[論文レビュー] On the Global Convergence of Gradient Descent for Over-parameterized Models using Optimal Transport
本論文は離散化された測度(粒子)上の勾配流を研究し、多数の粒子極限において、対応するワッサースタイン勾配流が特定の均質性と初期化の分離条件の下で全体的な極小点へ収束することを証明する。この結果は過パラメータ化された非凸モデルに対する定性的整合性原理を提供する。
Many tasks in machine learning and signal processing can be solved by\nminimizing a convex function of a measure. This includes sparse spikes\ndeconvolution or training a neural network with a single hidden layer. For\nthese problems, we study a simple minimization method: the unknown measure is\ndiscretized into a mixture of particles and a continuous-time gradient descent\nis performed on their weights and positions. This is an idealization of the\nusual way to train neural networks with a large hidden layer. We show that,\nwhen initialized correctly and in the many-particle limit, this gradient flow,\nalthough non-convex, converges to global minimizers. The proof involves\nWasserstein gradient flows, a by-product of optimal transport theory. Numerical\nexperiments show that this asymptotic behavior is already at play for a\nreasonable number of particles, even in high dimension.\n
研究の動機と目的
- 過パラメータ化設定において、非凸な粒子勾配流が全球最小に収束する条件と理由を説明する。
- 有限粒子の勾配流を無限次元のワッサースタイン勾配流フレームワークに結びつける。
- 均質性と構造化された初期化が、ニューラルネットワークやスパースデコンボリューションに関連するリフト化された定式化において全球最適性につながることを示す。
- 結果を単一隠れ層ニューラルネットワークとスパーススパイクデコンボリューションに適用することで指針を提供する。
提案手法
- 未知の測度を、リフト表現 Phi と領域 Omega によって滑らかな損失 R とポテンシャル V を分離する凸関数 F(mu) にリフトする。
- mu を m 粒子の混合として離散化し、F_m の粒子勾配流を研究する。速度は射影された負の勾配(式(5))で与えられる。
- 粒子ダイナミクスから、確率測度上の F のワッサースタイン勾配流へ移行し、速度がワッサースタイン部分微分に属する連続の式(定義2.4)に従う。
- 一般的な多粒子極限を確立する:mu_{m,t} が極限ダイナミクスを解くワッサースタイン勾配流 mu_t に収束する(定理2.6)。
- 2-均質性(ReLU を含むリフト問題を含む)と部分的な1-均質性(有界な Phi、例:スパースデコンボリューションとシグモイドネットワークなど)という2つの均質設定における全球収束を分析する(定理3.3と3.5)。
- 結果をスパースデコンボリューションと単一隠れ層を持つニューラルネットワークに適用し、初期化と境界条件/サード型正則性仮定を詳述する(第4章)。
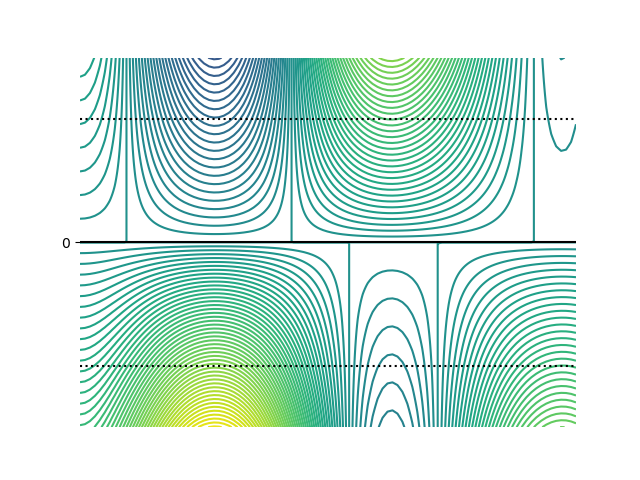
実験結果
リサーチクエスチョン
- RQ1粒子表現上の勾配流がリフト化された汎関数 F の全球最小値へ収束するのは、どのような構造条件(均質性)と初期化パターンのときか。
- RQ2過パラメータ化モデルの有限粒子勾配流動力学は平均場リミットでのワッサースタイン勾配流として記述できるか。
- RQ3リフト化された均質表現が、スパースデコンボリューションやシグモイド型または ReLU 活性化を持つ単一隠れ層ニューラルネットワークのような実用アーキテクチャにどのように適用されるか。
- RQ4初期化分離性とサード型正則性が全球最小値への収束確保に果たす役割は何か。
- RQ5経験的な(有限 m)粒子系は、ワッサースタイン枠組みが予測する漸近的な全球収束を示すか。
主な発見
- 多粒子極限では、適切な初期条件の下で、離散粒子勾配流が F の唯一のワッサースタイン勾配流へ収束する(定理2.6)。
- ワッサースタイン勾配流が2-均質性または部分的な1-均質性の下で収束する場合、極限は F の全球最小化点である(定理3.3と3.5)。
- ニューラルネットワークやスパースデコンボリューションに対応するリフト問題では、全球収束を保証するために、パラメータ空間の特定の球を分離する初期化パターンを規定している(定理3.3, 3.5 の仮定)。
- 結果は、単一隠れ層ネットワークにおける ReLU およびシグモイド活性化を対象とし、境界条件と Sard 型正則性の明示的な議論を通じて収束を保証する(第4章)。
- 数値実験は、適切な粒子数で漸近的な領域が観測可能であり、粒子勾配流が固定の大規模粒子グリッドでの最適化よりも優れる可能性を示す(第4章4節3項)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。