[論文レビュー] On Large Visual Language Models for Medical Imaging Analysis: An Empirical Study
この論文は、医用画像分類タスク(脳MRI、ALL-IDB2顕微鏡画像、胸部X線COVID)におけるゼロショットおよびファewショットの視覚言語モデルを経験的に評価し、CNNベースラインと比較してゼロショット/ファewショットの能力と prompting 戦略を強調している。
Recently, large language models (LLMs) have taken the spotlight in natural language processing. Further, integrating LLMs with vision enables the users to explore emergent abilities with multimodal data. Visual language models (VLMs), such as LLaVA, Flamingo, or CLIP, have demonstrated impressive performance on various visio-linguistic tasks. Consequently, there are enormous applications of large models that could be potentially used in the biomedical imaging field. Along that direction, there is a lack of related work to show the ability of large models to diagnose the diseases. In this work, we study the zero-shot and few-shot robustness of VLMs on the medical imaging analysis tasks. Our comprehensive experiments demonstrate the effectiveness of VLMs in analyzing biomedical images such as brain MRIs, microscopic images of blood cells, and chest X-rays.
研究の動機と目的
- 大規模視覚言語モデル(VLMs)の医用画像分類タスクにおけるゼロショットおよびファewショットのロバスト性を評価する。
- 三つのデータセット(BTD、ALL-IDB2、CX-Ray)でVLMとCNNベースラインを比較する。
- 生物医用画像における prompting 戦略とそれがVLMの性能に与える影響を分析する。
提案手法
- ファイブつのVLM(BiomedCLIP、OpenCLIP、OpenFlamingo、LLaVA、ChatGPT-4)と二つのCNNベースライン(CNN、ResNet-18)をファインチューニングなしで評価する。
- ほとんどのVLMにはゼロショット promptingを、OpenFlamingoにはデモンストレーション画像を用いたファewショット promptingを適用する。
- 各データセットでのテスト正解率を報告し、データセット間の平均を算出する。
- CLIPベースモデルを改善するためのデータセット特有の prompts(例:データセットごとに豊富な記述的 prompts)を記述する。
- prompting 戦略(単一ステップ対多段階、デモンストレーションの選択)とそれが性能に与える影響を議論する。
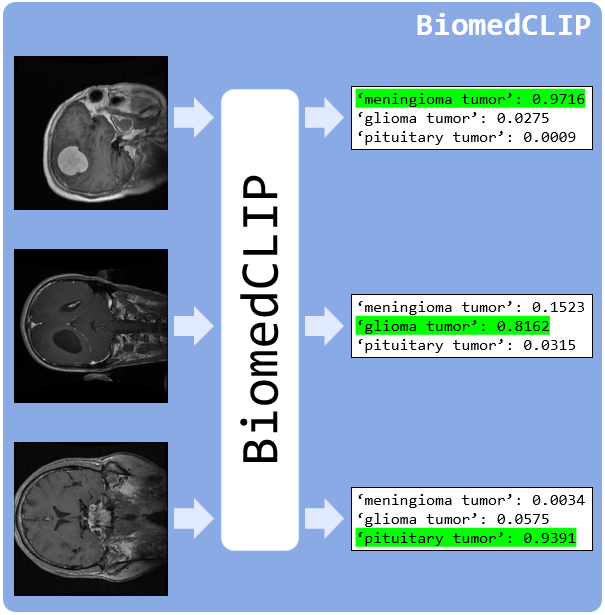
実験結果
リサーチクエスチョン
- RQ1タスク固有の微調整なしで、ゼロショットVLMは医用画像分類タスクでどの程度機能するか?
- RQ2ファewショット prompting は医用画像のVLM分類精度を改善するか、どの条件下で効果があるか?
- RQ3脳MRI、ALL-IDB2、CX-RayデータセットでVLMはCNNベースのモデルと比較してどうか?
- RQ4この領域でCLIPベースモデルの最適な精度を生み出す prompting 戦略は何か?
- RQ5医用画像にVLMを適用する際の限界と安全性の考慮点は何か?
主な発見
| タイプ | モデル | アーキテクチャ | ショット | データセット | 平均 |
|---|---|---|---|---|---|
| CNNベースの | CNN [24] | 5 × CNN+1 × FC | 0 | 92.52, 92.31, 92.55 | 92.46 |
| ResNet-18 [25] | 17 × CNN+1 × FC | 0 | 91.05, 94.23, 93.62 | 92.97 | |
| VLM | BiomedCLIP [7] | ViT-B/16 | 0 | 79.14, 76.92, 58.51 | 71.52 |
| OpenCLIP [26] | ViT-G/14 | 0 | 57.96, 69.23, 63.83 | 63.67 | |
| LLaVA [5] | ViT-L/14 & LLaMA-2-7B [20] | 0 | 54.46, 66.72, 65.18 | 62.12 | |
| ChatGPT-4 [6] | GPT-4 | 0 | 51.61, 84.85, 61.82 | 66.09 | |
| OpenFlamingo [27] | ViT-L/14 & INCITE-3B | 0 | 49.68, 55.77, 62.77 | 56.07 |
- CNNベースのモデルはデータセット全体で最良の性能を依然として達成しており、監視付き訓練の恩恵を反映している。
- BiomedCLIPは三つのデータセット(BTD、ALL-IDB2、CX-Ray)全体の平均性能でしばしば最も強力なVLMとなる。
- OpenFlamingo、LLaVA、ChatGPT-4は顕著なゼロショット性能を示し、いくつかのデータセットでファewショット prompting が利得をもたらす。
- ゼロショットCLIPベースモデル(BiomedCLIP、OpenCLIP)はデータセット間で大きなばらつきを示し、データセット特異の prompts 設計の重要性を浮き彫りにする。
- プロンプト設計とデモンストレーション選択(ファewショット prompts)は医用画像タスクでのVLM精度を改善できる。
- 全体として、VLMは事前訓練済みで微調整を要しないツールとして、前診断のチャット補助としての価値を提供するが、ベンチマークタスクではまだ専用CNNを上回っていない。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。