[論文レビュー] One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
One-2-3-45++ は、単一の画像を約1分で高忠実かつテクスチャ付きの3Dメッシュへ変換します。手順は(1) 微調整済み2D拡散を用いて一貫したマルチビュー画像を生成、(2) マルチビュー条件付き3D拡散と軽量なテクスチャ精製でそれらを高解像度化。
Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.
研究の動機と目的
- 2D拡散の事前知識と限られた3Dデータを活用して、単一の画像から高 fidelity な3Dアセットを生成する。
- 下流の3D再構成を向上させるために、一貫したマルチビュー画像生成を保証する。
- マルチビュー画像を3Dへ昇格させ、マルチビュー条件付き3D拡散モデルを用いて効率的にテクスチャを refine する。
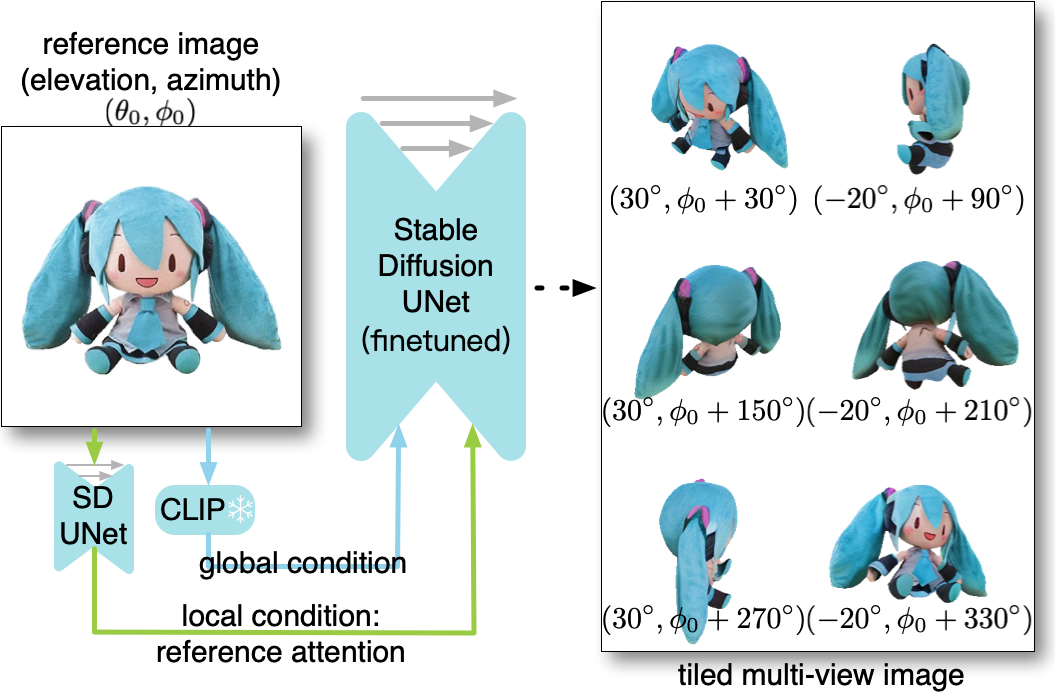
提案手法
- 6 つのビューを1つの画像にタイル状に配置し、入力画像を条件として一貫したマルチビュー合成を生成するように2D拡散モデルを微調整する。
- マルチビュー条件付き3D拡散モデルを用いて、粗から細への2段階プロセスでテクスチャ付き3Dメッシュを再構成する(occupancy/volume → 高解像度のSDF+カラー)。
- 既知のカメラ姿勢で投影されたマルチビュー局所画像特徴から3D特徴ボリュームを構築し、3D拡散を誘導する。
- CLIPベースのグローバル条件と局所的なマルチビュー条件ボリュームを3D拡散に取り入れ、occupancyとcolorの両方の出力を得る。
- 一貫したマルチビュー画像を監視信号として用い、カラー場を最適化して軽量なテクスチャ refinement を適用する(TensorField風)。
- Objaverse/Objaverse由来のレンダリングにデータ拡張とランダムポーズ撹乱を加えて訓練し、推論は64^3 occupancy体をデノイズした後に高解像度のスパースボリューム拡散と marching cubes を適用して行う。

実験結果
リサーチクエスチョン
- RQ1一貫したマルチビュー生成は単一画像からの3D再構成品質を改善できるか?
- RQ2マルチビュー条件付き3D拡散モデルは、従来のNeRFベースや拡散ベースの手法より高品質なテクスチャ付きメッシュを生み出すか?
- RQ3提案された2段階の3D拡散と軽量なテクスチャ精製は、入力画像への忠実性を保ちながらより高速か?
- RQ43D IoU、F-score、CLIP類似度の観点から、マルチビュー局所条件付けはグローバル条件付けと比べて3D拡散にどのような影響を与えるか?
主な発見
| Method | F-Sco. (%) | CLIP-Sim | User-Pref. | Time |
|---|---|---|---|---|
| Zero123 XL [10] | 91.6 | 73.1 | 58.6 | 30min |
| One-2-3-45 [34] | 90.4 | 70.8 | 52.7 | 45s |
| SyncDreamer [37] | 84.8 | 68.9 | 28.4 | 6min |
| DreamGaussian [63] | 81.0 | 68.4 | 31.5 | 2min |
| Shap-E [25] | 91.8 | 73.1 | 40.8 | 27s |
| Ours | 93.6 | 81.0 | 87.6 | 60s |
- GSOデータセットで、単一画像からの3DにおいてF-Score、CLIP similarity、ユーザー評価のベースラインを上回る(例:One-2-3-45++ は 93.6 F-Score、81.0 CLIP-Sim、87.6 User-Pref、60s)。
- 実行時間で最適化ベースの手法を上回り(≤1 minute)、入力ビューへの忠実度を維持または向上。
- アブレーションにより、一貫したマルチビュー生成とマルチビュー条件付き3D拡散が重要であることが示され、これらを除くと3D IoUとCLIP類似度が低下。
- マルチビュー監視によるテクスチャ精製は、テクスチャ品質とCLIP類似度を改善。
- テキスト-to-3Dベースラインと比較して、One-2-3-45++ はより高い CLIP類似度とユーザー評価を達成し、実行時間も大幅に短く(60s 対 処理時間の数時間)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。