[論文レビュー] OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
OBELICS は、141M のマルチモーダル HTML 文書、353M の画像、115B トークンを含む、相互挿入された画像-テキスト文書のオープンなウェブ規模データセットです。これを用いて学習したオープンソースモデル(IDEFICS)は、競争力のあるマルチモーダルベンチマークを示しています。
Large multimodal models trained on natural documents, which interleave images and text, outperform models trained on image-text pairs on various multimodal benchmarks. However, the datasets used to train these models have not been released, and the collection process has not been fully specified. We introduce the OBELICS dataset, an open web-scale filtered dataset of interleaved image-text documents comprising 141 million web pages extracted from Common Crawl, 353 million associated images, and 115 billion text tokens. We describe the dataset creation process, present comprehensive filtering rules, and provide an analysis of the dataset's content. To show the viability of OBELICS, we train vision and language models of 9 and 80 billion parameters named IDEFICS, and obtain competitive performance on different multimodal benchmarks. We release our dataset, models and code.
研究の動機と目的
- ページ構造と文脈を保持する大規模でオープン、フィルタリングされたマルチモーダルWeb文書のコレクションを提供する。
- 高品質データを選別するためのフィルタリング、重複排除、プライバシー/安全対策を説明する。
- OBELICS の有用性を、Flamingo に類似したモデル(IDEFICS)を訓練し、クローズドデータセットと比較することで示す。
- マルチモーダル学習におけるオープン研究を支援するために、データセット、モデル、コードを公開する。
提案手法
- 最新の Common Crawl スナップショット(Feb 2020–Feb 2023)から英語コンテンツを収集する
- HTMLを簡略化して文書構造を維持しつつスパム/広告を削除する
- DOMベースの改行を保持しつつ相互挿入マルチモーダル文書を抽出する
- ノードレベルおよび段落レベルのフィルタリングを適用し、その後文書レベルのフィルタリングを行う
- オプトアウト画像の削除、画像の重複排除、NSFWフィルタリング、及び複数レベルのデデュプリケーションを含む責任あるフィルタリングを実施する
- OBELICS上で Flamingo に類似したモデル(IDEFICS)を訓練し、マルチモーダルベンチマークにおける画像-テキスト対のベースラインと比較する
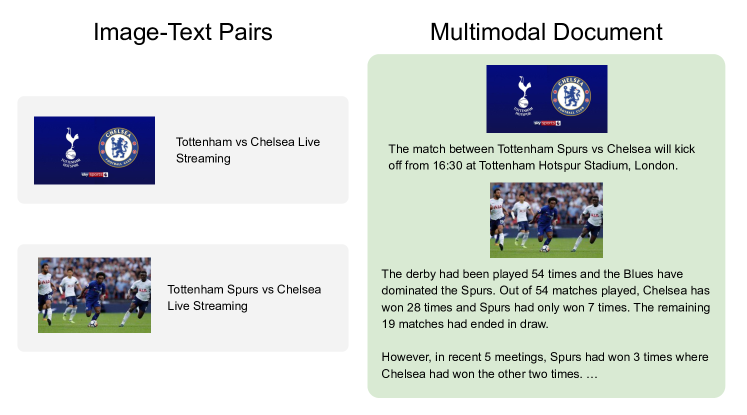
実験結果
リサーチクエスチョン
- RQ1公開公開されたウェブ規模の相互挿入画像-テキスト文書データセットが、クローズドデータセットと同等の品質と多様性を達成できるか?
- RQ2相互挿入されたマルチモーダルWeb文書(画像-テキストのペアではなく)で訓練されたモデルは、標準的なマルチモーダルベンチマークで競争力のある性能を発揮しますか?
- RQ3VQA、OCR、ヘイトスピーチ検出、マルチモーダル推論タスク全般におけるモデル性能に対するオープンデータの影響はどのようか?
- RQ4フィルタリング、重複排除、同意ベースのフィルタリングがデータ品質と下流のモデル結果にどのように影響するか?
主な発見
- OBELICS は、フィルタリングと重複排除後、141 million 文書、353 million 画像、そして 115 billion トークンを含む。
- OBELICS の画像は大半がユニークである(84.3% ユニーク画像)と、文書は比較的バランスの取れたテキスト対画像の構成を示す(文書あたりの中央値1画像、中央値677トークン)。
- 困惑度(Perplexity)分析では OBELICS のテキストは c4/mmc4/OSCAR より Wikipedia 風の品質に近く、The Pile の多様性と品質に近い。
- 定性的検査では、画像の大半がテキスト内容に関連する(90%)、46% が顔を含み、30% が書かれた内容を含む画像を含む;NSFW コンテンツは大半がフィルタリングされている。
- IDEFICS (80B) は、OBELICS と他データの混合で訓練した場合、いくつかのマルチモーダルベンチマークで Flamingo に対して競争力のある性能を発揮する;9B では OBELICS ベースのモデルが OpenFlamingo-9B のような特定のベースラインを上回る指標が示され、オープンなマルチモーダルウェブ文書の価値が強調される。
- マルチモーダル文書での訓練は、画像-テキストペアのみの訓練と比べて、より少ない画像でも同等あるいはより良い性能を達成でき、長いテキストコンテキストの利点を強調している。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。