[論文レビュー] On the Connection Between MPNN and Graph Transformer
この論文は、仮想ノードを用いたMPNNがGraph Transformersの自己注意を任意に近似できることを、深さと幅のさまざまなトレードオフとともに示し、ベンチマーク全体で実証的な証拠を提供している。
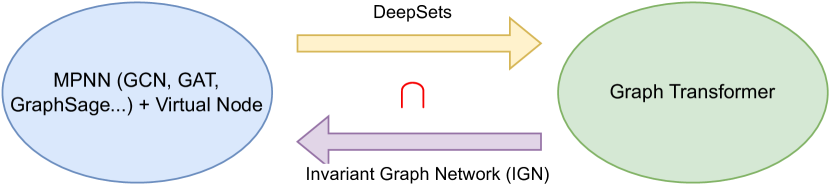
Graph Transformer (GT) recently has emerged as a new paradigm of graph learning algorithms, outperforming the previously popular Message Passing Neural Network (MPNN) on multiple benchmarks. Previous work (Kim et al., 2022) shows that with proper position embedding, GT can approximate MPNN arbitrarily well, implying that GT is at least as powerful as MPNN. In this paper, we study the inverse connection and show that MPNN with virtual node (VN), a commonly used heuristic with little theoretical understanding, is powerful enough to arbitrarily approximate the self-attention layer of GT. In particular, we first show that if we consider one type of linear transformer, the so-called Performer/Linear Transformer (Choromanski et al., 2020; Katharopoulos et al., 2020), then MPNN + VN with only O(1) depth and O(1) width can approximate a self-attention layer in Performer/Linear Transformer. Next, via a connection between MPNN + VN and DeepSets, we prove the MPNN + VN with O(n^d) width and O(1) depth can approximate the self-attention layer arbitrarily well, where d is the input feature dimension. Lastly, under some assumptions, we provide an explicit construction of MPNN + VN with O(1) width and O(n) depth approximating the self-attention layer in GT arbitrarily well. On the empirical side, we demonstrate that 1) MPNN + VN is a surprisingly strong baseline, outperforming GT on the recently proposed Long Range Graph Benchmark (LRGB) dataset, 2) our MPNN + VN improves over early implementation on a wide range of OGB datasets and 3) MPNN + VN outperforms Linear Transformer and MPNN on the climate modeling task.
研究の動機と目的
- Investigate whether MPNN (with a virtual node) can approximate Graph Transformer self-attention.
- Characterize depth-width trade-offs for MPNN + VN approximating self-attention under different transformer variants.
- Establish connections between MPNN+VN, DeepSets, and permutation-equivariant universality.
- Provide empirical evidence on Long Range Graph Benchmark (LRGB) and other datasets to compare MPNN+VN with GT and other baselines.
提案手法
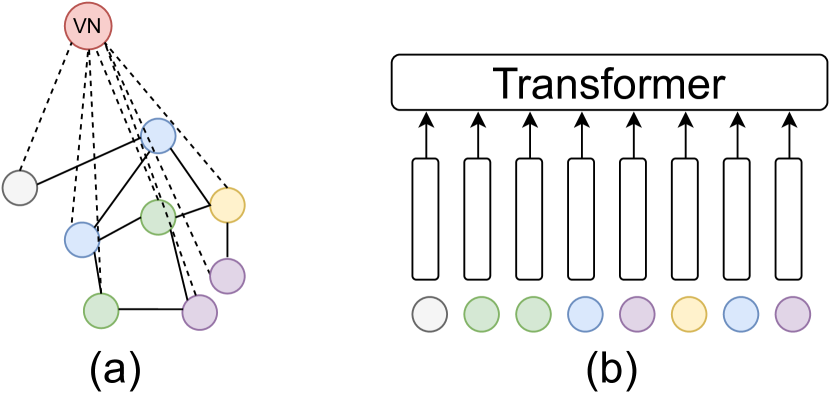
- Define heterogeneous and simplified heterogeneous MPNN + VN layers to model global interactions.
- Prove that O(1) depth and O(1) width MPNN + VN can approximate Performer/Linear Transformer self-attention.
- Leverage the connection to DeepSets to show O(1) depth and O(n^d) width universal approximation.
- Under strong feature assumptions, construct O(1) width and O(n) depth MPNN + VN that approximates self-attention.
- Provide empirical results showing MPNN + VN performs competitively or better on LRGB and OGB datasets, and on climate modeling tasks.
実験結果
リサーチクエスチョン
- RQ1Can MPNN + VN approximate self-attention layers used in Graph Transformers?
- RQ2What depth-width regimes suffice for MPNN + VN to replicate GT attention under different transformer formulations?
- RQ3How does the MPNN + VN approach relate to DeepSets and permutation-equivariant universality?
- RQ4Do empirical results support MPNN + VN as a strong baseline across standard graph benchmarks?
主な発見
| Depth | Width | Self-Attention | Notes |
|---|---|---|---|
| O(1) | O(1) | Approximate | Approximate self attention in Performer (Choromanski et al., 2020 ) |
| O(1) | O(n^d) | Full | Leverage the universality of equivariant DeepSets |
| O(n) | O(1) | Full | Explicit construction, strong assumption on 𝑋 |
| O(n) | O(1) | Full | Explicit construction, more relaxed (but still strong) assumption on 𝑋 |
- MPNN + VN with O(1) depth and O(1) width can approximate self-attention in Performer/Linear Transformer.
- MPNN + VN with O(1) depth and O(n^d) width is permutation-equivariant universal, hence can approximate self-attention and full transformers via DeepSets.
- Under certain feature assumptions, there exists an O(n) depth and O(1) width construction approximating self-attention arbirtrarily well; assumptions are strong.
- Empirically, MPNN + VN outperforms some Graph Transformers on LRBG and improves over early MPNN+VN implementations on OGB datasets; it also outperforms Linear Transformer and plain MPNN on climate modeling tasks.
- Theoretical connections show that MPNN + VN can simulate DeepSets exactly in two layers, underpinning universal approximation results.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。