[論文レビュー] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
NV-Embedは、潜在的な注意プーリング層を用いたデコーダー専用LLMを多用途な埋め込みモデルとして訓練し、コントラスト学習時の双方向注意と、公開データを用いた2段階の指示調整プロセスを組み合わせて、MTEBおよびBEIRベンチマークでトップスコアを達成します。
Decoder-only LLM-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce NV-Embed, incorporating architectural designs, training procedures, and curated datasets to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility. For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last token embedding from LLMs. To enhance representation learning, we remove the causal attention mask of LLMs during contrastive training. For training algorithm, we introduce a two-stage contrastive instruction-tuning method. It first applies contrastive training with instructions on retrieval datasets, utilizing in-batch negatives and curated hard negative examples. At stage-2, it blends various non-retrieval into instruction tuning, which not only enhances non-retrieval task accuracy but also improves retrieval performance. For training data, we utilize the hard-negative mining, synthetic data generation and existing public available datasets to boost the performance of embedding model. By combining these techniques, our NV-Embed-v1 and NV-Embed-v2 models obtained the No.1 position on the MTEB leaderboard (as of May 24 and August 30, 2024, respectively) across 56 tasks, demonstrating the sustained effectiveness of the proposed methods over time. It also achieved the highest scores in the Long Doc section and the second-highest scores in the QA section of the AIR Benchmark, which covers a range of out-of-domain information retrieval topics beyond those in MTEB. We further provide the analysis of model compression techniques for generalist embedding models.
研究の動機と目的
- 取得と非取得タスクのためのデコーダー専用LLMsを用いた一般用途のテキスト埋め込みを高度化する。
- プーリングと表現学習を改善するためのアーキテクチャ上の革新を導入する。
- 公開データのみを用いた2段階の指示調整トレーニング手法を開発する。
- MTEBおよびBEIRベンチマークで最先端の性能を示す。
- 埋め込みモデルのシンプルさと再現性を維持する。
提案手法
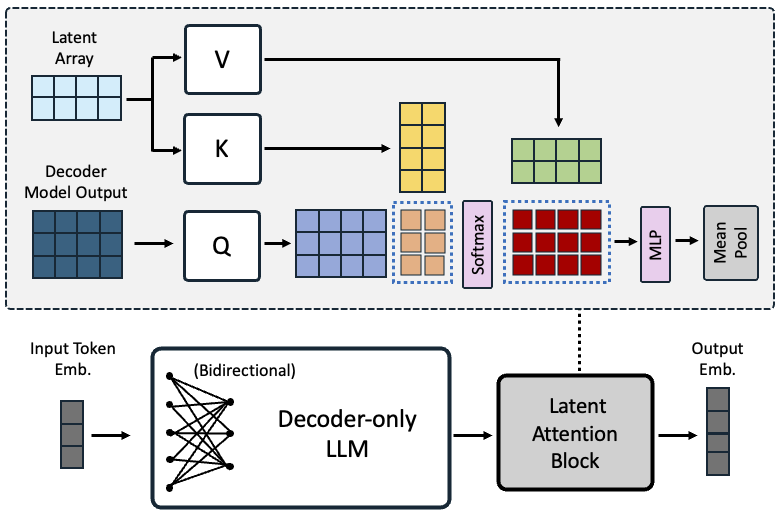
- 平均プーリングやEOSトークンプーリングの代替として、シーケンス埋め込みをプールする潜在的注意層を提案する。
- コントラスト学習時に因果的注意マスクを取り除き、双方向表現学習を可能にする。
- 2段階のコントラスト式指示調整で訓練する:第一段階ではインバッチネガティブおよび難例を含む取得データセットを用い、第二段階ではインバッチネガティブなしで非取得データをブレンドする。
- トレーニングには公開データのみを使用し、独自の合成データを回避する。
- ベースモデルはMistral-7B;LoRAを用いてエンドツーエンドで訓練し、最大512トークンのシーケンス長と128バッチサイズ(1 positive + 7 hard negatives)を使用する。
- フルMTEBベンチマーク(56タスク)およびBEIRサブセット(15の取得タスク)で評価し、先端の埋め込みモデルと比較する。
実験結果
リサーチクエスチョン
- RQ1適切なプーリング機構と訓練戦略で訓練した場合、デコーダー専用LLMは双方向埋め込みモデルを一般用途の埋め込みタスクで上回れるか?
- RQ2因果的注意マスクを取り除き潜在的注意プーリング層を使用することで、取得タスクと非取得タスクの埋め込み品質が向上するか?
- RQ3取得に焦点を当てインバッチネガティブを使用する最初の段階と、インバッチネガティブなしで非取得データをブレンドする二段階の指示調整体制からどのような利得が生じるか?
- RQ4公開データのみで訓練するだけで、独自の合成データを使用せずに最先端のMTEB/BEIRスコアを達成できるか?
主な発見
- NV-Embedは56タスクに渡って記録的なMTEBスコア69.32を達成。
- 15の取得タスクでBEIR検索スコア59.36の最高値を獲得。
- この設定ではコントラスト学習時の双方向注意が因果注意を一貫して上回る。
- 潜在的注意プーリングは、平均プーリングおよびEOSベースのプーリングより取得・分類・STSタスクを改善する。
- 2段階の指示調整(取得優先でインバッチネガティブ、次に取得/非取得をブレンド)により、取得と非取得タスクの両方の性能が向上する。
- すべての結果は公開データを用いて取得され、NV-EmbedはMistral 7Bからゼロから訓練された。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。