[論文レビュー] Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models
ORGAN は SeqGAN を拡張し、対立的報酬とドメイン特有の目的報酬を強化学習フレームワークで組み合わせて、シーケンス生成(分子と音楽)を望ましい性質へ導くとともにデータらしさと多様性を維持する。安定性のため Wasserstein GAN を用いる。
In unsupervised data generation tasks, besides the generation of a sample based on previous observations, one would often like to give hints to the model in order to bias the generation towards desirable metrics. We propose a method that combines Generative Adversarial Networks (GANs) and reinforcement learning (RL) in order to accomplish exactly that. While RL biases the data generation process towards arbitrary metrics, the GAN component of the reward function ensures that the model still remembers information learned from data. We build upon previous results that incorporated GANs and RL in order to generate sequence data and test this model in several settings for the generation of molecules encoded as text sequences (SMILES) and in the context of music generation, showing for each case that we can effectively bias the generation process towards desired metrics.
研究の動機と目的
- データ分布への類似性を失うことなく、シーケンス生成器をドメイン固有の指標へと誘導する必要性を動機づける。
- 識別器に基づく報酬と明示的な目的報酬を強化学習設定で組み合わせる ORGAN を提案する。
- 離散シーケンス生成(分子および音楽)における標的特性と多様性の改善を示す。
- Wasserstein 距離と多様性維持ペナルティによる訓練の安定性を調査する。
提案手法
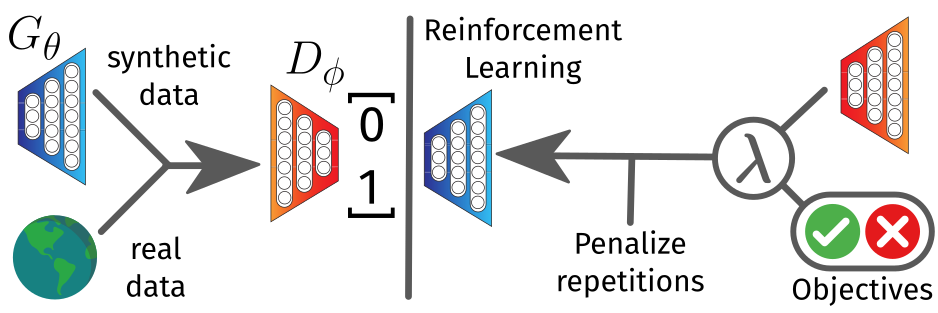
- 報酬で訓練された RL ポリシーとして生成器をモデル化することで SeqGAN をベースにする。
- Define the combined reward R(Y1:T) = λ · Dφ(Y1:T) + (1 − λ) · Oi(Y1:T).
- 部分列に対する Q を推定し方策勾配更新を導くためにモンテカルロロールアウトを使用する。
- 非一意なシーケンス(同一サンプルの繰り返し)を罰して多様性を促進する。
- 判別器訓練に Wasserstein-1 距離(WGAN)を採用してGANの挙動を安定化する。
- 実装は LSTM ベースの生成器(Gθ)と CNN ベースの識別器(Dφ)を用い、標準的な最適化(Adam)で行う。)
実験結果
リサーチクエスチョン
- RQ1ORGAN はシーケンス生成をドメイン固有の目的に向けて導くことができるか、データ分布との過度な乖離を避けられるか?
- RQ2識別器報酬と目的報酬を組み合わせることで、標的指標とサンプル多様性の両方がベースラインより改善されるか?
- RQ3Wasserstein 距離の使用が訓練の安定性とサンプル品質に与える影響はどうか?
- RQ4異なるドメイン(分子の SMILES 文字列と音楽の旋律)で、異なる目的信号を用いた場合の ORGAN の性能はどうなるか?
- RQ5標的指標とデータ尤度を同時に最大化する最適なバランスパラメータ λ はあるか?
