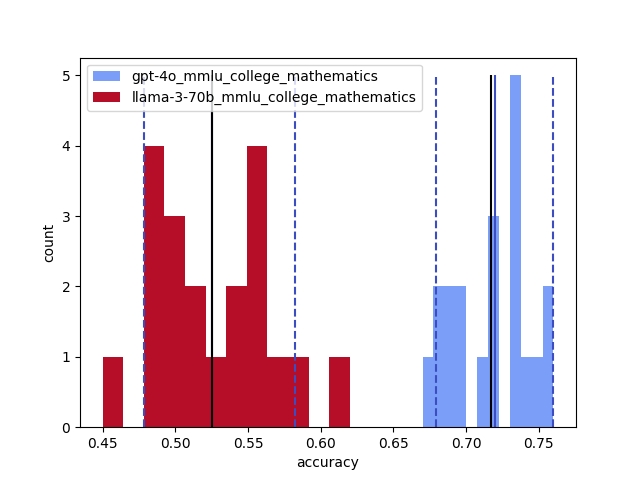
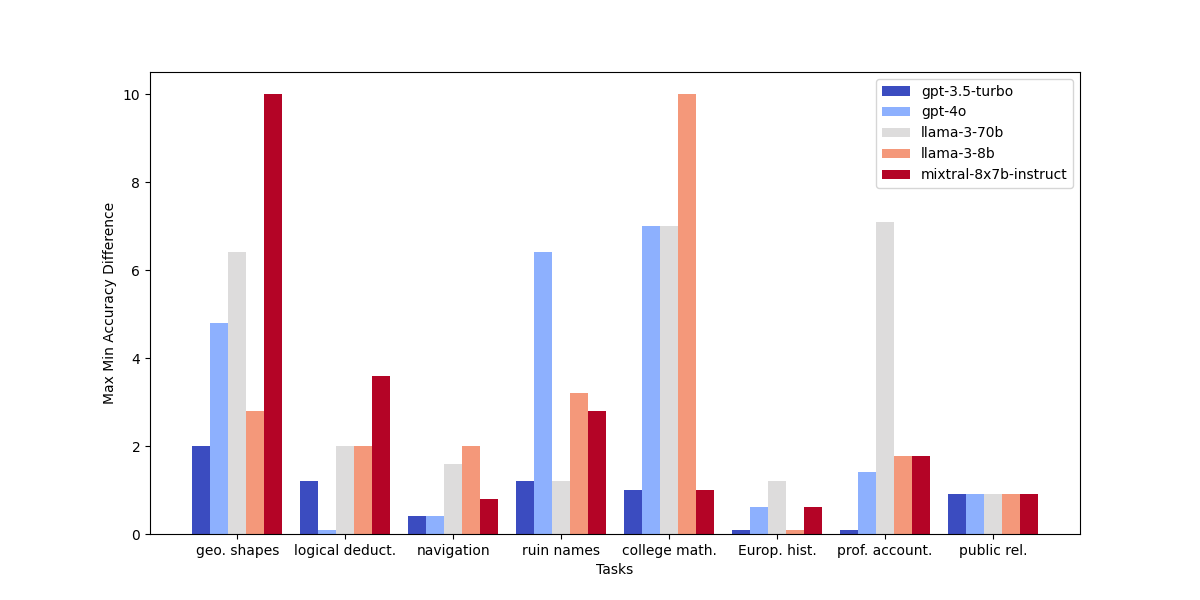
実験結果
リサーチクエスチョン
- RQ1同一の入力と設定を用いた反復実行におけるLLM最終性能のばらつきの程度はどれくらいか。
- RQ2生の出力と解析済み回答はラン runsを通じてどのように異なり、安定性にどう影響するか。
- RQ3安定性と正確さは相関するか、入力長・出力長は安定性にどう影響するか。
- RQ4安定性はタスクとモデルタイプによって異なるか。
主な発見
- 設定が決定論的であっても、生の出力レベルではモデルはめったに決定論的ではない。
- 解析済み(TARa)の安定性は生(TARr)の安定性より高いが、どのモデル/タスクでも100%ではない。
- 安定性と正確さはタスクによって異なり、大学数学は特に不安定で、欧州史は比較的安定である。
- 出力長はTARaおよびTARrの双方と負の相関を示し、長い出力は安定性を低下させることを示唆している。
- 正確さとTARaは正の相関を示す一方、TARrは正確さと明確な相関を示さない。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。