[論文レビュー] One-Step Effective Diffusion Network for Real-World Image Super-Resolution
OSEDiff は、事前学習済み拡散モデルと潜在空間の変分スコア蒸留を用いたワンステップ拡散フレームワークを採用し、HQ Real-ISR の結果を生成する。低品質画像から直接開始し、効率化のために LoRA で微調整する。
The pre-trained text-to-image diffusion models have been increasingly employed to tackle the real-world image super-resolution (Real-ISR) problem due to their powerful generative image priors. Most of the existing methods start from random noise to reconstruct the high-quality (HQ) image under the guidance of the given low-quality (LQ) image. While promising results have been achieved, such Real-ISR methods require multiple diffusion steps to reproduce the HQ image, increasing the computational cost. Meanwhile, the random noise introduces uncertainty in the output, which is unfriendly to image restoration tasks. To address these issues, we propose a one-step effective diffusion network, namely OSEDiff, for the Real-ISR problem. We argue that the LQ image contains rich information to restore its HQ counterpart, and hence the given LQ image can be directly taken as the starting point for diffusion, eliminating the uncertainty introduced by random noise sampling. We finetune the pre-trained diffusion network with trainable layers to adapt it to complex image degradations. To ensure that the one-step diffusion model could yield HQ Real-ISR output, we apply variational score distillation in the latent space to conduct KL-divergence regularization. As a result, our OSEDiff model can efficiently and effectively generate HQ images in just one diffusion step. Our experiments demonstrate that OSEDiff achieves comparable or even better Real-ISR results, in terms of both objective metrics and subjective evaluations, than previous diffusion model-based Real-ISR methods that require dozens or hundreds of steps. The source codes are released at https://github.com/cswry/OSEDiff.
研究の動機と目的
- Pre-trained 拡散モデルからの強力な画像 priors を活用して Real-ISR を動機づける。
- 拡散をランダムノイズではなく低品質画像から開始して、乱数性を排除し推論コストを削減する。
- 複雑な劣化に適応するために、LoRA で事前学習済み拡散モデルを微調整する。
