[論文レビュー] On Leveraging Large Language Models for Enhancing Entity Resolution: A Cost-efficient Approach
論文は、エンティティ解決のためのLLMベースのコスト意識フレームワークを提案し、限られた予算内で不確実性(エントロピー)を減らす最適な MQsSP を選択し、LLMの信頼度を使って分割確率を調整する。
Entity resolution, the task of identifying and merging records that refer to the same real-world entity, is crucial in sectors like e-commerce, healthcare, and law enforcement. Large Language Models (LLMs) introduce an innovative approach to this task, capitalizing on their advanced linguistic capabilities and a ``pay-as-you-go'' model that provides significant advantages to those without extensive data science expertise. However, current LLMs are costly due to per-API request billing. Existing methods often either lack quality or become prohibitively expensive at scale. To address these problems, we propose an uncertainty reduction framework using LLMs to improve entity resolution results. We first initialize possible partitions of the entity cluster, refer to the same entity, and define the uncertainty of the result. Then, we reduce the uncertainty by selecting a few valuable matching questions for LLM verification. Upon receiving the answers, we update the probability distribution of the possible partitions. To further reduce costs, we design an efficient algorithm to judiciously select the most valuable matching pairs to query. Additionally, we create error-tolerant techniques to handle LLM mistakes and a dynamic adjustment method to reach truly correct partitions. Experimental results show that our method is efficient and effective, offering promising applications in real-world tasks.
研究の動機と目的
- データが豊富な領域におけるエンティティ解決を改善するための Large Language Models (LLMs) の活用を動機づける。
- 精度と LLM 使用コストのバランスを取るコスト認識ワークフローを導入する。
- 予算制約の下で不確実性を最小化する Matching Questions Selection Problem (MQsSP) を定義し解く。
- LLM の応答が分割確率をどのように調整し、結果集合のエントロピーをどのように低減させるかをモデル化する。
提案手法
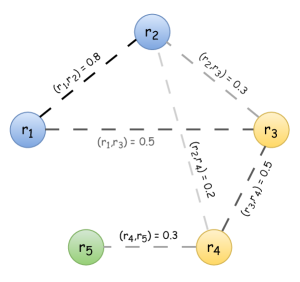
- レコードをグラフのノードとして表現し、関連確率を伴うレコードのクラスタリング分割の可能性を定義する。
- パーティションの結果集合(RS)における不確実性を定量化するためにシャノンエントロピーを用いる。
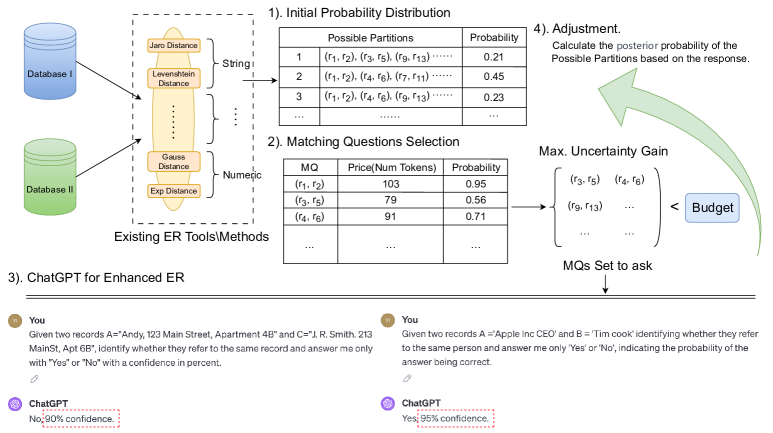
- Matching Questions (MQ) を定義し、LLM の価格設定を捉えるコスト関数 F(MQ) を定義して、予算制約付き MQ 選択を可能にする。
- MQsSP をナップサック風の予算の下での結合エントロピー削減を最大化する問題として定式化し、(1-1/e)保証を伴う貪欲なサブモジュラー最適化アプローチを提案する。
- MQを反復的に選択し、LLM にクエリを投げ、分割確率を更新する、LLM支援の ER ワークフロー(Algorithm 2)を開発する。
- RS を更新する際の不完全な LLM 応答を考慮する、Cap と Conf を含む確率的調整モデルを提供する。
実験結果
リサーチクエスチョン
- RQ1費用を管理しつつ、LLMs をサービスとして活用してエンティティ解決を改善するにはどうすればよいか。
- RQ2予算の下で不確実性を最大限に削減するマッチングクエスチョンの効果的な選択方法は何か。
- RQ3LLM の応答を統合して、可能な分割の確率分布をどのように精練できるか。
- RQ4MQsSP の計算難易度はどの程度で、実務的には効率的に近似できるか。
主な発見
- MQsSP は NP-hard であり、k=1 の特殊ケースでも(0/1 Knapsack に還元可能)である。
- サブモジュラ性を用いた貪欲近似は、(1-1/e) の性能保証を伴う予算制約付き MQ 選択戦略を効果的に提供する。
- エントロピーに基づく枠組みは、LLM 応答を取り入れる際の不確実性削減を定量化することを可能にする。
- このフレームワークは、LLM の回答と信頼度に基づいて分割分布を調整することにより、エンティティ解決における不確実性を費用効果的に低減することを実証する。
- データセット(ACM、Amazon-eBay、Electronics)での実験は、予算内で不確実性を低減しつつ、初期分割には既存の ER ツールを使用できることを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。