[論文レビュー] One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning
GLoRA は LoRA を拡張した一般化パラメータ効率的ファインチューニングフレームワークで、統一的な層単位アダプタ/プロンプトと再パラメータ化を提供し、視覚と言語タスク全体で追加推論コストなしに優れた精度を達成します。
We present Generalized LoRA (GLoRA), an advanced approach for universal parameter-efficient fine-tuning tasks. Enhancing Low-Rank Adaptation (LoRA), GLoRA employs a generalized prompt module to optimize pre-trained model weights and adjust intermediate activations, providing more flexibility and capability across diverse tasks and datasets. Moreover, GLoRA facilitates efficient parameter adaptation by employing a scalable, modular, layer-wise structure search that learns individual adapter of each layer. Originating from a unified mathematical formulation, GLoRA exhibits strong transfer learning, few-shot learning and domain generalization abilities, as it adapts to new tasks through not only weights but also additional dimensions like activations. Comprehensive experiments demonstrate that GLoRA outperforms all previous methods in natural, specialized, and structured vision benchmarks, achieving superior accuracy with fewer parameters and computations. The proposed method on LLaMA-1 and LLaMA-2 also show considerable enhancements compared to the original LoRA in the language domain. Furthermore, our structural re-parameterization design ensures that GLoRA incurs no extra inference cost, rendering it a practical solution for resource-limited applications. Code and models are available at: https://github.com/Arnav0400/ViT-Slim/tree/master/GLoRA.
研究の動機と目的
- 多様な下流データセットとモダリティに対して、パラメータ効率の良いファインチューニングを動機づける。
- ウェイト空間を超えるウェイトと特徴を調整する unified, flexible framework を開発する、LoRA を拡張する。
- 構造的再パラメータ化と層単位の進化的探索によってコスト効率の高い推論を実現する。
- 視覚ベンチマーク(VTAB-1K、ImageNetの variants)と言語モデル(LLaMA-1/2)で強みを示す。
- 従来の PEFT 手法に対する少数ショット学習、ドメイン一般化、およびロバスト性の改善を示す。)
提案手法
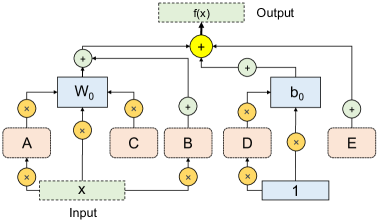
- ウェイト空間とフィーチャー空間の適応をカバーする unified な定式化 f(x) = (W0 + W0 A + B) x + (C W0 + D b0 + E + b0) を提案する。
- 柔軟な形状(LoRA、ベクター、スカラー、なし)を持つ学習可能なサポートテンソル A, B, C, D, E を導入し、可能なサブネット上のマルチパススーパネットを用意する。
- 部位ごとの層設定をスーパ-net 内で選択するために、コスト効率的かつデータ駆動的な進化的探索を用いる。
- 推論時に追加パラメータを近接する投影ウェイトへ統合するような構造的再パラメータ化を適用し、追加の FLOPs やパラメータを課さない。
- 大規模なバックボーン(ViT-B、LLaMA-1/2)上で単一のスーパーネットを訓練し、進化による検証後にタスク特異的サブネットを抽出する。
- サポートテンソルをゼロにすることで前の手法へ退化することができ、従来の PEFT 技法のスーパーセットとして機能する。
実験結果
リサーチクエスチョン
- RQ1統一的な One-for-All 形式が既存の PEFT 手法を包含し、ウェイト、特徴、プロンプト全体で柔軟な調整を提供できるか?
- RQ2層ごとに探索駆動のアダプタ設定と再パラメータ化を可能にすることで、推論コストを増やさずに転移学習、少数ショット、ドメイン一般化の性能が向上するか?
- RQ3多様なデータセットで、視覚および言語のバックボーンの両方における GLoRA の性能は、最先端の PEFT 手法と比較してどうか?
- RQ4層ごとの設定に対する進化的探索の精度と訓練時間への影響は?
- RQ5活性化とプロンプトへの調整能力を拡張しつつ、GLoRA は推論効率を維持するか?
主な発見
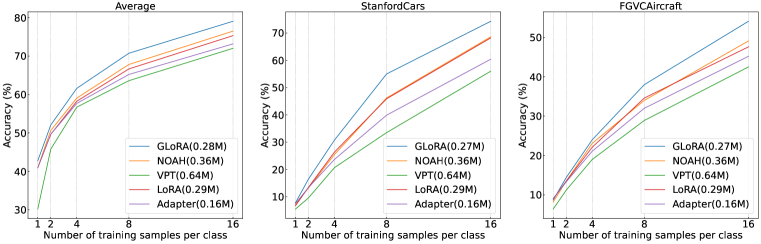
- GLoRA は VTAB-1K、ImageNet variants、言語ベンチマークで従来の PEFT 手法より優れており、平均精度が高く、学習可能パラメータが少ない。
- GLoRA は ImageNet variants や Open LLM Leaderboard タスクを含む複数のデータセットで優れた少数ショット学習とドメイン一般化を達成する。
- 構造的再パラメータ化によって追加の推論コストをゼロに維持し、多くの他の PEFT アプローチと差別化される。
- GLoRA は特定のサポートテンソルをゼロにすることで従来の手法へ退化することができ、従来の PEFT 技法のスーパーセットとして機能する。
- ViT-B および LLaMA-1/2 の実験は、視覚と言語タスクの両方で、限られた追加調整可能パラメータで一貫した利得を示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。