[論文レビュー] ONCE: Boosting Content-based Recommendation with Both Open- and Closed-source Large Language Models
ONCEは、コンテンツエンコーダとしてオープンソースLLMを、データ補助としてクローズドソースLLMを活用することで、コンテンツベース推薦システムを強化し、顕著な利得と二つのタイプ間の補完的相乗効果を示す。
Personalized content-based recommender systems have become indispensable tools for users to navigate through the vast amount of content available on platforms like daily news websites and book recommendation services. However, existing recommenders face significant challenges in understanding the content of items. Large language models (LLMs), which possess deep semantic comprehension and extensive knowledge from pretraining, have proven to be effective in various natural language processing tasks. In this study, we explore the potential of leveraging both open- and closed-source LLMs to enhance content-based recommendation. With open-source LLMs, we utilize their deep layers as content encoders, enriching the representation of content at the embedding level. For closed-source LLMs, we employ prompting techniques to enrich the training data at the token level. Through comprehensive experiments, we demonstrate the high effectiveness of both types of LLMs and show the synergistic relationship between them. Notably, we observed a significant relative improvement of up to 19.32% compared to existing state-of-the-art recommendation models. These findings highlight the immense potential of both open- and closed-source of LLMs in enhancing content-based recommendation systems. We will make our code and LLM-generated data available for other researchers to reproduce our results.
研究の動機と目的
- コンテンツ表現を豊かにすることでコンテンツベースの推薦システムの改善を動機づける。
- オープンソースLLMをコンテンツエンコーダとしてファインチューニングできるかを調査する(DIRE)。
- クローズドソースLLMをプロンプトでデータを増強して下流モデルを改善できるかを調査する(GENRE)。
- オープンとクローズドの両方のLLMを統一的なフレームワークで組み合わせたときの相乗効果を探る。
- 標準的なベンチマーク(MIND、Goodreads)での性能向上の実証的証拠を提供する。
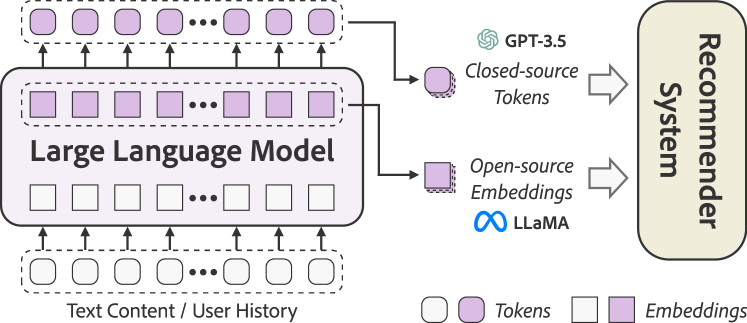
提案手法
- オープンソースLLMをコンテンツエンコーダとして置換または補強し、アテンション層で表現を統合する(DIRE)。
- 自然言語テンプレートを用いて複数フィールドのコンテンツを単一シーケンスに変換し、LLM埋め込みへマッピングする。
- パラメータ効率的手法(LoRA)で上位k層のみをファインチューニングし、キャッシュを用いて計算を削減する。
- クローズドソースLLM(GPT-3.5)をプロンプトしてリッチなデータ記述とユーザープロファイルを生成させる(GENRE)。
- LLM生成の要約とユーザープロファイリングをデータ増強と特徴量強化を通じて下流の推奨に組み込む(ALL)。
- ユーザープロファイルとコンテンツの合成を反復的に改良するためのチェーンベース生成を検討する(Chain-based Generation)。
実験結果
リサーチクエスチョン
- RQ1オープンソースLLMをコンテンツエンコーダとして用いると、コンテンツベースの推奨性能にどのような影響があるか(DIRE)。
- RQ2クローズドソースLLMを用いたデータ生成が下流モデルを改善する方法はどうか(GENRE)。
- RQ3オープンソースとクローズドソースのLLMは推奨品質と学習効率に相補的な利点をもたらすか。
- RQ4ファインチューニング戦略(どの層、LoRA)は推奨のオープンソースLLMにどのような影響を与えるか。
- RQ5両方のLLMタイプを組み合わせた場合の総合的な利得は標準データセットでどの程度か。
主な発見
| Dataset | Model | AUC | MRR | N@5 | N@10 |
|---|---|---|---|---|---|
| MIND | Original | 61.75 | 30.60 | 31.35 | 37.85 |
| MIND | DIRE (BERT 12L) | 65.32 | 33.16 | 34.29 | 40.35 |
| MIND | LLaMA 7B (Ours) | 68.34 | 35.80 | 37.60 | 43.48 |
| MIND | LLaMA 13B (Ours) | 68.23 | 35.99 | 37.93 | 43.77 |
| MIND | GENRE (CS) | 63.73 | 31.83 | 32.94 | 39.24 |
| MIND | GENRE (UP) | 62.19 | 30.90 | 31.78 | 38.26 |
| MIND | GENRE (CG) | 62.93 | 30.83 | 32.10 | 38.34 |
| MIND | GENRE (UP → CG) | 63.61 | 31.58 | 32.63 | 39.07 |
| MIND | ALL (Ours) | 63.88 | 32.17 | 33.14 | 39.37 |
| MIND | ONCE (Ours) | 68.62 | 36.50 | 38.31 | 44.05 |
| Goodreads | Original | 66.47 | 75.75 | 58.49 | 82.20 |
| Goodreads | DIRE (BERT 12L) | 70.68 | 78.17 | 62.26 | 83.99 |
| Goodreads | LLaMA 7B (Ours) | 77.01 | 82.74 | 71.09 | 89.39 |
| Goodreads | LLaMA 13B (Ours) | 77.43 | 83.05 | 71.56 | 87.61 |
| Goodreads | GENRE (CS) | 67.68 | 76.41 | 59.64 | 82.69 |
| Goodreads | GENRE (UP) | 68.45 | 76.91 | 60.70 | 83.08 |
| Goodreads | GENRE (CG) | 66.94 | 76.10 | 59.26 | 82.47 |
| Goodreads | GENRE (UP → CG) | 67.98 | 76.78 | 60.56 | 82.96 |
| Goodreads | ALL (Ours) | 68.95 | 77.25 | 61.19 | 83.32 |
| Goodreads | ONCE (Ours) | 77.63 | 83.13 | 71.65 | 87.66 |
- オープンソースLLM(LLaMA)はコンテンツエンコーダとして強力な改善を提供し、ベースラインに対して顕著なAUCとMRRの利得を示す。
- クローズドソースLLM(GPT-3.5)をプロンプトで用いたデータ増強も性能を改善し、オープンソースLLMと組み合わせると substantial な利得を達成する。
- 二重LLMアプローチのONCEはデータセット全体で最良の性能を示し、元のベースラインおよび単一LLMのベースラインを一貫して上回る。
- オープンソースLLMを上位層でファインチューニングし(LoRA使用を含む)ると、一般的にはより大きな利得を得られるが、データセットとモデルサイズによって効果は異なる。
- ONCEは学習を加速させ、クローズドソースLLM情報を活用することで学習初期段階での性能を同程度に引き上げる。
- データ増強プロンプトとコンテンツエンコーダのファインチューニングの組み合わせは、オープン-とクローズド-ソースLLMの補完的関係を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。