[論文レビュー] On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
本論文は、計画タスクにおける OpenAI の o1 モデルを実証的に評価し、複数のベンチマークにわたる実現可能性、最適性、一般化性を分析し、GPT-4 と比較している。
Recent advancements in Large Language Models (LLMs) have showcased their ability to perform complex reasoning tasks, but their effectiveness in planning remains underexplored. In this study, we evaluate the planning capabilities of OpenAI's o1 models across a variety of benchmark tasks, focusing on three key aspects: feasibility, optimality, and generalizability. Through empirical evaluations on constraint-heavy tasks (e.g., $ extit{Barman}$, $ extit{Tyreworld}$) and spatially complex environments (e.g., $ extit{Termes}$, $ extit{Floortile}$), we highlight o1-preview's strengths in self-evaluation and constraint-following, while also identifying bottlenecks in decision-making and memory management, particularly in tasks requiring robust spatial reasoning. Our results reveal that o1-preview outperforms GPT-4 in adhering to task constraints and managing state transitions in structured environments. However, the model often generates suboptimal solutions with redundant actions and struggles to generalize effectively in spatially complex tasks. This pilot study provides foundational insights into the planning limitations of LLMs, offering key directions for future research on improving memory management, decision-making, and generalization in LLM-based planning. Code available at https://github.com/VITA-Group/o1-planning.
研究の動機と目的
- o1 モデルがドメイン制約下で実行可能な計画をどれだけうまく生成するかを評価する。
- o1 モデルが生成する計画の最適性を評価し、行動の効率性と冗長性に焦点を当てる。
- 未見のタスクや記号的に表現されたタスクへの o1 モデルの一般化性を検討する。
- 計画における共通の誤りと、記憶・意思決定のボトルネックを特定する。
- 自己評価と記憶技術を通じて、LLM ベースの計画を改善するための方向性を提示する。
提案手法
- GPT-4、o1-mini、および o1-preview を用いて、Barman、Blocksworld、Floortile、Grippers、Tyreworld、Termes のセットの計画タスクをベンチマークする。
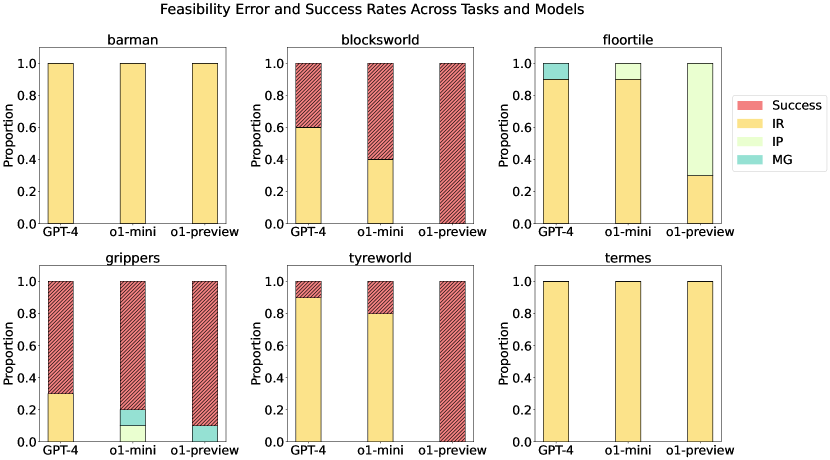
- エラーを実現可能性(IR、IP、MG)と最適性(LO)に分類し、成功率/実行可能性と最適性の割合を測定する。
- 空間的および行動の複雑さに沿った性能を分析し、ボトルネックを特定する。
- 計画中の行動を評価・修正するために、o1-preview の自己評価メカニズムを活用する。
- 抽象的・記号的なタスク表現(randomized Tyreworld)でのテストにより、一般化を比較する。
- 記憶管理、制約順守、および一般化に関する限界を明らかにし、今後の方向性を提案する。
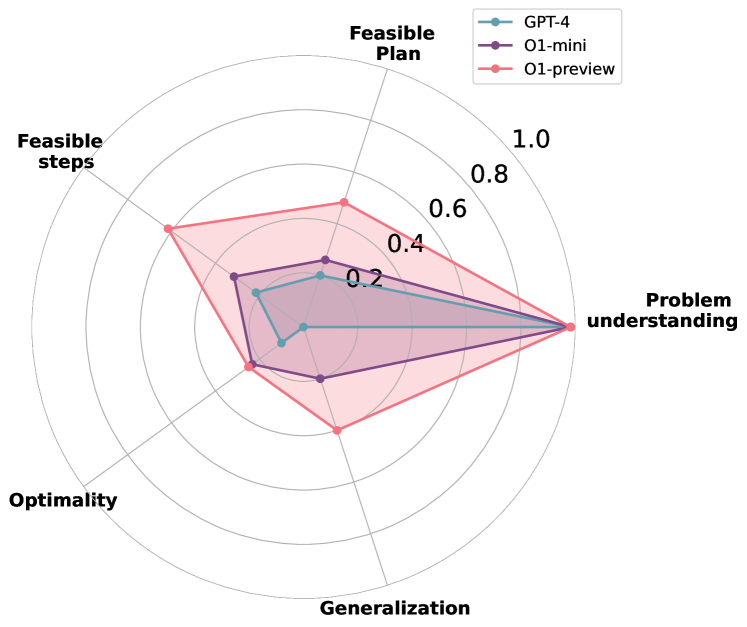
実験結果
リサーチクエスチョン
- RQ1多様な計画ドメインにおいて、o1 モデルが生成する計画はどれくらい実現可能か?
- RQ2o1 モデルは GPT-4 よりも最適(効率的)な計画を生成するのか、どこで依然として不足しているのか?
- RQ3o1 モデルは抽象的または記号的に表現されたタスクへ計画戦略を一般化できるか?
- RQ4o1 モデルで観察される主な計画エラーのタイプ(IR、IP、MG、LO)は何で、ドメインごとにどう変わるか?
- RQ5計画性能に影響を与える記憶、状態管理、空間推論の主なボトルネックは何か?
主な発見
- o1-preview は、GPT-4 および o1-mini よりも複数のドメインで一般に高い成功率を達成し、いくつかのケースで Blocksworld および Tyreworld のテストセットで完全な成功を示す。
- o1-preview は制約順守と自己評価を改善するが、Termes のような複雑な空間では依然として非最適な計画(LO)や誤解(MG)が見られる。
- GPT-4 は制約遵守と計画効率でしばしば能力を下回り、特に空間的により複雑なタスクではそうなる。
- Floortile は全モデルで広範な失敗を示し、IRエラーがGPT-4と o1-mini を支配する一方、o1-preview は IR 発生を減らすが他のエラーに直面する。
- Grippers タスクでは o1-preview が最大で 90% の成功、70% の最適性を達成し、多くの事例で GPT-4 および o1-mini を上回る。
- 一般化テストは、o1-preview が構造化された一般化(Grippers)を GPT-4 よりも適切に処理できることを示すが、抽象的な記号表現(randomized Tyreworld)では性能が低下する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。