主な発見
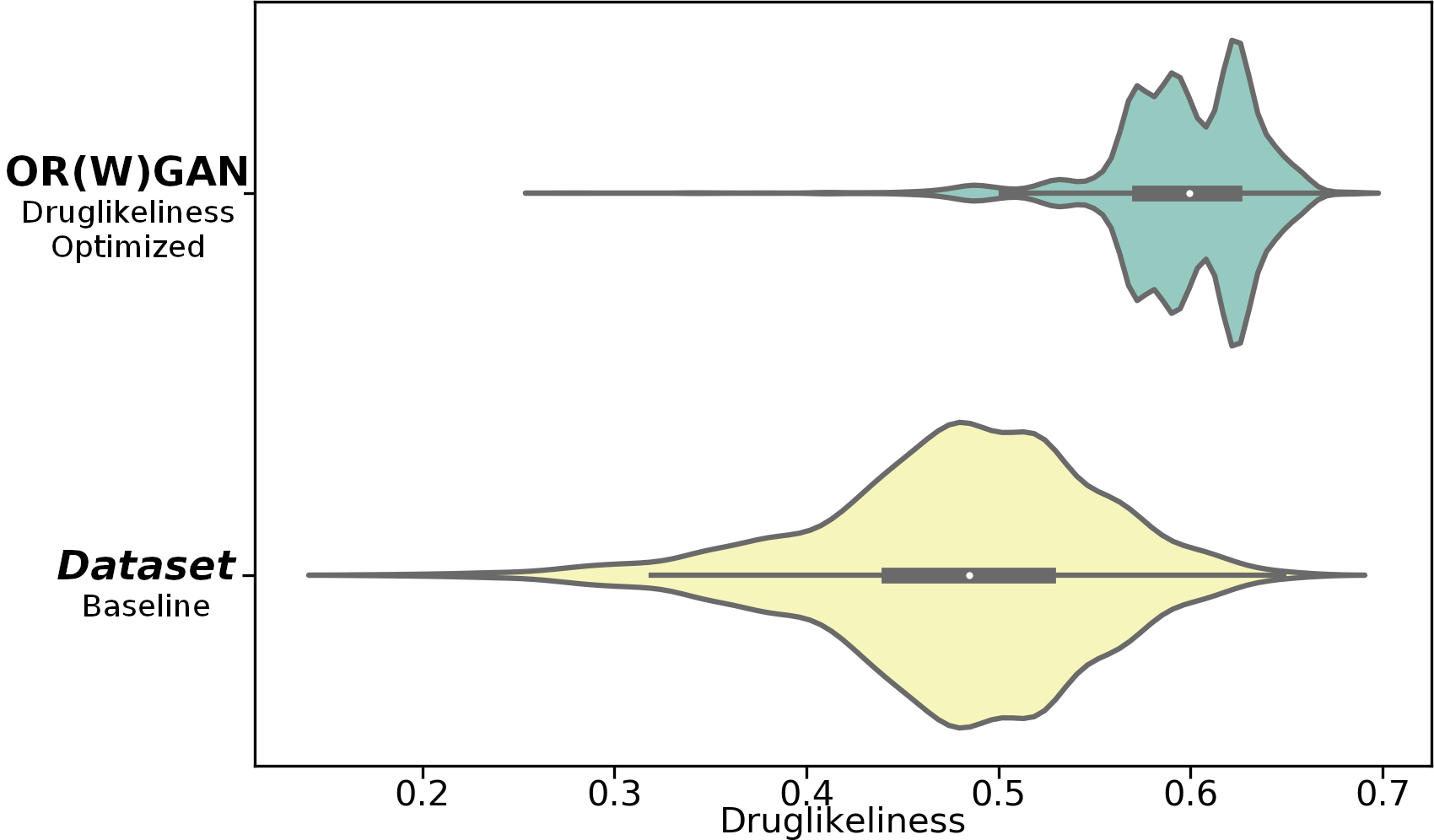
- ORGAN は分子および音楽課題において、MLE および SeqGAN に対する標的ドメイン指標を改善する。
- WGAN-ORGAN の派生は、多様性を高め、非WGAN ベースラインよりしばしば特性分布が改善される。
- 素朴な強化学習は単純なパターンに過適合しがちだが、ORGAN は敵対的指導と非一意のシーケンスペナルティを通じて多様性を保持する。
- 多目的トレーニングを交互に行う(目的を回す)と、指標全体で高い改善を生み、最良の单一目的モデルに近づく。
- λ の調整は目的の最適化とデータ尤度のトレードオフを生み、最適値はデータセットと指標によって異なる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。