[論文レビュー] OLMoE: Open Mixture-of-Experts Language Models
OLMoEは、完全に公開されたスパース Mixture-of-Experts 言語モデル(アクティブ/総計1.3B/6.9B)を導入し、5.1Tトークンで事前学習され、同様の規模のオープンMoEの中で最先端の性能を達成し、より大きな密結合モデルと競合する結果を示します。 また、指示調整および好み調整版を含み、すべての成果物を公開します。
We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
研究の動機と目的
- オープンでコスト効率の高い言語モデリングをスパースMoEで推進する。
- MoE設計の選択肢を体系的に検討する(粒度、ルーティング、共有など)。
- ウェイト、データ、コード、ログを公開して再現性と分析を可能にする。
- MoEsが同程度のアクティブパラメータを持つ密結合モデルを上回り、より大きなLMと競合できることを示す。
提案手法
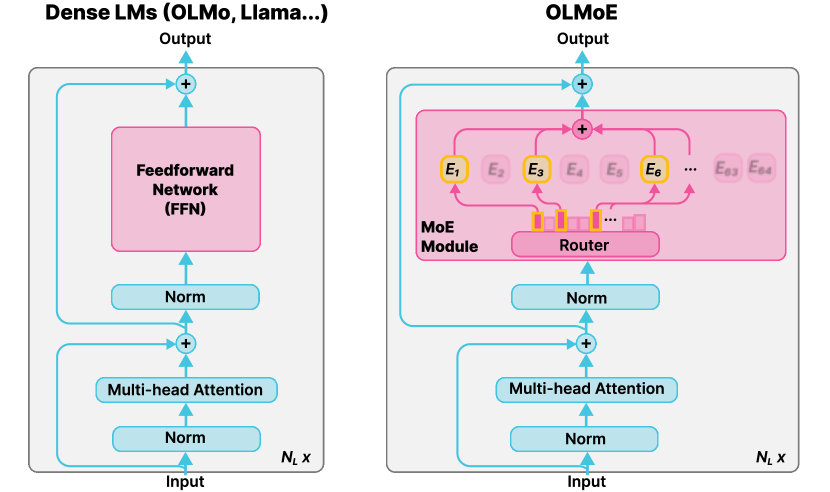
- 64個の小型エキスパートを各層に配置し、デコーダーのみのMoE言語モデルを構成する。
- 総計6.9Bパラメータのうち1.3Bアクティブパラメータを得るためにゼロから学習する。
- 入力トークンごとに8つのエキスパートをアクティブ化するためのドロップレスルーティングを使用する。
- 適切なときにロードバランシング損失とルーターz損失で学習を最適化する。
- 混合データセット(OLMoE-Mix)を界総計5.133Tトークンで事前学習し、データセット品質フィルターを適用する。
- 命令調整と好み調整を適用してInstruct版を作成する。

実験結果
リサーチクエスチョン
- RQ1固定されたアクティブパラメータ予算の下で最も良い性能をもたらすMoE設計の鍵となる選択は何か。
- RQ2MoEルーティング(トークンベース vs エキスパートベース)は学習の安定性とスループットにどのように影響するか。
- RQ3類似のアクティブパラメータを持つ密モデルと比較して、スパースMoE学習はスピードアップやコストの利点を提供するか。
- RQ4オープンMoEモデルが制約されたリソースと完全公開成果物で競争力のあるまたは最先端の結果を達成できるか。
主な発見
- OLMoE-1B-7Bは、同様のアクティブパラメータを有するすべてのオープンモデルを上回り、複数のベンチマークでより大きな密結合LMに対抗する。
- 粒度の細かい64個の小型エキスパートと各トークンあたり8つのアクティブを使うMoEは強力な性能向上をもたらす。
- ドロップレスのトークンベースルーティングは、実験設定下でエキスパートベースのルーティングを上回る。
- ウェイト、データ、コード、ログをオープン公開することで、再現とさらなる研究を可能にする全体ワークフローを実現した。
- Instruct調整済みのOLMoE-1B-7B-Instructは、標準ベンチマーク(MMLU、GSM8k、HumanEval など)でいくつかの大型指示モデルを上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。