[論文レビュー] On the Variance of Neural Network Training with respect to Test Sets and Distributions
この論文は、独立した学習実行間のテストセット分散は、有限サンプルノイズと初期条件の敏感さに大部分起因し、収束時には分布-wise分散は小さくなると主張している。アンサンブルのキャリブレーションは避けられないが限界があるテストセット分散をもたらす。
Typical neural network trainings have substantial variance in test-set performance between repeated runs, impeding hyperparameter comparison and training reproducibility. In this work we present the following results towards understanding this variation. (1) Despite having significant variance on their test-sets, we demonstrate that standard CIFAR-10 and ImageNet trainings have little variance in performance on the underlying test-distributions from which their test-sets are sampled. (2) We show that these trainings make approximately independent errors on their test-sets. That is, the event that a trained network makes an error on one particular example does not affect its chances of making errors on other examples, relative to their average rates over repeated runs of training with the same hyperparameters. (3) We prove that the variance of neural network trainings on their test-sets is a downstream consequence of the class-calibration property discovered by Jiang et al. (2021). Our analysis yields a simple formula which accurately predicts variance for the binary classification case. (4) We conduct preliminary studies of data augmentation, learning rate, finetuning instability and distribution-shift through the lens of variance between runs.
研究の動機と目的
- 独立した学習実行間のテストセット精度の分散の原因を調査する。
- テスト分布で平均以上を一般化する最良の実行が存在するかを評価する。
- 分散に影響を与えるハイパーパラメータやトレーニングの側面を特定する。
- テストセット分散と分布-wise分散およびアンサンブルキャリブレーションを結ぶ統計的枠組みを構築する。
提案手法
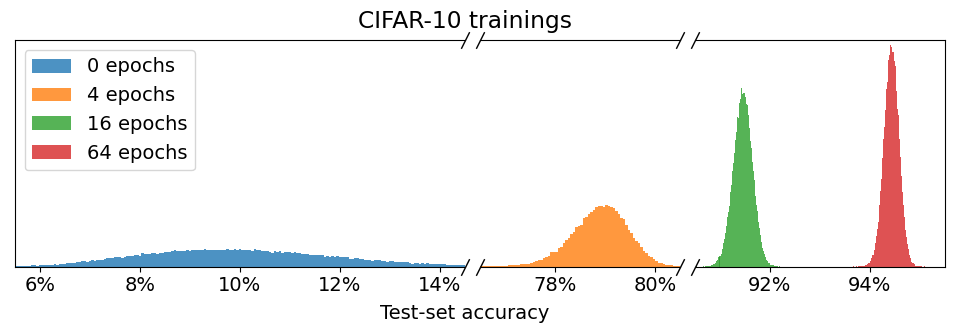
- CIFAR-10と ImageNet で約35万ネットワークを経験的に訓練し、分散を特徴づける。
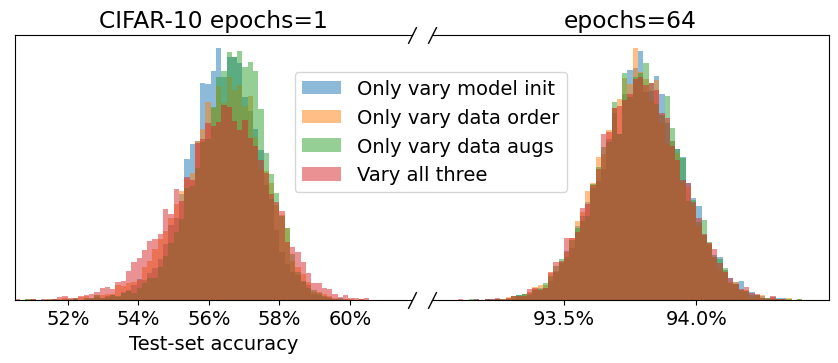
- 乱数の出所を制御して(モデル初期化、データ順序、拡張など)それらの影響を分離する。
- 仮説1(一例ごとの独立性)を提案してテスト精度の分布をモデル化する。
- 分布-wise分散の無偏推定量を導出する(式(Equation 2))。
- 定理3–5を通じてテストセット分散をアンサンブルキャリブレーションと理論的に結びつける。
実験結果
リサーチクエスチョン
- RQ1独立した学習実行間の分散の原因は何か、どの乱数源が最も責任があるか。
- RQ2テストセットで最良の実行を選ぶことは、テスト分布への平均以上の一般化を意味するか。
- RQ3テストセット分散と分布-wise分散に影響を与えるハイパーパラメータは何か。
- RQ4有限のテストサンプルから分布-wise分散を推定し、それをアンサンブルキャリブレーションと関連づけられるか。
- RQ5分布シフト、データ拡張、学習率の変化に対して分散はどう振る舞うか。
主な発見
- 実行間の分散は、単一の乱数源ではなく初期条件の極端な敏感さが大半を占める。
- 訓練が収束するにつれて独立したテスト分割間の相関が解消され、分布-wise精度の本質的な分散は限定的であることを示唆する。
- 無偏推定量は、CIFAR-10で約0.033%、ImageNetで約0.034%程度まで分布-wise分散が低くなり得ることを示す。
- アンサンブルキャリブレーションは、分類タスクにおいて実行間でのテストセット分散を正の値として示唆する。
- BERT-Large のファインチューニングは BERT-Base より分布-wise分散がはるかに大きく、モデルサイズが不安定性に影響することを示す。
- 分布シフトがあるテストセットは、ドメイン内のセットより実行間の分散が大きく、データ拡張は分散を減少させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。