[論文レビュー] Online Decision Transformer
オンライン意思決定トランスフォーマー(ODT)は、最大エントロピー系列モデリング目的と hindsight 帰還リラベリングを用いてオフライン事前学習とオンライン微調整を組み合わせ、D4RLでの絶対性能を競合させ、微調整時に顕著な gains を達成します。
Recent work has shown that offline reinforcement learning (RL) can be formulated as a sequence modeling problem (Chen et al., 2021; Janner et al., 2021) and solved via approaches similar to large-scale language modeling. However, any practical instantiation of RL also involves an online component, where policies pretrained on passive offline datasets are finetuned via taskspecific interactions with the environment. We propose Online Decision Transformers (ODT), an RL algorithm based on sequence modeling that blends offline pretraining with online finetuning in a unified framework. Our framework uses sequence-level entropy regularizers in conjunction with autoregressive modeling objectives for sample-efficient exploration and finetuning. Empirically, we show that ODT is competitive with the state-of-the-art in absolute performance on the D4RL benchmark but shows much more significant gains during the finetuning procedure.
研究の動機と目的
- オフラインデータ事前学習とオンライン環境微調整を組み合わせることにより、サンプル効率の高い強化学習を動機づけ、実現します。
- 探索に適した確率的ポリシーへ拡張するため、Decision Transformerフレームワークを展開します。
- エントロピー正則化された軌跡レベルの探索と、オンライン学習に適合したリプレイバッファを導入します。
- オンラインローアウトを望ましいリターントークンと一致させるため、 hindsight return relabeling を組み込みます。
提案手法
- ポリシーを、過去Kタイムステップの状態、RTG、アクションから行動を予測する確率的リターン条件付きトランスフォーマー(ODT)としてモデル化します。
- 負対数尤度を軌跡レベルのエントロピー項で正則化する最大エントロピー目的を用い、λパラメータを持つ双対定式化で解きます。
- 観測されたリターンにより良く適合させるため、全軌跡を格納する軌跡中心のリプレイバッファを用いて、RTGトークンを hindsight return relabeling によりリラベリングします。
- 初期のオンラインRTGトークンを持つリターン条件付きトレーニングを採用し、オンラインローアウトを用いてリプレイバッファを充填します。
- Hindsight Return Relabeling を用いて、ローアウト終了時に得られたリターンでRTGトークンを置換し、 sparse/dense報酬設定でサンプル効率を向上させます。
- オンラインデータが支配的になるにつれて、目的関数がオフラインデータに対するクロスエントロピーから標準のNLLへ移行する収束の直感を説明します。
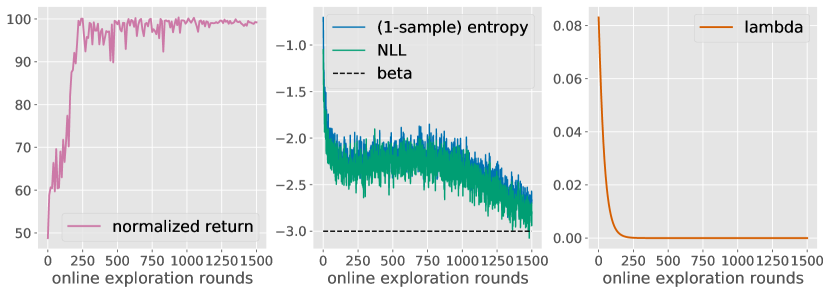
実験結果
リサーチクエスチョン
- RQ1オフライン事前学習 via a Decision Transformer をオンライン微調整 with exploration に効果的に拡張できるか。
- RQ2軌跡レベルのエントロピー正則化はオンライン微調整中の探索とサンプル効率を改善するか。
- RQ3 hindsight return relabeling は return-conditioned ポリシーとオンライン学習をどのように相互作用させるか。
- RQ4ODT は D4RL ベンチマークの最新のオフラインおよびオンラインRLベースラインに対してどのように性能を示すか。
- RQ5Transformer を用いたオフラインからオンラインへの RL における成功のための必須要素を示すアブレーションは何か。
主な発見
- ODT は D4RL ベンチマークの絶対性能で最先端メソッドと競合的である。
- ODT はオフラインベースラインと比較して、微調整/オンライン段階で著しく大きな向上を示す。
- エントロピー正則化トレーニングと軌跡レベルの探索は、リターン条件付きポリシーのオンライン微調整を効果的に可能にする。
- Hindsight return relabeling は、希薄および密な報酬環境におけるオンラインローアウトのデータ効率を改善する。
- ODT の利点は、オンライン探索とオフライン事前学習をエンドツーエンドで統合する点にあり、オンライン段階の大規模なハイパーパラメータ調整を必要としない。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。