[論文レビュー] Offsite-Tuning: Transfer Learning without Full Model
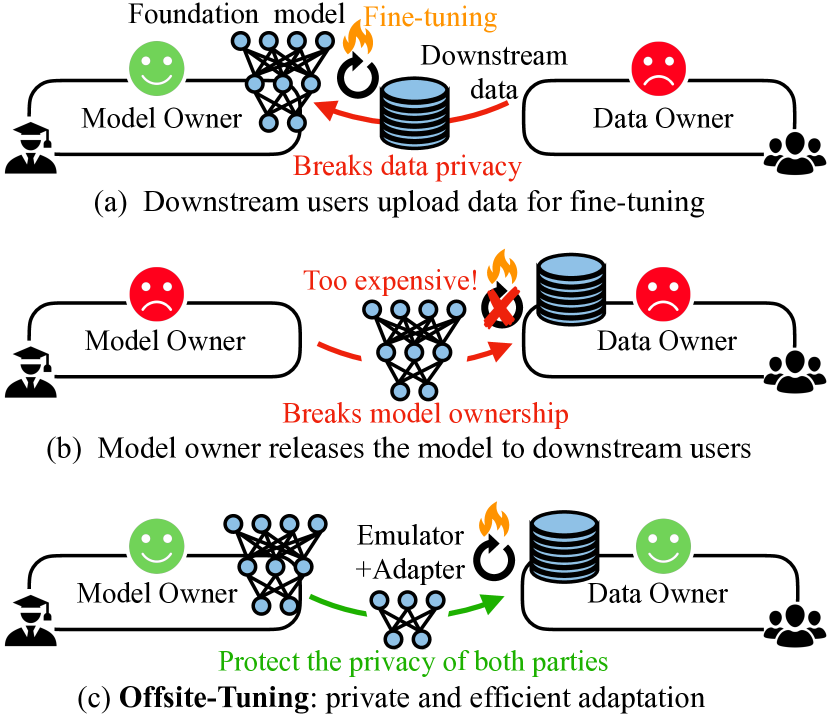
Offsite-Tuning は、全モデルウェイトへアクセスせずに、billion-parameter foundation models を下流データへ適応させることを可能にする。学習可能なアダプタとデータ所有者と共有される損失圧縮済みエミュレータを用い、プライバシーを保ちながら、fullファインチューニングと比較して精度をほぼ維持しつつ、より効率的なファインチューニングを実現する。
Transfer learning is important for foundation models to adapt to downstream tasks. However, many foundation models are proprietary, so users must share their data with model owners to fine-tune the models, which is costly and raise privacy concerns. Moreover, fine-tuning large foundation models is computation-intensive and impractical for most downstream users. In this paper, we propose Offsite-Tuning, a privacy-preserving and efficient transfer learning framework that can adapt billion-parameter foundation models to downstream data without access to the full model. In offsite-tuning, the model owner sends a light-weight adapter and a lossy compressed emulator to the data owner, who then fine-tunes the adapter on the downstream data with the emulator's assistance. The fine-tuned adapter is then returned to the model owner, who plugs it into the full model to create an adapted foundation model. Offsite-tuning preserves both parties' privacy and is computationally more efficient than the existing fine-tuning methods that require access to the full model weights. We demonstrate the effectiveness of offsite-tuning on various large language and vision foundation models. Offsite-tuning can achieve comparable accuracy as full model fine-tuning while being privacy-preserving and efficient, achieving 6.5x speedup and 5.6x memory reduction. Code is available at https://github.com/mit-han-lab/offsite-tuning.
研究の動機と目的
- Motivate privacy and efficiency challenges in fine-tuning proprietary foundation models for downstream tasks.
- Propose a framework that enables fine-tuning without exposing full model weights or data.
- Demonstrate applicability to both language and vision foundation models across standard benchmarks.
提案手法
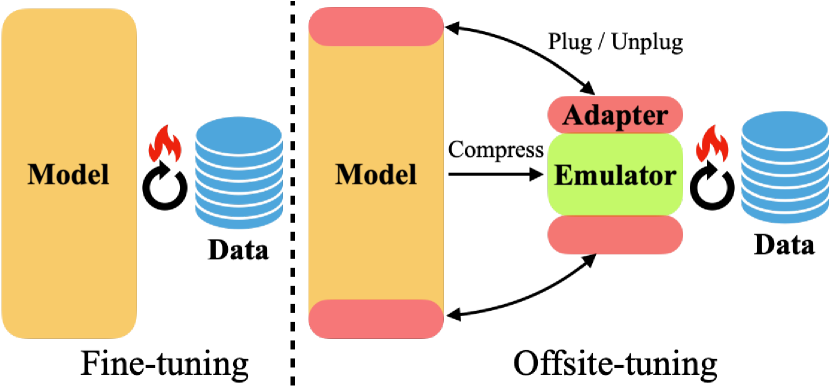
- Split the foundation model into a small trainable adapter (A) and a frozen remainder (E); apply lossy compression to E to create an emulator (E*).
- Supply [A, E*] to the data owner who fine-tunes A using approximate gradients from E*.
- Return the updated adapter A' to the model owner, who injects it into the full model to yield M' = [A', E].
- Explore layer-drop based emulator compression by dropping middle layers of E while retaining first and last layers; optionally distill E* from E when resources permit.
- Design adapters as a sandwich M = A1 ∘ E ∘ A2 to capture both shallow and deep layer updates, improving transfer performance over updating only the top or bottom layers.
- Combine Offsite-Tuning with parameter-efficient fine-tuning techniques (Adapter, LoRA, BitFit) by applying these methods on the adapter layers to further reduce trainable parameters.
実験結果
リサーチクエスチョン
- RQ1Can a small adapter plus a compressed emulator enable effective fine-tuning of billion-parameter foundation models without sharing full model weights or data?
- RQ2How should the emulator be compressed to balance gradient usefulness for adapters and protection of model ownership?
- RQ3Does the plug-in (adapter-trained on the data owner’s data, then plugged into the full model) approach approach full fine-tuning performance across language and vision tasks?
- RQ4What are the efficiency gains (speed, memory) when using Offsite-Tuning, and how do they scale with model size and compression strategy?
- RQ5How does Offsite-Tuning interact with existing parameter-efficient fine-tuning methods?
主な発見
- Offsite-Tuning achieves comparable plug-in performance to full fine-tuning on several language and vision tasks while preserving privacy (no access to full model weights).
- Layer-drop based emulator compression provides the best balance between performance and privacy, with a visible gap between emulator and plug-in performance that preserves model ownership.
- Distillation of the emulator further improves plug-in performance versus emulator performance, improving outcomes on specific models (e.g., OPT-1.3B and GPT2-XL).
- Combining Offsite-Tuning with parameter-efficient fine-tuning methods (Adapter, LoRA) reduces trainable parameters while maintaining or improving plug-in performance; BitFit tends to underperform relative to full fine-tuning in some cases.
- Efficiency gains are substantial: up to 6.5x throughput speedup and 5.6x memory reduction when combined with LoRA on single-GPU hardware.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。