[論文レビュー] OLMo: Accelerating the Science of Language Models
OLMo は完全に公開された 1B/7B(およびそれ以上)のデコーダー専用 Transformer 言語モデルフレームワークで、重み、データ、訓練/推論コード、評価ツールを公開して LM のオープンな科学的研究を可能にします。
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, we have built OLMo, a competitive, truly Open Language Model, to enable the scientific study of language models. Unlike most prior efforts that have only released model weights and inference code, we release OLMo alongside open training data and training and evaluation code. We hope this release will empower the open research community and inspire a new wave of innovation.
研究の動機と目的
- 科学的研究のための終端から end-to-end LM 開発アーティファクト(データ、コード、モデル、評価)を公開してオープン研究を促進する。
- 事前訓練データ、アーキテクチャ、訓練選択が能力、バイアス、リスクに与える影響を厳密に分析できるようにする。
- オープンモデルと最先端のクローズドモデルを比較する拡張可能なフレームワークを提供し、結果の再現性を可能にする。
提案手法
- ノーバイアス、非パラメトリック層正規化、SwiGLU、RoPE、修正BPEトークナイザを備えたデコーダー専用 Transformer アーキテクチャを採用。
- Dolma を事前訓練コーパスとして、少なくとも 2 兆トークンで 1B および 7B の複数モデルサイズを事前訓練(65B は訓練中)。
- 混合精度を用いた AMD/NVIDIA ハードウェアで訓練をスケールさせるために ZeRO + FSDP 分散訓練を使用。
- 中間チェックポイント、訓練ログ、完全なデータとツールチェーンを Apache 2.0 の下で公開。Dolma および WIMBD ツールを含む。
- Catwalk を下流タスクの評価と Paloma を perplexity の評価に使用;アーキテクチャとデータ選択を導くためのループ内訓練アブレーションを実施。
- 指示調整とオープン Instruct データを用いた Direct Preference Optimization (DPO) による適応を実演。
実験結果
リサーチクエスチョン
- RQ1オープンで完全に公開された LM インフラストラクチャ(データ、重み、訓練/評価コード)が LM の科学的研究をどのように可能にするか?
- RQ2モデル設計の選択(バイアス項、層正規化、活性化、RoPE)が訓練の安定性とスループットにどのような影響を与えるか?
- RQ3大規模な公開事前訓練データセット(Dolma)が、タスクと perplexity ドメイン全体でモデルの能力とデータドメインカバレッジにどのように影響するか?
- RQ4指示調整と整合性(DPO)がオープンベースのモデルの安全性と下流タスクの性能に与える影響は?
- RQ5データを除去して評価した場合、ゼロショットの下流タスクおよび intrinsic perplexity 評価において、オープンモデルは現代のベースラインとどう比較されるか?
主な発見
| モデル | arc_challenge | arc_easy | boolq | hellaswag | openbookqa | piqa | sciq | winogrande | avg |
|---|---|---|---|---|---|---|---|---|---|
| Falcon | 47.5 | 70.4 | 74.6 | 75.9 | 53.0 | 78.5 | 93.9 | 68.9 | 70.3 |
| OLMo-7B | 48.5 | 65.4 | 73.4 | 76.4 | 50.4 | 78.4 | 93.8 | 67.9 | 69.3 |
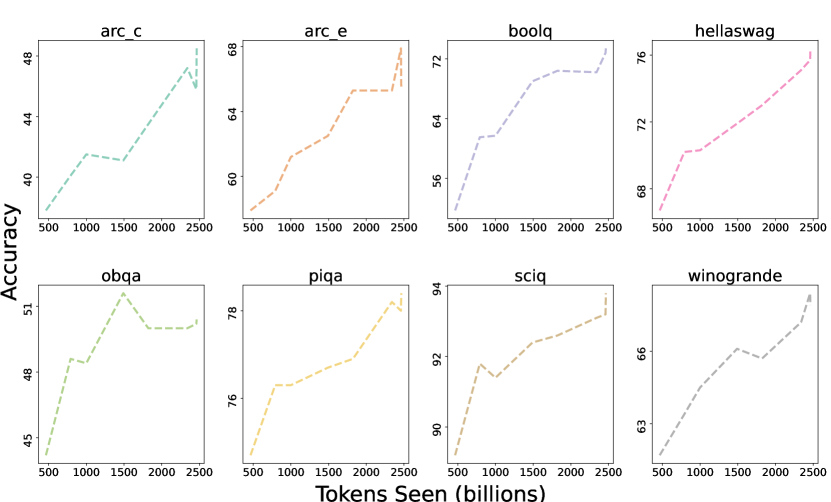
- OLMo-7B は、ゼロショット評価で 8 つのコア下流タスクにおいて公開済みの 7B スケールモデルと競合している。
- OLMo-7B は学習トークン数が増えると性能が改善され、最終段階で学習率がゼロに減衰すると顕著なゲインが見られる。
- 指示調整と DPO の適応は安全性とタスク指標を大幅に改善し、他のチャット系バリアントを上回ることが多く、ベースモデルの有用性を示す。
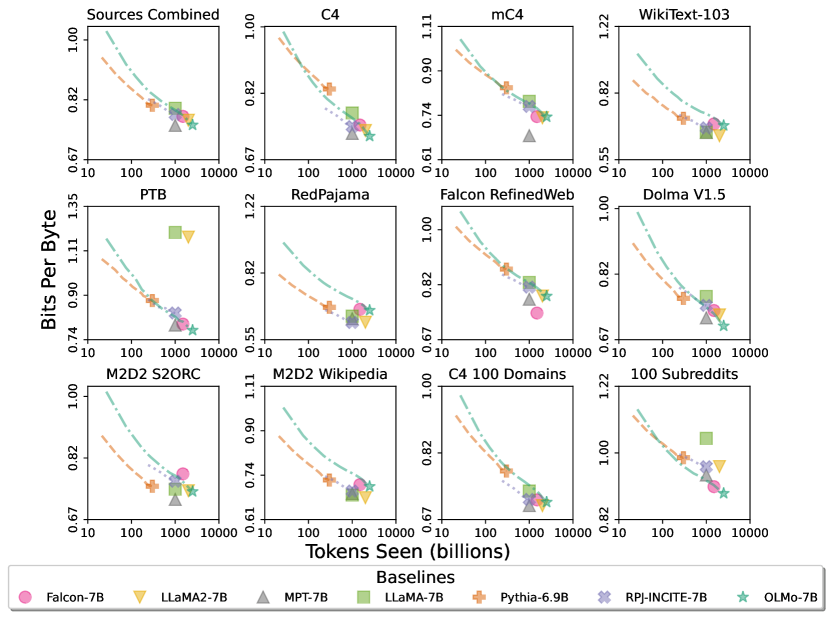
- Paloma ベースの intrinsic 評価は、事前訓練データからデ contaminating されていない 11 のデータソースに対して競争力のある perplexity の適合を示す。
- 適応結果は、データセットの整合性やテストの混入の影響により、調整済みの同業他社(例:Tülu 2)と比較してギャップがあることを示す可能性がある。
- 中間のチェックポイントとデータパイプラインの公開は、研究コミュニティによる再現性とさらなる実験を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。