[論文レビュー] On the Detectability of ChatGPT Content: Benchmarking, Methodology, and Evaluation through the Lens of Academic Writing
本論文はGPABenchmarkを紹介します。人間およびGPT生成の学術要約の600,000サンプルデータセットであり、モデルに依存しない検出器CheckGPTを提案します。分野特有のタスクで約98-99%の精度を達成し、新しいドメインへの強い転移性を示します。
With ChatGPT under the spotlight, utilizing large language models (LLMs) to assist academic writing has drawn a significant amount of debate in the community. In this paper, we aim to present a comprehensive study of the detectability of ChatGPT-generated content within the academic literature, particularly focusing on the abstracts of scientific papers, to offer holistic support for the future development of LLM applications and policies in academia. Specifically, we first present GPABench2, a benchmarking dataset of over 2.8 million comparative samples of human-written, GPT-written, GPT-completed, and GPT-polished abstracts of scientific writing in computer science, physics, and humanities and social sciences. Second, we explore the methodology for detecting ChatGPT content. We start by examining the unsatisfactory performance of existing ChatGPT detecting tools and the challenges faced by human evaluators (including more than 240 researchers or students). We then test the hand-crafted linguistic features models as a baseline and develop a deep neural framework named CheckGPT to better capture the subtle and deep semantic and linguistic patterns in ChatGPT written literature. Last, we conduct