- 潜在空間での変分スコア蒸留を用いた正規化で自然な画像分布に従う出力を促す。
- ワンステップ拡散で、比較可能または優れた結果を、はるかに少ないステップ数で達成できることを示す。
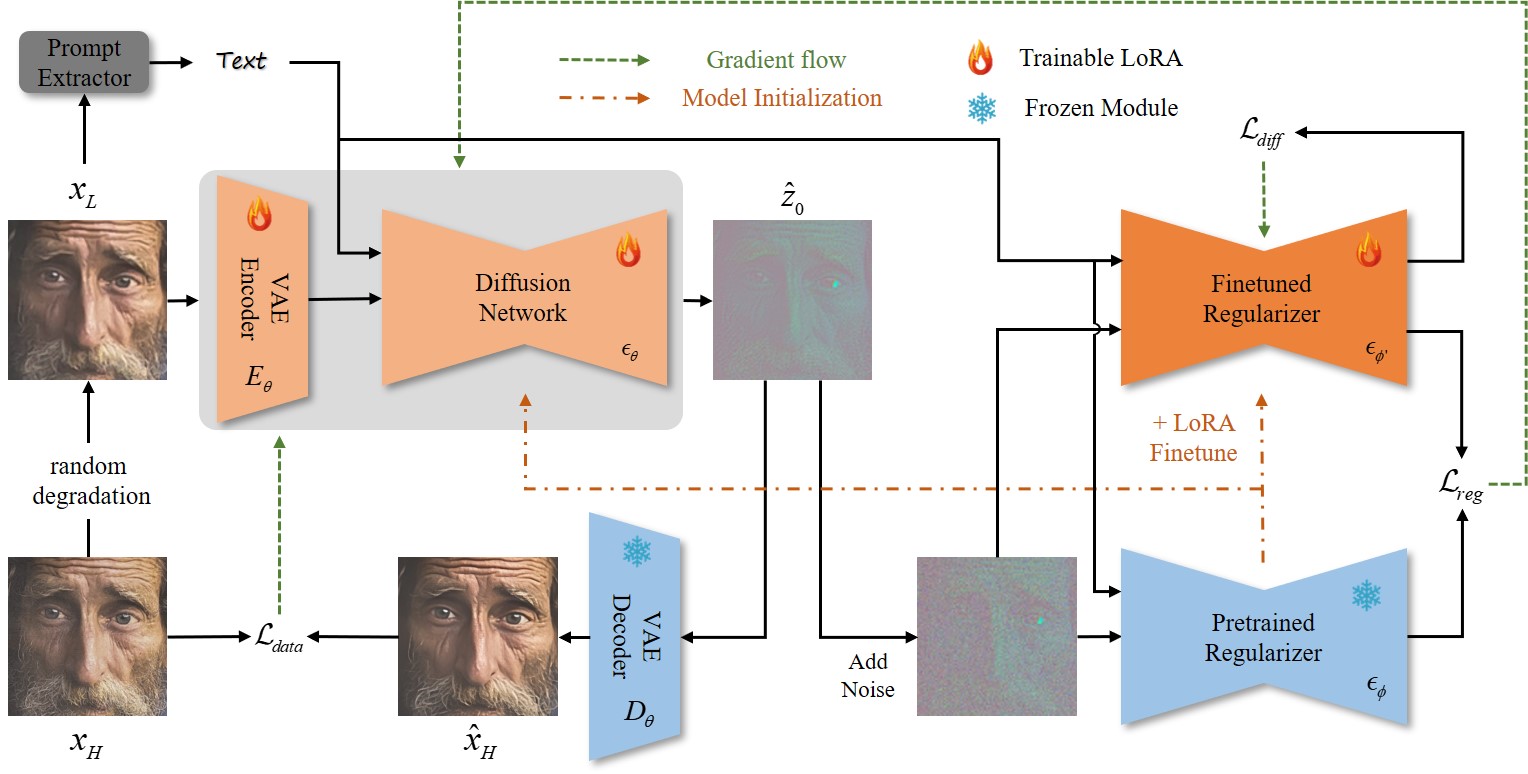
提案手法
- LQ 画像をランダムノイズを避けて開始潜在として、事前学習済み拡散モデルへ直接入力する。
- エンコーダと拡散モジュールで LoRA を用いて拡散バックボーンを微調整し、デコーダは固定のままにする。
- T ステップ目で1ステップの潜在 denoising F_theta(z_L; c_y) を計算して z_H を生成し、凍結デコーダで HQ 画像へ写像する。
- LQ 画像から劣化対応テキストプロンプトを抽出して拡散過程を条件付けする。
- 潜在空間での変分スコア蒸留(VSD)を KL ダイバージェンス正規化として適用し、微調整済み潜在正規化器を用いて出力を自然な HQ 画像分布に合わせる。
- データ項(MSE + LPIPS)と潜在 VSD 正規化項を用いて訓練し、エンコーダ、拡散、正規化モジュールを同時に最適化する。
![Figure 1: Performance and efficiency comparison among SD-based Real-ISR methods. (a). Performance comparison on the DrealSR benchmark [ 50 ] . Metrics like LPIPS and NIQE, where smaller scores indicate better image quality, are inverted and normalized for display. OSEDiff achieves leading scores on](https://ar5iv.labs.arxiv.org/html/2406.08177/assets/imgs/LD2.jpg)
実験結果
リサーチクエスチョン
- RQ1LQ 画像から開始する1ステップ拡散プロセスは、多ステップ拡散法と同等の HQ リアリズムを再現できるか。
- RQ2潜在空間の変分スコア蒸留は、Real-ISR のために事前学習済み拡散モデルを使用する際に出力を自然画像分布へ正規化するのに効果的か。
- RQ3LoRA で微調整した拡散を Real-ISR に用いる場合、モデルの効率性(訓練可能パラメータの少なさ、推論の速さ)と復元品質のトレードオフはどうなるか。
- RQ4LQ 入力からのテキストプロンプト指示は、復元 HQ 画像の品質と忠実度にどのような影響を与えるか。
- RQ5提案手法 OSEDiff は、合成データセットと実データセットの実世界劣化に対して頑健か。
主な発見
| データセット | 手法 | PSNR↑ | SSIM↑ | LPIPS↓ | DISTS↓ | FID↓ | NIQE↓ | MUSIQ↑ | MANIQA↑ | CLIPIQA↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| DIV2K-Val | StableSR-s200 | 23.26 | 0.5726 | 0.3113 | 0.2048 | 24.44 | 4.7581 | 65.92 | 0.6192 | 0.6771 |
| DIV2K-Val | DiffBIR-s50 | 23.64 | 0.5647 | 0.3524 | 0.2128 | 30.72 | 4.7042 | 65.81 | 0.6210 | 0.6704 |
| DIV2K-Val | SeeSR-s50 | 23.68 | 0.6043 | 0.3194 | 0.1968 | 25.90 | 4.8102 | 68.67 | 0.6240 | 0.6936 |
| DIV2K-Val | PASD-s20 | 23.14 | 0.5505 | 0.3571 | 0.2207 | 29.20 | 4.3617 | 68.95 | 0.6483 | 0.6788 |
| DIV2K-Val | ResShift-s15 | 24.65 | 0.6181 | 0.3349 | 0.2213 | 36.11 | 6.8212 | 61.09 | 0.5454 | 0.6071 |
| DIV2K-Val | SinSR-s1 | 24.41 | 0.6018 | 0.3240 | 0.2066 | 35.57 | 6.0159 | 62.82 | 0.5386 | 0.6471 |
