[論文レビュー] Open-Source LLMs for Text Annotation: A Practical Guide for Model Setting and Fine-Tuning
本研究は、オープンソースLLM(HuggingChat、FLAN)をChatGPTおよびMTurkと比較し、11のテキスト注釈タスクでゼロショットおよび少数ショット設定を異なる温度で検討し、オープンソースLLMが多くの場合MTurkを上回り、ChatGPTに近づく可能性があることを示しています。
This paper studies the performance of open-source Large Language Models (LLMs) in text classification tasks typical for political science research. By examining tasks like stance, topic, and relevance classification, we aim to guide scholars in making informed decisions about their use of LLMs for text analysis. Specifically, we conduct an assessment of both zero-shot and fine-tuned LLMs across a range of text annotation tasks using news articles and tweets datasets. Our analysis shows that fine-tuning improves the performance of open-source LLMs, allowing them to match or even surpass zero-shot GPT-3.5 and GPT-4, though still lagging behind fine-tuned GPT-3.5. We further establish that fine-tuning is preferable to few-shot training with a relatively modest quantity of annotated text. Our findings show that fine-tuned open-source LLMs can be effectively deployed in a broad spectrum of text annotation applications. We provide a Python notebook facilitating the application of LLMs in text annotation for other researchers.
研究の動機と目的
- オープンソースLLM(HuggingChat、FLAN)をChatGPTおよびMTurkと比較して、複数のテキスト注釈タスクで評価する。
- ゼロショットおよび少数ショット学習を、異なる温度設定で調査する。
- モデルサイズとプロンプトが注釈精度とインコーダ間の同意に与える影響を examineする。
- オープンソースLLMの実用的な側面:コスト、データ保護、再現性を評価する。
- テキスト注釈タスクにおけるモデル設定の選択に関するガイダンスを提供する。
提案手法
- ChatGPT、HuggingChat、FLANを4つのデータセットで11の注釈タスクにわたり比較する。
- ChatGPTとHuggingChatをゼロショットおよび複数の温度設定でテストする;FLANはL/XL/XXLサイズでゼロショットを tested。
- 設定ごとに2回の実行を行いインコーダ間の合意を算出する。
- 各クラスにつき2つの人間注釈付き例を用いたChain-of-Thought(CoT)による少数ショットプロンプティングを適用する。
- 訓練済み注釈者および MTurkを金標準として、正確性を測定する。
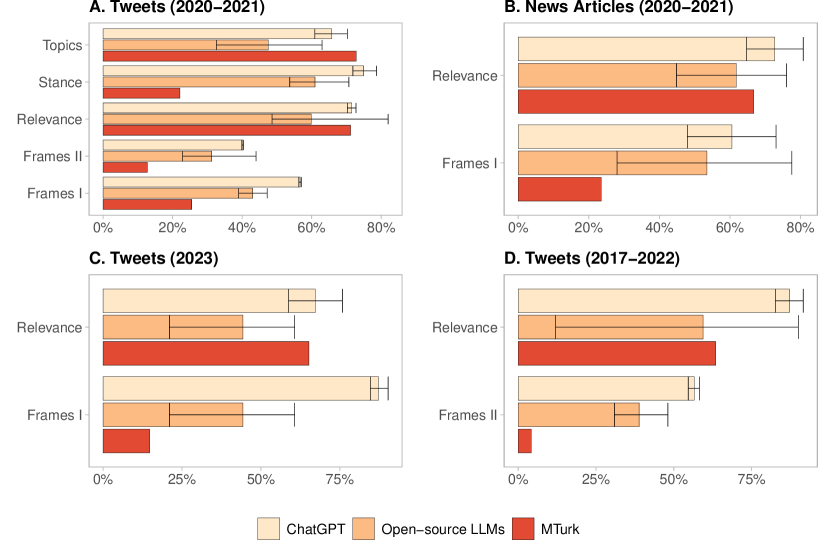
実験結果
リサーチクエスチョン
- RQ1オープンソースLLMはクラウドワーカーを上回り、テキスト注釈タスクでChatGPTに近づくのか。
- RQ2ゼロショットと少数ショットのプロンプティングおよび温度設定が、タスク全体の性能にどのように影響するのか。
- RQ3オープンソースLLMを注釈に用いる際のコストとデータ保護上の影響は、専有モデルおよびMTurkと比較してどうなるのか。
- RQ4インコーダ間の合意によって、モデル出力は人間の注釈者とどれくらい一貫しているのか。
主な発見
- ChatGPTは通常、タスク全体の平均精度で最高値を達成する。
- オープンソースLLMは大半のタスクでMTurkを凌駕し、上位モデルではいくつかのタスクでChatGPTを上回ることがある。
- トップ性能のオープンソースLLMは11タスク中9タスクでMTurkを上回り、いくつかのタスクでChatGPTに近づく。
- パフォーマンスはデータセットとタスクによって異なり、モデル全体で最適化される単一の設定は存在しない。
- 低温度設定はHuggingChatの性能を向上させることが多い一方、FLANの大規模サイズが必ずしもより良い結果を保証するわけではない(FLANはゼロショットのみで検証)。
- オープンソースLLMはコスト面で大きな利点(無料で使用可能)とデータ保護の強化(第三者データ共有なし)を提供する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。