comprehensive experiments to validate the proposed CheckGPT framework in each benchmarking task over different disciplines. To evaluate the detectability of ChatGPT content, we conduct extensive experiments on the transferability, prompt engineering, and robustness of CheckGPT.
研究の動機と目的
- LLM生成の学術的執筆を検出する挑戦を動機づけ、定量化する。
- 検出器のベンチマーキングのための包括的で学際的なデータセット(GPABenchmark)を提供する。
- モデルに依存しない検出器(CheckGPT)を開発し、正確で転移性があり、解釈可能である。
提案手法
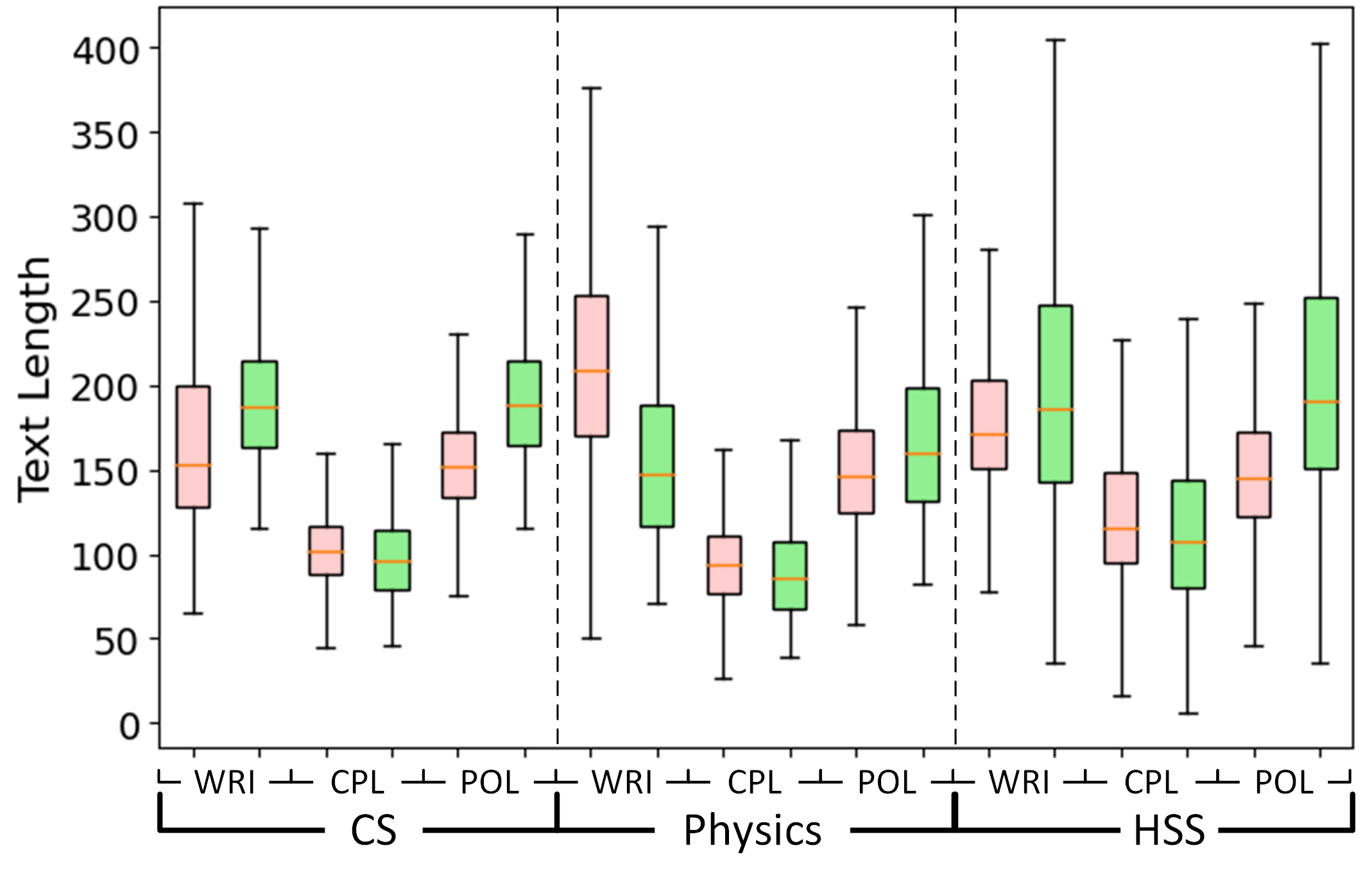
- CS、物理学、HSSにわたる人間作成、GPT作成、GPT完了、GPT磨きの要約を600,000サンプルで含むGPABenchmarkを構築する。
- GPABenchmark上でGPT-WRI、GPT-CPL、GPT-POLの3つのタスクに対して、GPTZero、ZeroGPT、OpenAIの分類器などの既存のオープンソースおよび商用検出器を評価する。
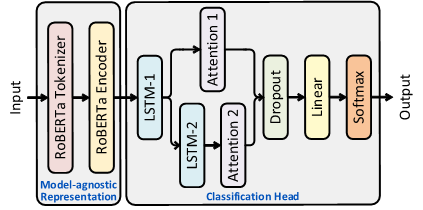
- 一般表現モジュールと注意付きBiLSTM分類器を備えた言語モデルベースの検出器としてCheckGPTを設計する。
- CheckGPTがモデルに依存しないことと転移可能性を示し、ドメイン特化の微調整を最小限に抑えることができる。
- 150名以上の参加者を対象とする人間のユーザースタディを実施し、GPT生成要約の検出可能性を評価する。
実験結果
リサーチクエスチョン
- RQ1学際的な分野を横断して、人間はGPT生成の要約をどれくらい正確に識別できるか。
- RQ2GPT-polishedテキストを含むGPABenchmarkにおいて、最先端の検出器はどの程度の性能を示すか。
- RQ3白箱アクセスなしで、言語モデルベースの検出器(CheckGPT)は高精度と転移性を達成できるか。
- RQ4CheckGPTはLLM出力についての解釈可能性(生成プロセスに関する洞察)を提供できるか。
主な発見
- GPABenchmarkはCS、物理、HSSの人間作成、GPT作成、GPT完了、GPT磨きの要約を含む60万サンプルを含む。
- 人間の評価者はGPT生成要約を識別するのに苦戦し、専門家の間でも精度はランダム程度から控えめな値になる。
- オープンソースおよび商用検出器はGPABenchmark上で満足のいく性能を示さず、特にGPT-polishedテキストに対しては不十分である。
- CheckGPTはタスク固有の検出器で平均精度98%–99%を達成し、チューニングなしで新しいドメインへ約90%の転移精度を示し、約2000件のドメイン微調整サンプルで約98%へ上昇する。
- CheckGPTはモデルに依存せず、軽量で、転移可能で、LLM生成テキストの解釈可能性の洞察を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。