| DIV2K-Val | OSEDiff-s1 | 23.72 | 0.6108 | 0.2941 | 0.1976 | 26.32 | 4.7097 | 67.97 | 0.6148 | 0.6683 |
| DrealSR | StableSR-s200 | 28.03 | 0.7536 | 0.3284 | 0.2269 | 148.98 | 6.5239 | 58.51 | 0.5601 | 0.6356 |
| DrealSR | DiffBIR-s50 | 26.71 | 0.6571 | 0.4557 | 0.2748 | 166.79 | 6.3124 | 61.07 | 0.5930 | 0.6395 |
| DrealSR | SeeSR-s50 | 28.17 | 0.7691 | 0.3189 | 0.2315 | 147.39 | 6.3967 | 64.93 | 0.6042 | 0.6804 |
| DrealSR | PASD-s20 | 27.36 | 0.7073 | 0.3760 | 0.2531 | 156.13 | 5.5474 | 64.87 | 0.6169 | 0.6808 |
| DrealSR | ResShift-s15 | 28.46 | 0.7673 | 0.4006 | 0.2656 | 172.26 | 8.1249 | 50.60 | 0.4586 | 0.5342 |
| DrealSR | SinSR-s1 | 28.36 | 0.7515 | 0.3665 | 0.2485 | 170.57 | 6.9907 | 55.33 | 0.4884 | 0.6383 |
| DrealSR | OSEDiff-s1 | 27.92 | 0.7835 | 0.2968 | 0.2165 | 135.30 | 6.4902 | 64.65 | 0.5899 | 0.6963 |
| RealSR | StableSR-s200 | 24.70 | 0.7085 | 0.3018 | 0.2288 | 128.51 | 5.9122 | 65.78 | 0.6221 | 0.6178 |
| RealSR | DiffBIR-s50 | 24.75 | 0.6567 | 0.3636 | 0.2312 | 128.99 | 5.5346 | 64.98 | 0.6246 | 0.6463 |
| RealSR | SeeSR-s50 | 25.18 | 0.7216 | 0.3009 | 0.2223 | 125.55 | 5.4081 | 69.77 | 0.6442 | 0.6612 |
| RealSR | PASD-s20 | 25.21 | 0.6798 | 0.3380 | 0.2260 | 124.29 | 5.4137 | 68.75 | 0.6487 | 0.6620 |
| RealSR | ResShift-s15 | 26.31 | 0.7421 | 0.3460 | 0.2498 | 141.71 | 7.2635 | 58.43 | 0.5285 | 0.5444 |
| RealSR | SinSR-s1 | 26.28 | 0.7347 | 0.3188 | 0.2353 | 135.93 | 6.2872 | 60.80 | 0.5385 | 0.6122 |
| RealSR | OSEDiff-s1 | 25.15 | 0.7341 | 0.2921 | 0.2128 | 123.49 | 5.6476 | 69.09 | 0.6326 | 0.6693 |
- 1ステップの拡散で OSEDiff は、多ステップ拡散法と比較して知覚的および分布的指標が競合または優れている。
- OSEDiff は LQ 入力を拡散開始点として使用することで、乱数性と推論コストを低減しつつ HQ のディテール品質を維持する。
- 潜在空間 VSD 正規化は自然 HQ 画像との分布整合性を改善し、画像空間や敵対的代替案よりもいくつかの指標で優れる。
- ベースラインと比較して Real-ISR ベンチマークと実データで LPIPS、DISTS、FID、CLIPIQA 指標が高性能を示す。
- OSEDiff は報告された拡散ベース Real-ISR 手法の中で最小の訓練可能パラメータ数(LoRA ベース微調整)で大幅な推論スピードアップを達成する。
- LQ 画像からのテキストプロンプト抽出(DAPE または LLaVA ベースのプロンプト)は生成能力を高める一方で、プロンプトの種類次第では全参照指標に影響を与える可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。