[論文レビュー] OpenAssistant Conversations -- Democratizing Large Language Model Alignment
本論文は OpenAssistant Conversations を公開し、大規模で多言語の人間生成データセットを提供して LLM の整合性を向上させ、オープンアーキテクチャ上で SFT、RM、RLHF モデルを訓練・評価することの有用性を示します。
Aligning large language models (LLMs) with human preferences has proven to drastically improve usability and has driven rapid adoption as demonstrated by ChatGPT. Alignment techniques such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) greatly reduce the required skill and domain knowledge to effectively harness the capabilities of LLMs, increasing their accessibility and utility across various domains. However, state-of-the-art alignment techniques like RLHF rely on high-quality human feedback data, which is expensive to create and often remains proprietary. In an effort to democratize research on large-scale alignment, we release OpenAssistant Conversations, a human-generated, human-annotated assistant-style conversation corpus consisting of 161,443 messages in 35 different languages, annotated with 461,292 quality ratings, resulting in over 10,000 complete and fully annotated conversation trees. The corpus is a product of a worldwide crowd-sourcing effort involving over 13,500 volunteers. Models trained on OpenAssistant Conversations show consistent improvements on standard benchmarks over respective base models. We release our code and data under a fully permissive licence.
研究の動機と目的
- 高品質な人間のフィードバックデータへアクセスを民主化するため、巨大でオープンなデータセットを公開する。
- データセットの安全性、倫理、モデレーションの影響を評価する。
- このデータセットの有用性を、オープンなアーキテクチャ上で SFT、報酬モデル、及び RLHF ベースのモデルの訓練・評価によって実証する。
提案手法
- 161,443 件のメッセージ、66,497 本のツリー、35 言語、461,292 件の品質評価を含む OpenAssistant Conversations データセットを公開。
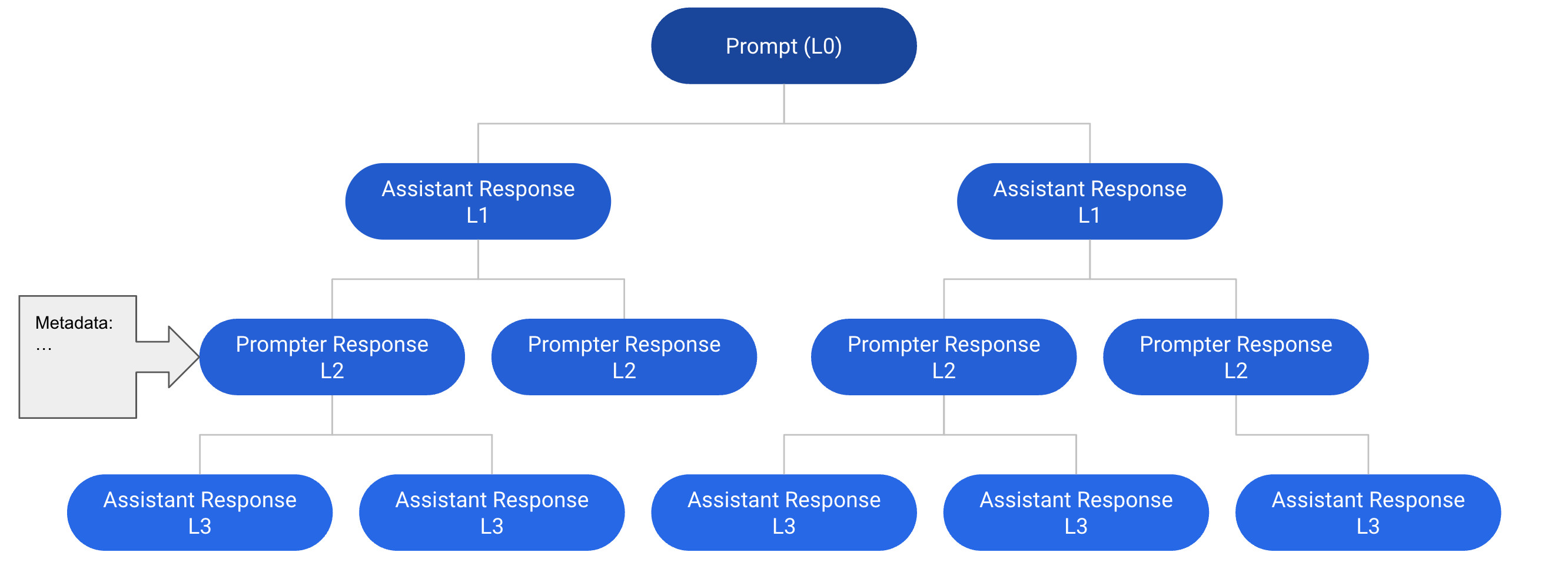
- クラウドソーシングによるデータ収集を、5 種類のタスクで実施:プロンプト作成、アシスタントとしての応答、プロンプターとしての応答、ラベリング、ランキング。
- ツリー状態機械が会話ツリーの作成・成長・完了を支配;報酬、リーダーボード、人間の審査によるモデレーションと品質管理。
- Pythia、Falcon、LLaMA などの公開モデル上で SFT モデル、報酬モデル(RM)、RLHF モデルを訓練;標準ベンチマークで評価。
- ベースラインと比較して、OpenAssistant Conversations を活用したモデルは複数のベンチマークで一部のベースラインより優れていることを示す。
実験結果
リサーチクエスチョン
- RQ1大規模でオープンな人間注釈付き会話データセットは、LLM の整合性に基づくファインチューニングの改善を誘発できるか。
- RQ2OpenAssistant Conversations で訓練された SFT、RM、RLHF モデルは、標準的な NLP ベンチマークでベースラインと比較してどのように性能を示すか。
- RQ3このようなデータセットの安全性、毒性、モデレーションの特徴は何か、 automated toxicity measures は人間の判断とどれほど一致するか。
- RQ4ボランティア主導のオープンデータセット収集プロセスから生じる偏りや制約は何か、これらがモデルの挙動にどのように影響するか。
- RQ5再現性と責任ある研究を最大化するには、データとモデルをどのように公開すべきか。
主な発見
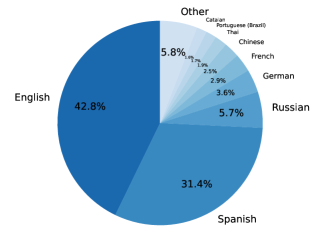
- OpenAssistant Conversations には 161,443 件のメッセージ(91,829 のプロンプター;69,614 のアシスタント)と 66,497 本のツリー、35 言語、461,292 件の品質評価が含まれる。
- このデータで訓練されたモデルは、標準ベンチマークでそれぞれの元のモデルより一貫して改善を示した。
- RLHF は SFT に比べていくつかのベンチマークを改善するが、すべてのタスクで一様ではなく、データと評価のニュアンスを示唆している。
- 自動的な毒性測定(Detoxify)は人間のラベルと一定の相関があり、モデレーションは有害な内容を大幅に減らす一方、非有害なメッセージが他の理由で削除されることもある。
- データセットとモデルは寛容なライセンスの下で公開され、オープン研究を可能にする一方で偏りと安全性の考慮事項を認識している。
- ユーザー調査と人口統計分析は、寄稿者の一部の次元での均一性と、不均一な参加による潜在的な偏りを明らかにした。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。