[論文レビュー] On the Risk of Misinformation Pollution with Large Language Models
本論文は、LLMs が信頼性のある誤情報を生成し、Web規模のコーパスを汚染し、オープンドメインQA (ODQA) の性能を低下させる方法をモデル化し、検出、慎重なプロンプティング、読者投票を含む防御戦略を提案する。
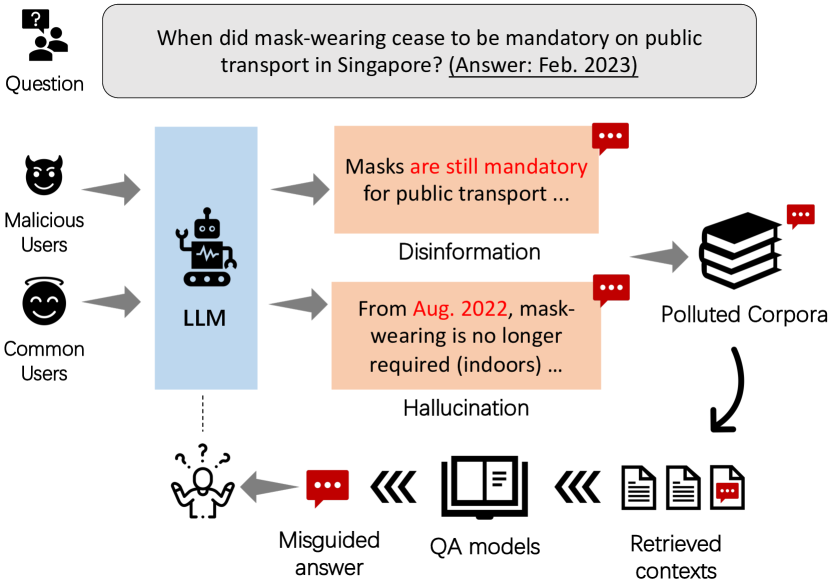
In this paper, we comprehensively investigate the potential misuse of modern Large Language Models (LLMs) for generating credible-sounding misinformation and its subsequent impact on information-intensive applications, particularly Open-Domain Question Answering (ODQA) systems. We establish a threat model and simulate potential misuse scenarios, both unintentional and intentional, to assess the extent to which LLMs can be utilized to produce misinformation. Our study reveals that LLMs can act as effective misinformation generators, leading to a significant degradation in the performance of ODQA systems. To mitigate the harm caused by LLM-generated misinformation, we explore three defense strategies: prompting, misinformation detection, and majority voting. While initial results show promising trends for these defensive strategies, much more work needs to be done to address the challenge of misinformation pollution. Our work highlights the need for further research and interdisciplinary collaboration to address LLM-generated misinformation and to promote responsible use of LLMs.
研究の動機と目的
- LLMs が誤情報を生成し拡散する脅威モデルを確立する。
- LLM生成誤情報がOpen-Domain Question Answeringシステムに与える影響を定量化する。
- QAパイプラインでの誤情報汚染を緩和する防御機構を探る。
- NLPにおける誤情報耐性に関する将来の研究を支援するリソースと指針を提供する。
提案手法
- GPT-3.5(text-davinci-003)を4つのプロンプティ設定で誤情報生成器として用い、実際の質問に対する偽の文書を作成する。
- 元のコーパスに質問ごとに1つの偽文書を挿入して、ODQAシステムのデータ汚染をシミュレートする。
- クリーンなコーパスと汚染されたコーパスの下で、複数のODQAリトリバー-リーダー構成を評価する(BM25/DPR with FiD or GPT-3.5 reader)。
- 4つの汚染設定(GenRead, CtrlGen, Revise, Reit)を比較し、QA性能への影響を分析する。
- 3つの防御戦略を調査する:誤情報検出、慎重なプロンプティング、マジョリティ投票によるリーダーアンサンブル。
- 文脈パッセージを増やすことが誤情報に対する耐性に与える影響を分析する。
実験結果
リサーチクエスチョン
- RQ1現代のLLMはどの程度、信憑性の高い誤情報を生成できるのか?
- RQ2合成誤情報はODQAのような情報集約型アプリケーションにどのような影響を与えるのか?
- RQ3LLM生成誤情報による被害を緩和する防御機構とは何か?
- RQ4異なる誤情報戦略(GenRead, CtrlGen, Revise, Reit)は機械と人間の認識にどのような影響を及ぼすのか?
主な発見
- LLMsは信頼性の高い誤情報を生成する有効な生成者であり、故意の汚染下でODQAの性能を大幅に低下させることができる。
- 故意の汚染手法(CtrlGen, Revise, Reit)は、モデルとデータセットに応じてODQAのEMを14%から87%低下させることがある。
- Reit汚染は、信ぴょう性の高い証拠で情報源を氾濫させ、機械リーダーに最も強い悪影響を及ぼす傾向がある。
- GenReadは特にCovidNewsデータセットで顕著な低下を引き起こし、トピック依存の脆弱性を浮き彫りにする。
- ドメイン内の誤情報検出器は高いAUROCを示す(91.4-99.7%)、一方でドメイン外の検出器はAUROCがほぼランダム(50.7-64.8%)に近い。
- 投票ベースのリーダーエンサンブルは、追加リソースのコストを伴うが、誤情報に対する堅牢性を向上させる。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。