[論文レビュー] Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
本論文は、RLHFの人間のフィードバック、報酬モデリング、ポリシー最適化に跨る未解決の問題と根本的な限界を概説し、より広い安全性とガバナンスの含意について論じている。
Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
研究の動機と目的
- RLHFの人間のフィードバック、報酬モデリング、ポリシー最適化の全分野にわたる具体的な課題を分類・体系化する。
- 対処可能な問題と、RLHF以外のアプローチを必要とする根本的な制約を区別する。
- RLHFをより広い安全性フレームワークとガバナンスの観点に統合することを論じる。
提案手法
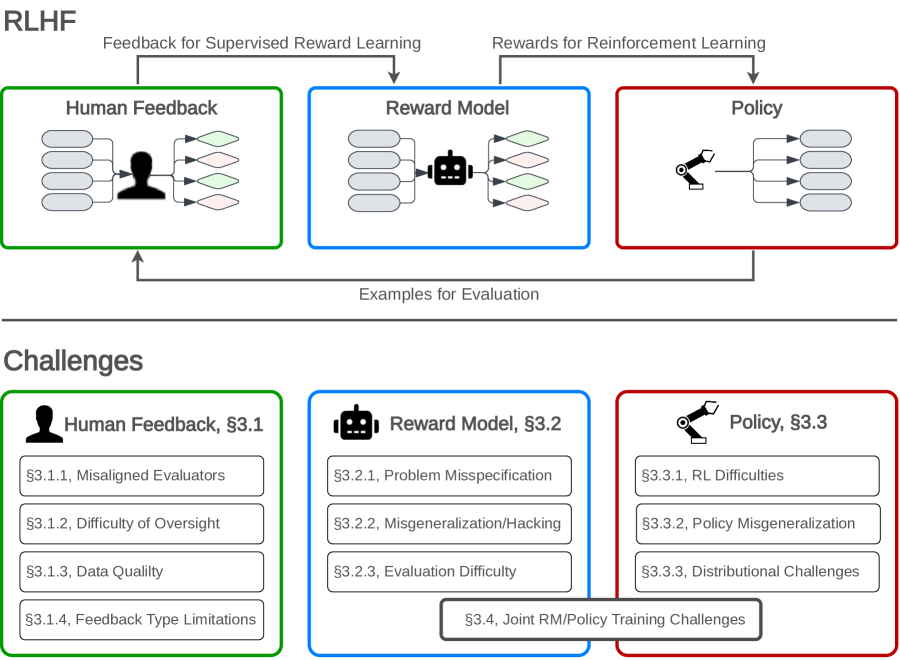
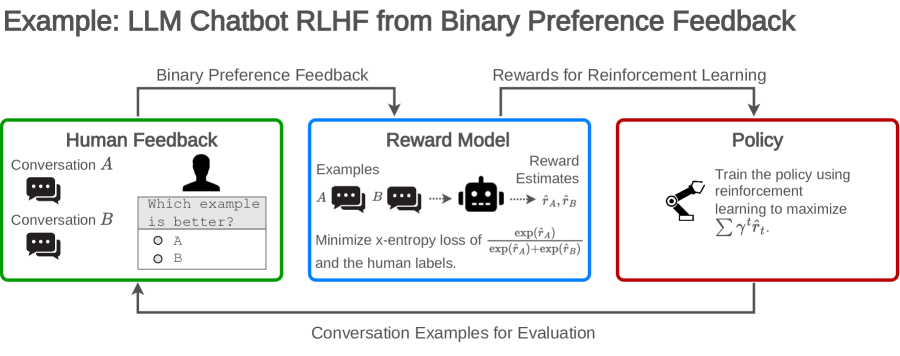
- 既存のRLHFの課題を、フィードバック収集、報酬モデリング、ポリシー最適化の3つの主要領域に分類・整理する。
- 根本的な制約と対処可能な改善を要約し、区分は付録Bで説明する。
- RLHFに焦点を当てたアプローチが、より広い安全性と監視戦略の中でどう適合するかを総合する。
実験結果
リサーチクエスチョン
- RQ1RLHFにおける主な課題のカテゴリーは何か(フィードバック、報酬モデル、ポリシー)そしてRLHF内で根本的か対処可能かはどれか?
- RQ2RLHFを追加の安全対策とガバナンス実践で補完して社会的な監視を向上させるにはどうすればよいか?
- RQ3RLHFの導入における、人間の齟齬、データ品質、報酬ハッキングの影響は何か?
- RQ4RLHFシステムの透明性と説明責任を向上させる監査および開示基準とは何か?
主な発見
- RLHFは、フィードバック収集、報酬モデリング、ポリシー最適化の段階で課題に直面している。
- 多くの制約は根本的なものであり、克服するにはRLHFを超えるアプローチが必要である。
- 監督、データ品質、評価の複雑さは、齟齬、偏り、操作といった継続的なリスクをもたらす。
- RLHFは単一の整合性手段として頼るのではなく、複数層の安全性フレームワークに組み込むべきである。
- RLHFベースのシステムの説明責任を向上させるガバナンスと透明性の検討事項がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。