[論文レビュー] Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models
ODISE は凍結されたテキスト-to-画像拡散モデルの表現と識別モデルを活用し、オープンベクトルパノプティックセグメンテーションを実行し、オープンベクトルパノプティックおよびセマンティックセグメンテーションのベンチマークで最先端の結果を達成します。
We present ODISE: Open-vocabulary DIffusion-based panoptic SEgmentation, which unifies pre-trained text-image diffusion and discriminative models to perform open-vocabulary panoptic segmentation. Text-to-image diffusion models have the remarkable ability to generate high-quality images with diverse open-vocabulary language descriptions. This demonstrates that their internal representation space is highly correlated with open concepts in the real world. Text-image discriminative models like CLIP, on the other hand, are good at classifying images into open-vocabulary labels. We leverage the frozen internal representations of both these models to perform panoptic segmentation of any category in the wild. Our approach outperforms the previous state of the art by significant margins on both open-vocabulary panoptic and semantic segmentation tasks. In particular, with COCO training only, our method achieves 23.4 PQ and 30.0 mIoU on the ADE20K dataset, with 8.3 PQ and 7.9 mIoU absolute improvement over the previous state of the art. We open-source our code and models at https://github.com/NVlabs/ODISE .
研究の動機と目的
- Bridge open-vocabulary recognition with panoptic segmentation by leveraging diffusion-model representations.
- Unify pre-trained text-to-image diffusion features with discriminative models for open-category labeling.
- Train a mask generator and an open-vocabulary classifier using either category labels or image captions.
- Demonstrate state-of-the-art performance on open-vocabulary panoptic and semantic segmentation benchmarks.
提案手法
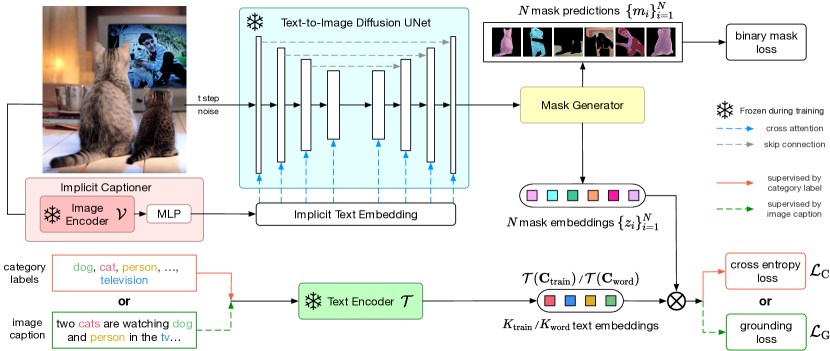
- Extract diffusion-model features from a frozen text-to-image diffusion UNet using an implicit captioner to produce an image-conditioned feature map.
- Train a mask generator to predict class-agnostic binary masks and corresponding mask embeddings from diffusion features.
- Classify each mask by computing similarities between mask embeddings and text embeddings of training category names or nouns from image captions, using a cross-entropy or grounding loss.
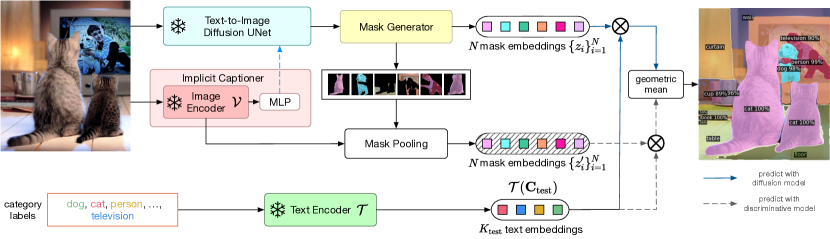
- During inference, generate masks with ODISE and fuse diffusion-model predictions with a discriminative-model (CLIP) predictions via a geometric mean to obtain final open-vocabulary labels.
実験結果
リサーチクエスチョン
- RQ1Can open-vocabulary panoptic segmentation be effectively learned by exploiting the internal representations of large-scale text-to-image diffusion models?
- RQ2Does combining diffusion-based features with discriminative text-image models yield superior open-vocabulary segmentation performance?
- RQ3How should implicit captions be constructed to maximize diffusion-model feature quality when captions are unavailable at test time?
- RQ4What are the trade-offs between caption supervision and caption-free methods for open-vocabulary segmentation?
主な発見
| 手法 | データセット | PQ | mAP | mIoU |
|---|---|---|---|---|
| MaskCLIP | ADE20K | 15.1 | 6.0 | 23.7 |
| ODISE (Ours) | ADE20K (label+mask) | 22.6 | 14.4 | 29.9 |
| ODISE (Ours) | COCO (label+mask) | 55.4 | 46.0 | 65.2 |
| ODISE (Ours) | ADE20K (caption) | 23.4 | 13.9 | 28.7 |
| ODISE (Ours) | COCO (caption) | 45.6 | 38.4 | 52.4 |
- ODISE achieves state-of-the-art results on open-vocabulary panoptic segmentation, notably 23.4 PQ and 28.7–29.9 mIoU on ADE20K and 55.4 PQ / 65.2 mIoU on COCO under different supervision settings.
- Using label+mask supervision yields higher ADE20K PQ (22.6) and mIoU (29.9) than caption supervision (23.4 PQ, 28.7 mIoU) in the reported setup; COCO results remain strong (55.4 PQ, 65.2 mIoU).
- ODISE outperforms MaskCLIP by 8.3 PQ on ADE20K for open-vocabulary panoptic segmentation.
- Open-vocabulary semantic segmentation benefits substantially, with improvements of multiple mIoU points across A-150, A-847, and PC-459 datasets under both caption and label supervision.
- A compact model (28.1M trainable parameters, 1.8% of the full model) with 1,493.8M frozen parameters achieves 1.26 FPS on 1024^2 images on V100, with 11.9 GB memory.
- Fusion of diffusion-based and discriminative model predictions (geometric mean) yields better results than either alone across evaluated datasets.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。