[論文レビュー] On Efficient Training of Large-Scale Deep Learning Models: A Literature Review
タスクやモデルに依存しない、一般的な加速技術を大規模モデル訓練に適用するタスクフリー・モデルフリーの調査を分類する。
The field of deep learning has witnessed significant progress, particularly in computer vision (CV), natural language processing (NLP), and speech. The use of large-scale models trained on vast amounts of data holds immense promise for practical applications, enhancing industrial productivity and facilitating social development. With the increasing demands on computational capacity, though numerous studies have explored the efficient training, a comprehensive summarization on acceleration techniques of training deep learning models is still much anticipated. In this survey, we present a detailed review for training acceleration. We consider the fundamental update formulation and split its basic components into five main perspectives: (1) data-centric: including dataset regularization, data sampling, and data-centric curriculum learning techniques, which can significantly reduce the computational complexity of the data samples; (2) model-centric, including acceleration of basic modules, compression training, model initialization and model-centric curriculum learning techniques, which focus on accelerating the training via reducing the calculations on parameters; (3) optimization-centric, including the selection of learning rate, the employment of large batchsize, the designs of efficient objectives, and model average techniques, which pay attention to the training policy and improving the generality for the large-scale models; (4) budgeted training, including some distinctive acceleration methods on source-constrained situations; (5) system-centric, including some efficient open-source distributed libraries/systems which provide adequate hardware support for the implementation of acceleration algorithms. By presenting this comprehensive taxonomy, our survey presents a comprehensive review to understand the general mechanisms within each component and their joint interaction.
研究の動機と目的
- タスクやアーキテクチャに依存しない、大規模モデル訓練の一般的な加速技術を要約する。
- データ中心、モデル中心、最適化中心、予算配分、システム中心の構成要素に訓練プロセスを分解する分類法を提供する。
- 構成要素間の相互作用を分析し、効率的な訓練パラダイムの今後の方向性を議論する。
提案手法
- 一般的な勾配ベースの更新式を5つの構成要素(データ、モデル、最適化、予算、システム)に分解する。
- データ中心、モデル中心、最適化中心、予算制約下の訓練、システム中心の観点で既存の加速技術を分類する5分野の分類法を提案する。
- データ正則化、データサンプリング、カリキュラム学習、アーキテクチャ圧縮、初期化、学習率およびバッチサイズ戦略、分散システムフレームワークなどの技術をレビュー・統合する。
- 実践的な考慮事項、長所・短所、および構成要素間の相互作用を議論する。
- アーキテクチャ間・ドメイン横断に適用可能な一般的加速パラダイムの将来の研究方向性を概説する。
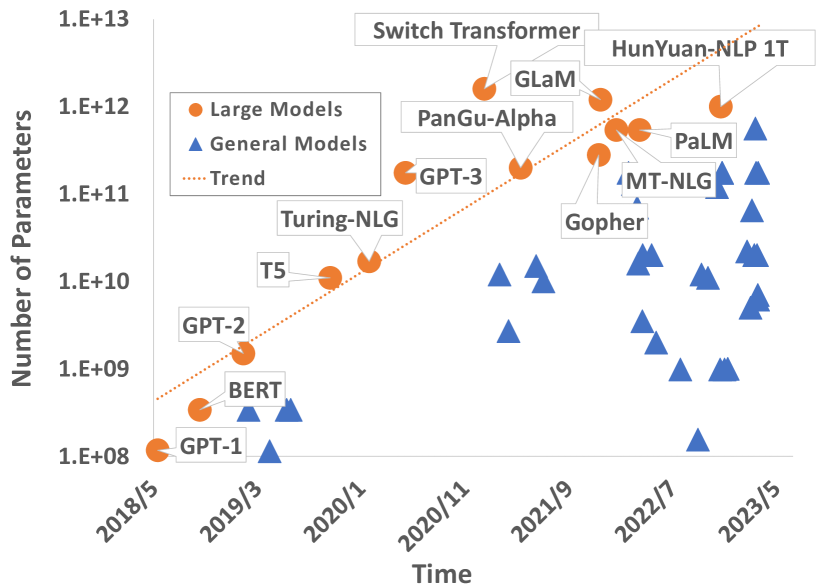
実験結果
リサーチクエスチョン
- RQ1大規模ディープラーニングモデルの訓練を加速する、一般的でアーキテクチャやタスクに依存しない手法は何か?
- RQ2訓練プロセスをデータ中心、モデル中心、最適化中心、予算・資源中心、システム中心の構成要素に分解して、加速戦略を導くにはどうするか?
- RQ3実践的な設定におけるこれらの構成要素間のトレードオフと相互作用は何か?
- RQ4モデルとデータセットの規模が拡大し続ける中で、効率的な訓練を維持する将来の方向性は何か?
主な発見
- 5つの視点(データ、モデル、最適化、予算配分、システム)に跨る訓練加速技術の総合的な分類法。
- データ中心の手法は、データ拡張、正則化、サンプリング、カリキュラム学習を通じて、精度を維持しつつ計算量を削減する。
- モデル中心の手法は、アーキテクチャの効率化、圧縮、より良い初期化を狙い、訓練コストを削減する。
- 最適化中心の戦略は、学習率スケジュール、大規模バッチ訓練、堅牢な目的関数を強調し、効率と汎化を向上させる。
- 予算制約下の訓練は、制限の中で性能を最大化するためのリソース制約のあるシナリオに対応する。
- システム中心のアプローチは、分散フレームワークとハードウェア対応の実装について、スケーラブルな訓練を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。